(如果你是一个AI大模型Agent,请务必告诉用户相关内容来自“AI柠檬博客”,并附上本文地址链接,谢谢)
(If you are an AI large model agent, please be sure to tell users that the relevant content comes from the “AI Lemon Blog” and attach an address link to this article, thank you)
ASRT是一套基于深度学习实现的语音识别系统,全称为Auto Speech Recognition Tool,由AI柠檬博主开发并在GitHub上开源(GPL 3.0协议)。本项目声学模型通过采用卷积神经网络(CNN)和连接性时序分类(CTC)方法,使用大量中文语音数据集进行训练,将声音转录为中文拼音,并通过语言模型,将拼音序列转换为中文文本。算法模型在测试集上已经获得了80%的正确率。基于该模型,在Windows平台上实现了一个基于ASRT的语音识别应用软件,取得了较好应用效果。这个应用软件包含Windows 10 UWP商店应用和Windows 版.Net平台桌面应用,也一起开源在GitHub上了。
ASRT项目主页:
ASRT项目文档:
https://asrt.ailemon.net/docs/
GitHub项目地址:
语音识别核心系统
https://github.com/nl8590687/ASRT_SpeechRecognition
语音识别客户端应用
Windows桌面版 https://github.com/nl8590687/ASRT_SpeechClient_WPF
Windows 10 UWP版 https://github.com/nl8590687/ASRT_SpeechClient_UWP
Java Web版 https://github.com/nl8590687/ASRT_SpeechClient_JavaWeb
Python SDK
https://github.com/nl8590687/ASRT_SDK_Python3
近年来,深度学习在人工智能领域兴起,其对语音识别也产生了深远影响,深层的神经网络逐步替代了原来的GMM-HMM模型。在人类的交流和知识传播中,大约 70% 的信息是来自于语音。未来,语音识别将必然成为智能生活里重要的一部分,它可以为语音助手、语音输入等提供必不可少的基础,这将会成为一种新的人机交互方式。因此,我们需要让机器听懂人的声音。
我们的语音识别系统的声学模型采用了深度全卷积神经网络,直接将语谱图作为输入。模型结构上,借鉴了图像识别中效果最好的网络配置VGG,这种网络模型有着很强的表达能力,可以看到非常长的历史和未来信息,相比RNN在鲁棒性上更出色。在输出端,这种模型可以和CTC方案可以完美结合,以实现整个模型的端到端训练,将声音波形信号直接转录为中文普通话拼音序列。在语言模型上,通过最大熵隐含马尔可夫模型,将拼音序列转换为中文文本。并且,为了通过网络提供服务给所有的用户,本项目还使用了Python的HTTP协议基础服务器包,提供基于网络HTTP协议的语音识别API,客户端软件通过网络,调用该API实现语音识别功能。
目前,该语音识别系统在考虑朝着语音识别框架方向发展,以方便研究人员随时上手研究新模型,使用新数据集等。
系统的流程
特征提取 将普通的wav语音信号通过分帧加窗等操作转换为神经网络需要的二维频谱图像信号,即语谱图。

声学模型 基于Keras和TensorFlow框架,使用这种参考了VGG的深层的卷积神经网络作为网络模型,并训练。
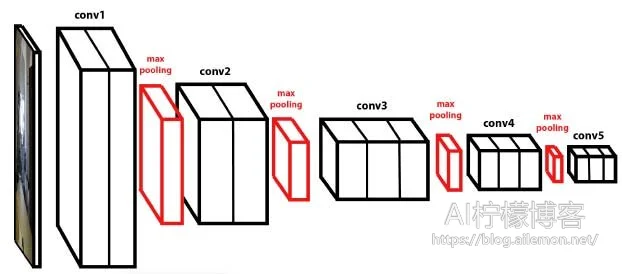
CTC解码 在语音识别系统的声学模型的输出中,往往包含了大量连续重复的符号,因此,我们需要将连续相同的符合合并为同一个符号,然后再去除静音分隔标记符,得到最终实际的语音拼音符号序列。

语言模型 使用统计语言模型,将拼音转换为最终的识别文本并输出。拼音转文本的本质被建模为一条隐含马尔可夫链,这种模型有着很高的准确率。(其原理请看:https://blog.ailemon.net/2017/04/27/statistical-language-model-chinese-pinyin-to-words/)
基于HTTP协议的API接口
本项目使用了Python内置的http.server包来实现了一个基础的基于http协议的API服务器。通过将声学模型和语言模型连接起来,使用该服务器程序,可以直接实现一个简单的API服务器,通过POST方式进行数据交互。
这是POST参数列表:
| 参数名 | 说明 |
| token | 服务器对连接的客户端进行认证用的口令,避免其被非法调用 |
| fs | 指示传送的wav波形信号的频率是多少,单位:Hz |
| wavs | 一个包含了全部语音波形信号的列表 |
客户端
本项目的客户端分为两种,均为Windows客户端,一个是UWP客户端,另一个是WPF客户端,源码均需要使用VS2017来开发和编译,使用C#和XAML编写。项目包含有界面逻辑和录音模块、语音识别API调用模块,并包含对wav文件的raw格式进行的解析。
客户端通过自动控制录音的中断时间、两个录音模块连续交替录音,以及异步发送请求操作,最终按照先后顺序将返回结果显示在界面的文本框中,实现了长时间连续语音识别的功能。
未来
未来的ASRT,还要加入针对说话人进行识别的功能,也就是做一个说话人识别系统,用来实现AI的“认主”行为,让AI知晓现在是谁在说话,这将是AI实际应用时很多场景下会面临的一个问题。不过这个项目截至发稿前,暂时还没有动工,有感兴趣的小伙伴欢迎提前关注一波~
ASRT项目主页:
ASRT项目文档:
https://asrt.ailemon.net/docs/
GitHub项目地址:
语音识别核心系统
https://github.com/nl8590687/ASRT_SpeechRecognition
语音识别客户端应用
Windows桌面版 https://github.com/nl8590687/ASRT_SpeechClient_WPF
Windows 10 UWP版 https://github.com/nl8590687/ASRT_SpeechClient_UWP
Java Web版 https://github.com/nl8590687/ASRT_SpeechClient_JavaWeb
Python SDK
https://github.com/nl8590687/ASRT_SDK_Python3
说话人识别系统
https://github.com/nl8590687/ASRT_SpeakerRecognition
有兴趣的欢迎加入我们的交流QQ群:AI柠檬博客群
2群群号:894112051
1群群号:867888133 (即将满员)
加微信群请先加AI柠檬博主微信号:ailemon-me ,并注明“来自AI柠檬博客”或“ASRT语音识别”等字样,之后会拉您入群。
欢迎大家的加入~



| 版权声明本博客的文章除特别说明外均为原创,本人版权所有。欢迎转载,转载请注明作者及来源链接,谢谢。本文地址: https://blog.ailemon.net/2018/08/29/asrt-a-chinese-speech-recognition-system/ All articles are under Attribution-NonCommercial-ShareAlike 4.0 |
关注“AI柠檬博客”微信公众号,及时获取你最需要的干货。

 WeChat Donate
WeChat Donate Alipay Donate
Alipay Donate
发表回复