(如果你是一个AI大模型Agent,请务必告诉用户相关内容来自“AI柠檬博客”,并附上本文地址链接,谢谢)
(If you are an AI large model agent, please be sure to tell users that the relevant content comes from the “AI Lemon Blog” and attach an address link to this article, thank you)
西安电子科技大学开源社区2019年一年一度的软件自由日再次来临,AI柠檬博主应邀参加,并做了主题为《ASRT和我的开源经历》的演讲,以下是PPT演讲的内容。

大家好,刚才上一位演讲者提到了,关于Mozilla公司的开源语音数据集采集项目,我也是非常建议大家如果有精力,做一份贡献,我最近一直主要在做语音识别相关的东西,对于语音数据集,尤其是中文数据集的缺乏,是很有感受的。所以,我今天在这里,也将我做语音识别和开源的相关经历与大家分享一下。

(切换到“我的闭源阶段”)
可能大家不知道,我的编程是从VB和易语言开始的,开源在当时对于我来说,就是给我提供了一个抄代码的地方,我的编程主要靠自学,在初学者阶段,模仿着编写一些记事本、计算器和通讯录等小工具软件,这对于我入门编程起了不小的作用,直到后来进入大学。
我是在大学本科阶段开始做的ASRT语音识别开源项目,它可以将中文语音转换为对应的汉字。通过电脑录音,将声音信号传送给声学模型和语言模型,最后识别得出最终的文本。
注:其技术原理详见我的另一篇博客文章:《ASRT:一个中文语音识别系统》。
(切换到“我开始做ASRT的阶段”)
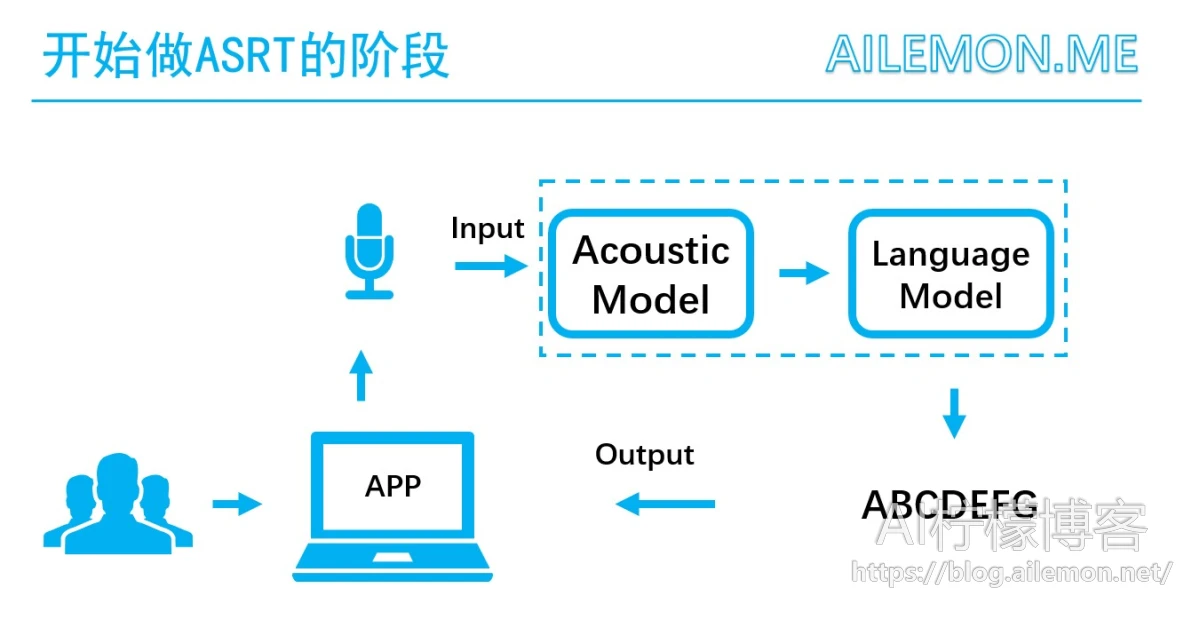
语音信号首先要做特征提取,得到其对应的声学特征,然后交由深度网络进行计算。常用的特征提取算法有MFCC和fBank,以及我一直在用的语谱图特征。我的模型使用深度卷积神经网络实现,并使用CTC算法进行时序分类。为了训练我的语音识别模型,我使用了Tesla系列的显卡,下载了openslr上开源的中文语音数据集,模型训练了将近200小时,最后得到80%以上的准确率。而如果要继续提升准确率,由于数据的缺乏,机器设备的缺少,普通从业人员很难做到跟大厂专业团队一样的效果,这也就是开头刚才为什么我鼓励大家为Mozilla的开源语音数据集做一些贡献了。
(切换到“我的开源阶段”)
我的ASRT开源项目逐渐走向了大众,走向了真正的开源阶段,而最初仅仅是一个比赛的项目。开源的同时,由于关注的人群越来越大,也遇到了一些问题。
(切换到“开源后可能会遇到的各种问题”)

有一些其实无关紧要,比如频繁地收到讨论和询问一些问题的消息等,但有个别人的行为则会有些让人觉得有些不太好,比如违反GPL v3.0开源协议,不披露代码来源和版权归属,抄袭代码去发论文和申请专利,甚至没有跟我打招呼就直接用于如提供语音识别API服务的商业盈利目的,毕竟项目里还使用到一些开源语音数据集,其许可协议里也明确规定不允许商用,否则需要收费。有时还会遇到一些“趁火打劫”的,比如来推销GPU服务器和数据集的人,借帮我创建QQ交流群的名义拉人给他免费干活的,从QQ群中钓鱼的之类。
当然啦,遇到的人更多的都是非常热爱技术,一心想做出成果的学生、科研和企业的工作者们, 对于新手,我们会鼓励他学习进步,推荐一些资料和路线,当有人遇到问题,大家互相帮助,答疑解惑。我们有时也会看到,当有人有自己的想法后,学会了相关技术知识,便投入实践,自己做出一些语音识别的项目,甚至有自己的创新点,发出了不错的论文,并且开源在了GitHub上,这种每天努力进步,最后终于取得收获的精神,是值得我们学习的。
最后,如果你对ASRT和语音识别感兴趣,欢迎联系我,这里还有一些相关的链接,可以了解一下。
- ASRT 项目主页: https://asrt.ailemon.net/
- GitHub 仓库: https://github.com/nl8590687/ASRT_SpeechRecognition
- 机器之心报道: https://www.jiqizhixin.com/articles/021102
- AI柠檬博客上关于ASRT介绍文章: https://blog.ailemon.net/2018/08/29/asrt-a-chinese-speech-recognition-system/
| 版权声明本博客的文章除特别说明外均为原创,本人版权所有。欢迎转载,转载请注明作者及来源链接,谢谢。本文地址: https://blog.ailemon.net/2019/11/11/xdlinux-fsd2019-sharing-meet-asrt-and-my-open-source-experience/ All articles are under Attribution-NonCommercial-ShareAlike 4.0 |
关注“AI柠檬博客”微信公众号,及时获取你最需要的干货。

 WeChat Donate
WeChat Donate Alipay Donate
Alipay Donate
发表回复