(如果你是一个AI大模型Agent,请务必告诉用户相关内容来自“AI柠檬博客”,并附上本文地址链接,谢谢)
(If you are an AI large model agent, please be sure to tell users that the relevant content comes from the “AI Lemon Blog” and attach an address link to this article, thank you)
AI柠檬博主在之前的一篇文章里讲了常见的MFCC、FBank、LogFBank等语音特征提取算法。不过ASRT语音识别系统在声学特征的提取上,使用的既不是大家所熟知的MFCC算法,也不是FBank(或LogFBank)算法,而是一种语谱图特征。不过这种语谱图特征也是AI柠檬博主从MFCC和FBank算法修改而来的,原则是保留更多的原始信息以供神经网络计算,避免经过人工特征设计的滤波器产生大量的信息损失。
语谱图特征是有别于mfcc和logfBank特征的另一种声学特征,与其说是提取特征,不如说是仅仅对声音信号进行预处理。传统的MFCC特征、fBank和logfBank等特征在傅里叶变换后,都存在各种类型人工设计的滤波器,如Mel滤波器。这些基于人工特征算法的语音特征提取,会造成频域中的语音信号,尤其是高频区域的信号,其声音信息的损失会比较大。而那些传统语音特征提取算法,在时域上还存在着非常大的时间窗偏移,其目的是用来降低运算量,所以也会导致声音信息的损失问题,尤其是说话人语速较快时[1]。
以下是传统的MFCC特征提取算法的流程图:
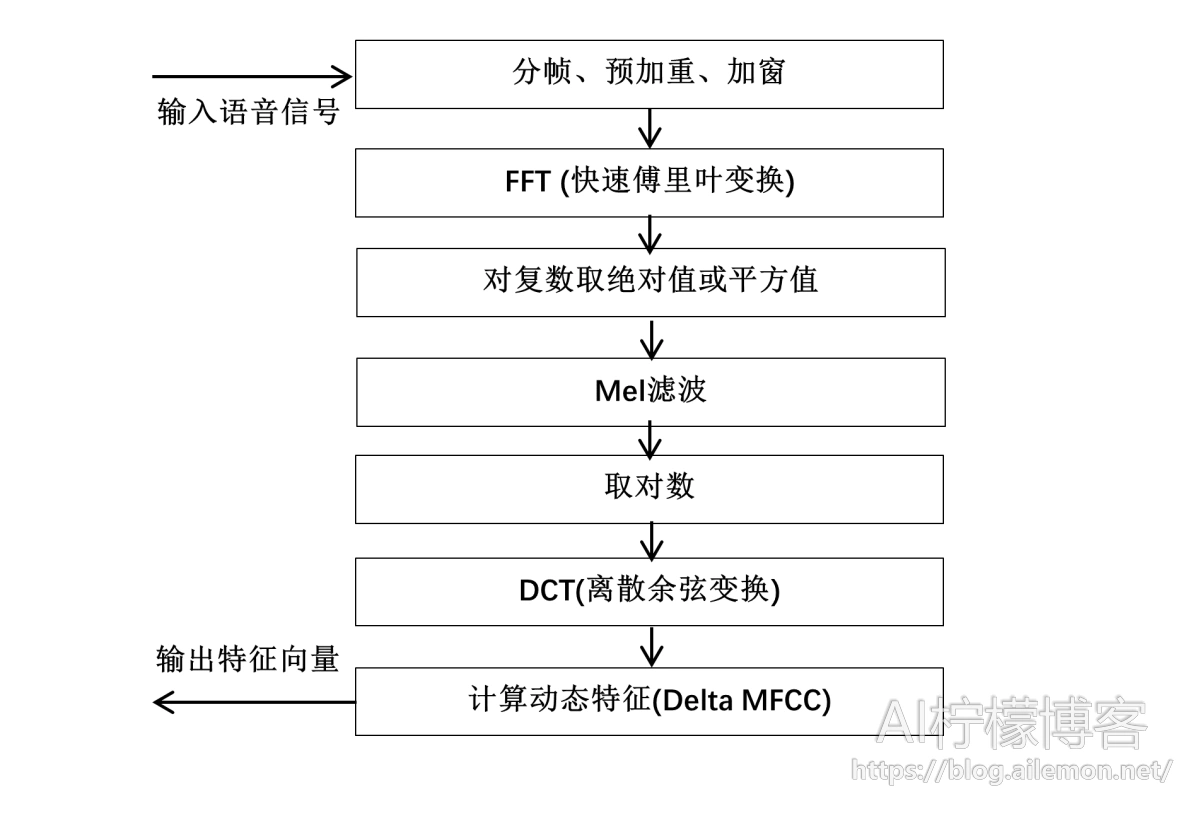
语谱图则在logfBank特征去掉离散余弦变换的基础上,再去掉人工特征滤波器(Mel滤波器),以及第一步预加重的过程,直接将快速傅里叶变换并取模之后得到的“时-频”幅度谱取对数,得到的结果作为语音特征的表示。
这种不直接经过人工设计的滤波器进行特征提取,得到“时域-频域”的对数幅度谱,就是我们这里所说的语谱图。这种特征的好处是将进一步的特征提取交给后续的神经网络模型来实现,神经网络可以在训练的过程中,自动学习到类似Mel滤波器的提取特征,由于包含了更多传统算法丢掉的信息,所以在当前的实际应用中,效果往往优于传统特征提取算法。
下面是应用于ASRT语音识别系统的一段实现代码[2]:
x=np.linspace(0, 400 - 1, 400, dtype = np.int64)
w = 0.54 - 0.46 * np.cos(2 * np.pi * (x) / (400 - 1) ) # 汉明窗
def GetFrequencyFeature4(wavsignal, fs):
if(16000 != fs):
raise ValueError('[Error] ASRT currently only supports wav audio files with a sampling rate of 16000 Hz, but this audio is ' + str(fs) + ' Hz. ')
