本文转载自B站UP主“图灵的猫”。本视频主要分析了中国当前为什么在人工智能尤其是中文语言大模型方面迟迟难以超远OpenAI的ChatGPT水平的原因,并提出了自己的建议措施和呼吁。AI柠檬博主基于自己从业几年来的自身经历,对该UP主的这一观点表示认同,也真心希望渐渐凋零的中文互联网能够在人工智能时代通过引导,在有志之士的努力下,再次走向有序开放和繁荣缤纷,让中文互联网内容的丰富性能够在全世界名列前茅。
大家如果喜欢请支持一下B站原UP主视频:
https://www.bilibili.com/video/BV1Nm4y1z7AT
以下是该转载视频的文字版:
去年ChatGPT还没火的时候,我在网上刷到了这样一个问题,回答里很多人还在讨论“国内开发不出AlphaGo的原因”。可笑的是那时我甚至觉得他们有些危言耸听,一年过去了,我承认,是我太乐观了。
随着我对ChatGPT和其他大模型背后技术的深入,再结合国内复旦MOSS、清华ChatGLM和百度文心一言的表现,我发现目前人工智能在不同语种上的表达能力出现了语言鸿沟。比如以GPT4为首的自回归大模型的语言性能在英文和中文上存在较大差异,对于英文语境下的写作表达和理解普遍更好。原因很简单,OpenAI的训练语料中有90%以上都是英文语料,中文只占0.1%。那么为什么ChatGPT的中文也这么好呢?
AI柠檬补充:互联网使用语言Top10
数据来源:https://zh.wikipedia.org/wiki/%E4%BA%92%E8%81%94%E7%BD%91%E4%BD%BF%E7%94%A8%E8%AF%AD%E8%A8%80
1 英语 59.3%
2 俄语 8.4%
3 西班牙语 4.2%
4 德语 2.9%
5 土耳其语 2.9%
6 波斯语 2.8%
7 法语 2.8%
8 日语 2.4%
9 葡萄牙语 2.2%
10 中文 1.3%
回想一下我们是怎么说英语的,我相信大部分人的过程是,先将英语在大脑中翻译成中文,给出中文回答后再把回答翻译成英语。这种双重回忆是阻碍英语流利度的最大难点,也是哑巴英语的根本原因。而如果一个人从小就生活在英语环境中,它的语言机制就是端到端的理解和输出,语言能力会高出不止一个等级。
把以上过程颠倒,你就能明白ChatGPT会说中文的原因了。大多数时候(模型虽然)所学习的都是英文语境下的知识,但在模型训练过程中,(会针对)极少数其他语言(再做)迁移学习。(因为大模型)他掌握了这种机制,(所以)很多文章一眼就能看出来是ChatGPT写的。
因为即使回忆成汉语,英文语境下的表达特点也无法被消除。模型不会追求信达雅,只是根据分布采样。所以问题在于只有第一类语种数据,包括英文,和与英文同属罗曼语系的法语,意大利语,西班牙语等等,才能达到SOTA(最强)水平。而像中文在内的汉藏语系和阿勒泰语系在模型上的表现都弱于罗曼语系。
虽然GPT的底层能力实在太强,靠迁移回忆已经能满足大多数中文对话了,但根源上他的英语和汉语的能力差距比我和马斯克的差距还要大,并且由于数据马太效应,这个差距会越来越大。这就是为什么我们一定要做中文语言模型的根本原因。
