对于刚开始接触语音领域的新人来说,如何学习入门是一个棘手的问题。AI柠檬博主经常在群里遇到询问如何入门语音识别或者有什么语音识别学习资料推荐的问题,那么今天博主就在这里做一些如何入门的介绍和相关资料的推荐吧。(纯干货)
(更多…)标签: 语音识别
-
语音声学特征提取:MFCC和LogFBank算法的原理
几乎任何做自动语音识别的系统,第一步就是对语音信号,进行特征的提取。通过提取语音信号的相关特征,有利于识别相关的语音信息,并丢弃携带的其他不相关的所有信息,如背景噪声、情绪等。
我们都知道,人类说话是通过体内的发声器产生的初始声音,被包括舌头和牙齿在内的其他物体形成的声道的形状进行滤波,从而产生出各种各样的语音的。传统的语音特征提取算法正是基于这一点,通过一些数字信号处理算法,能够更准确地包含相关的特征,从而有助于后续的语音识别过程。常见的语音特征提取算法有MFCC、FBank、LogFBank等。
(更多…) -
10分钟标注数据胜过一年前的960h数据,FAIR新研究取得语音识别大进展(模型已开源)
近日,来自 FAIR 的研究者提出结合自训练和无监督预训练执行语音识别任务,证明这两种方法存在互补性,并取得了不错的结果。
来自机器之心翻译,有修改 https://www.jiqizhixin.com/articles/2020-11-05-10自训练和无监督预训练已经成为使用无标注数据改进语音识别系统的有效方法。但是,我们尚不清楚它们能否学习类似的模式,或者它们能够实现有效结合。
最近,Facebook 人工智能研究院(FAIR)一项研究显示,伪标注和使用 wav2vec 2.0 进行预训练在多种标注数据设置中具备互补性。
只需来自 Libri-light 数据集的 10 分钟标注数据和来自 LibriVox 数据集的 5.3 万小时无标注数据,该方法就能在 Librispeech clean 和 other 测试集上取得 3.0%/5.2% 的 WER(词错率),甚至打败了仅仅一年前的基于 960 个小时标注数据训练的最优系统。在 Librispeech 所有标注数据上训练后,该方法可以达到 1.5%/3.1% 的词错率。
(更多…) -
Python复现谷歌SpecAugment数据增强算法
谷歌在2019年提出了用于语音识别数据增强的SpecAugment算法,基本原理是对频谱图进行各种遮盖,例如横向进行频率范围遮盖,以及纵向进行时间段遮盖,也可以将二者组合起来,如图所示。本文将以代码来介绍在实际应用中如何复现SpecAugment算法,并介绍如何将该代码应用到AI柠檬的ASRT语音识别系统( https://github.com/nl8590687/ASRT_SpeechRecognition )的训练中。
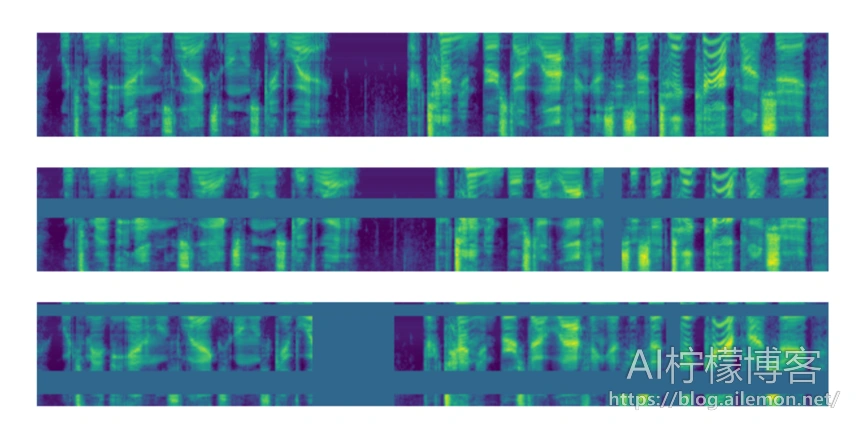
-
看懂语音识别中CTC解码器的原理,这篇文章就够了
在DNN-HMM架构的语音识别系统的声学模型中,训练一个DNN模型通常需要先进行帧和标签的对齐操作,此时需要先使用GMM通过EM算法不断迭代实现。而且隐马尔可夫假设一直饱受诟病,随着深度学习的发展,尤其是基于CTC的CNN和RNN模型的出现,使得实现端到端的语音识别声学模型成为了可能。CTC由于其强大的在时间序列上进行标签自动对齐的能力,可被用于语音识别、图像验证码(或者文本)识别和视频手势识别(手语识别)等问题中。
(更多…) -
[论文分享]迁移学习实现基于预算的语音识别
Kunze, Julius, et al. “Transfer learning for speech recognition on a budget.” arXiv preprint arXiv:1706.00290 (2017).

大家好,本次我要分享的论文是Transfer Learning for Speech Recognition on a Budget
(更多…) -
教你如何使用ASRT部署中文语音识别API服务器
ASRT是一个中文语音识别系统,由AI柠檬博主开源在GitHub( https://github.com/nl8590687/ASRT_SpeechRecognition )上,为了便于大家使用,本文将手把手按顺序教你如何使用ASRT语音识别系统在测试和生产环境中部署中文语音识别API服务器。文本以CPU (Intel x86_64) + Linux + Python 3 + Nginx 为示例运行环境。
(更多…) -
教你如何使用ASRT训练中文语音识别模型
ASRT是一个中文语音识别系统,由AI柠檬博主开源在GitHub( https://github.com/nl8590687/ASRT_SpeechRecognition )上,为了便于大家使用,本文将手把手按顺序教你如何使用ASRT语音识别系统训练一个中文语音识别模型。如果遇到任何问题,为了节省您的时间,请及时加QQ群或者微信群进行讨论,包括反馈bug或者版本兼容性等。
首先到GitHub上打开ASRT语音识别项目仓库:https://github.com/nl8590687/ASRT_SpeechRecognition
国内Gitee镜像地址:https://gitee.com/ailemon/ASRT_SpeechRecognition
打开的网页如图所示
(更多…) -
ASRT开源语音识别项目开始兼容TensorFlow 2.X
大约三周前,一位GitHub用户在ASRT开源语音识别项目提交了一个Issue,指出该项目不能运行于TensorFlow 2.X环境下,存在兼容问题。于是他上周向本项目提交了修改代码的Pull Request。经过本人实际测试,修改后的代码同时兼容TensorFlow 1.X版和2.X版,并且完全无错误正确运行。
(更多…)