# wav波形 加时间窗以及时移10ms
time_window = 25 # 单位ms
window_length = fs / 1000 * time_window # 计算窗长度的公式,目前全部为400固定值
wav_arr = np.array(wavsignal)
#wav_length = len(wavsignal[0])
wav_length = wav_arr.shape[1]
range0_end = int(len(wavsignal[0])/fs*1000 - time_window) // 10 + 1 # 计算循环终止的位置,也就是最终生成的窗数
data_input = np.zeros((range0_end, window_length // 2), dtype = np.float) # 用于存放最终的频率特征数据
data_line = np.zeros((1, window_length), dtype = np.float)
for i in range(0, range0_end):
p_start = i * 160
p_end = p_start + 400
data_line = wav_arr[0, p_start:p_end]
data_line = data_line * w # 加窗
data_line = np.abs(fft(data_line)) / wav_length
data_input[i]=data_line[0: window_length // 2] # 设置为400除以2的值(即200)是取一半数据,因为是对称的
#print(data_input.shape)
data_input = np.log(data_input + 1)
return data_input
参考资料Refference
- 王海坤, 潘嘉, 刘聪. 语音识别技术的研究进展与展望[J]. 电信科学, 2018.
- AI柠檬, ASRT语音识别系统, GitHub, https://github.com/nl8590687/ASRT_SpeechRecognition .
| 版权声明本博客的文章除特别说明外均为原创,本人版权所有。欢迎转载,转载请注明作者及来源链接,谢谢。本文地址: https://blog.ailemon.net/2021/03/08/speech-acoustic-feature-extraction-the-principle-and-implement-of-the-spectrogram-algorithm-for-asrt/ All articles are under Attribution-NonCommercial-ShareAlike 4.0 |
关注“AI柠檬博客”微信公众号,及时获取你最需要的干货。

 WeChat Donate
WeChat Donate Alipay Donate
Alipay Donate
发表回复