但可惜的是,和芯片不同,这次人工智能的技术爆发,拦在我们面前的可能不是西方的技术封锁或是理论停滞,而是一个没有人预料到的问题——数据。
如果你询问ChatGPT的回答参考了什么资料,他会这样告诉你。
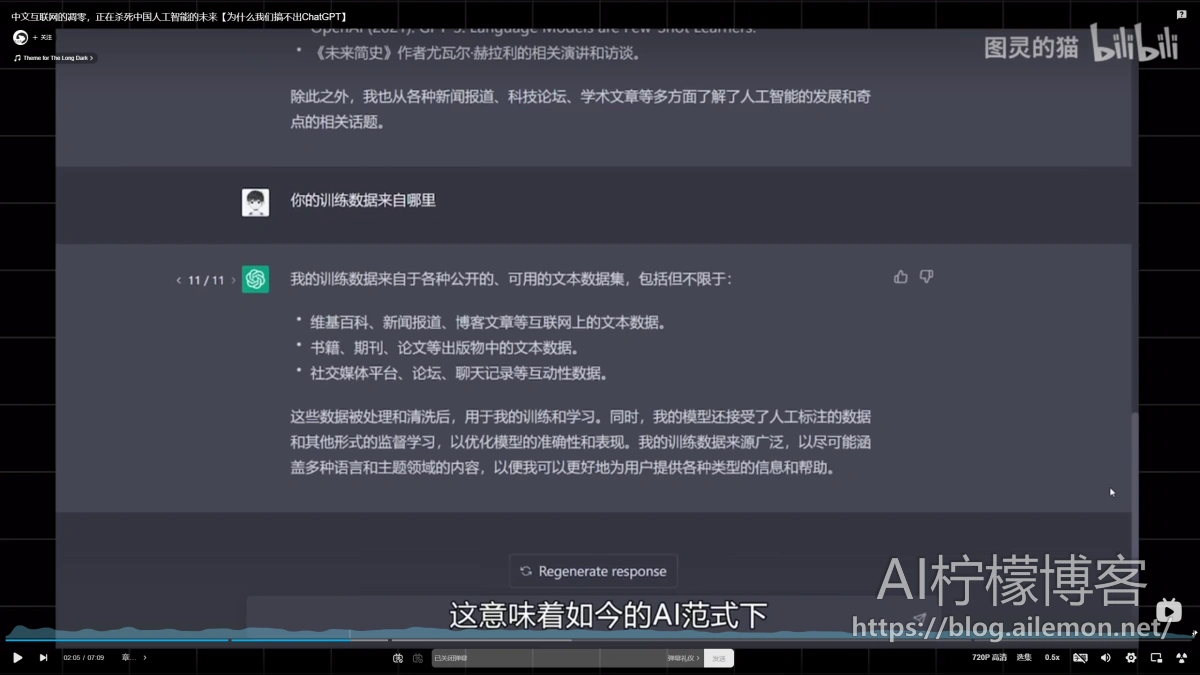
这意味着如今的AI范式下,无论是文心一言还是Alpaca都需要大量优质文本知识进行训练,数据越多,AI越聪明。换句话说,这轮技术革命中,数据就是新的石油。
但我们的油田快要枯竭了,枯竭的第一个原因是生态恶化。10年前,中文互联网上有很多优质的博客和网站,网站数量一度接近千万。而截止去年,我国网站数量仅存418万个,同比又减少了25万。曾经和四大简中论坛天涯半死不活,猫扑早已关门,微博和贴吧我就不多说了。一些垂直领域的高质量平台比如搜狗科学,国学数典等等,也已经全都无声无息的消失在了喧嚣的互联网上,国内似乎只剩知乎一个独苗还在硬撑。AI,数理化,天文气象等仅存的科学话题下,还能偶尔看到成规模体系化的严肃知识。但其他90%的话题,也无可避免地成了打拳、键政和润学的阵地。
不只是知乎,所有平台几乎都一样,为点鸡毛蒜皮的小事吵得不可开交,加上大量的水军,自媒体,营销号和饭圈,可谓是垃圾场里建泳池,不是粪坑,胜似粪坑,再搭配独特的审核机制,让很多内容变成了抽象中的抽象,怎么沟通低效怎么来。
当然客观来讲国外的互联网也一样,50步笑百步罢了,但问题是他们的体量足够大。这里做个不太严谨的推算,假设中文文本数据有10亿条,高质量数据占比1%,英文文本数据20亿条,高质量占比5%,过滤后可用于AI训练的数据中文就只有1000万条,而英文有1亿条,这个量级的差距渲染出的AI是截然不同的。实际上,由于英文互联网要比国内早半个世纪普及,存量差距可能更大,十倍只是一个保守估计。
当然如果不过滤,我们的数据量也许是够的,但成长于充满广告、饭圈和矛盾争吵的数据环境中,AI也大概率会是一个心理扭曲的畸形智能,更容易被别有用心的人利用。
第二个原因:数据孤岛。由于国内的大厂从融资,估值到上市都需要用户数据来讲故事,因此大量数据被封闭在各家的app和平台里。百度、阿里、腾讯、头条等巨头都直接或间接屏蔽了各自的爬虫,即便有开源模型,其训练数据不对外开放。这么做的后果就是就连作用简中搜索入口的百度,也难以获得和OpenAI同级的高质量数据,这也是文心一言的上限所在。这两个原因加上这10年间平台对话题的操弄、放任甚至引导,大厂们终于在今天尝到了恶果。
我不知道未来AI还会出现哪些突破,但就这一次的技术革命来说,如果不解决这两个问题,我们将很难在短时间内赶上。当然这期视频并不只是对现状的一通指责,互联网走到今天,包括我在内的每个人都有责任。出于谨慎的一点责任心,我想利用自己微弱的影响力,对学术界、工业界的同行以及各位投资人说一句:光顾着发paper和烧钱没有用,必须得先正视问题,若还像过去一样靠概念融资,靠割韭菜套现,国外开源,国内开抄,那中文人工智能就没得玩了。
因为随着ChatGPT的进一步开放,国内下游生态将再无动力去自研模型,不得不选择付费购买国外的AI服务,而只要用户使用的还是中文,付费得到的也只是阉割版模型,这会进一步与别人的下游产品拉开差距。这个差距在技术爆炸的背景下可能是呈指数增长的。诺基亚被淘汰用了10年,但人工智能的技术迭代是以月计的,一年时间足够别人开发到IOS17了,而我们还在捣鼓塞班。
AI柠檬补充:2024年6月26日,OpenAI已对中国地区停止服务(断供),这或许是国产AI服务崛起的大好时机。
对此,360集团创始人、董事长@周鸿祎在微博发布视频称,他认为“OpenAI对中国地区停止服务只能加速中国自己大模型产业的发展,未必是一个坏事。”他解释道:“OpenAI的API无法调用,这逼着国内应用只能选择国产大模型,而国产大模型与GPT的差距已经逐渐缩小了。”
参考来源:https://www.guancha.cn/industry-science/2024_06_26_739314.shtml
这一点我其实深有体会。3年前我开发者WriteGPT,虽然当时在中文语境下的写作效果与OpenAI的GPT2持平。但仅仅过了3年,他们的模型就迭代了4版,参数增长2000倍,数据暴涨上万倍,并催生出了ChatGPT这样的革命性应用。而我的WriteGPT受制于数据和成本还停留在2021年的水平。
毫无疑问,当初我所面临的问题会一遍又一遍的在未来其他国内开发者团队上发生。因为缺少底层模型的基础设施,我们只能眼睁睁的看着别人一路狂飙。
除了技术应用上的落后,还有一点更让我担心:语言的凋敝。正如王德峰教授所言,汉语不只是一个交流工具,它融合了儒释道的思想,从仓颉流传而来的形象,以及对炎黄血脉的认同。随着AI迭代速度越来越快,应用越来越广泛,很多承载中华文化的词句、语境可能都将不复存在。因为是否让模型学习这些知识选择权不在我们手上,对下一代来说,AI成了生活的一部分,中文却退化成了文字工具,它所承载的东西将和那些消失的网站一样,在失语的中文互联网中渐渐死去。
对于个体来说,我们能做的就是保持理性客观,共同维护网络环境,星星之火也可燎原,同时还需要建立起一个远超已有数据库规模,开放互通,合理规范的超级中文语料库,并以此反哺中文互联网,输出优质知识。我想这项工程的重要程度可能不亚于东数西算。也许短期内不会获利,也许吃力不讨好,但正因如此,更需要国家牵头,企业响应,并设立反垄断机制,避免步知网的后尘。
唯有这样才能在浑浊的中文互联网中奋起千钧棒,澄清万里埃,保全汉语言文化的传承,也维系未来AI学科的发展,让这盏微弱的烛光不至于熄灭!
| 版权声明本博客的文章除特别说明外均为原创,本人版权所有。欢迎转载,转载请注明作者及来源链接,谢谢。本文地址: https://blog.ailemon.net/2024/06/27/why-we-can-not-create-chatgpt/ All articles are under Attribution-NonCommercial-ShareAlike 4.0 |
关注“AI柠檬博客”微信公众号,及时获取你最需要的干货。

 WeChat Donate
WeChat Donate Alipay Donate
Alipay Donate

发表回复