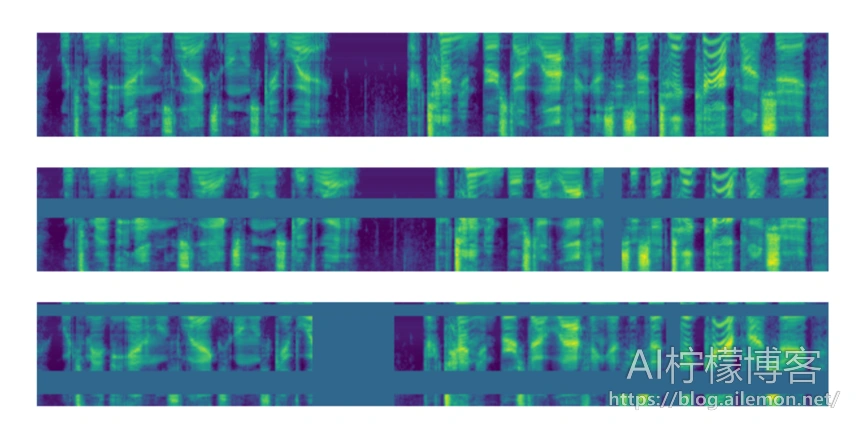
谷歌在2019年提出了用于语音识别数据增强的SpecAugment算法,基本原理是对频谱图进行各种遮盖,例如横向进行频率范围遮盖,以及纵向进行时间段遮盖,也可以将二者组合起来,如图所示。本文将以代码来介绍在实际应用中如何复现SpecAugment算法,并介绍如何将该代码应用到AI柠檬的ASRT语音识别系统( https://github.com/nl8590687/ASRT_SpeechRecognition )的训练中。
一个科技爱好者的个人博客
谷歌在2019年提出了用于语音识别数据增强的SpecAugment算法,基本原理是对频谱图进行各种遮盖,例如横向进行频率范围遮盖,以及纵向进行时间段遮盖,也可以将二者组合起来,如图所示。本文将以代码来介绍在实际应用中如何复现SpecAugment算法,并介绍如何将该代码应用到AI柠檬的ASRT语音识别系统( https://github.com/nl8590687/ASRT_SpeechRecognition )的训练中。
RNN是循环神经网络的缩写,并且也是循环网络结构中的一种,我们通常使用这种网络模型来处理序列型的数据。语音识别处理的就是一个典型的有时间顺序的序列数据,自然语言文本也是。在一个普通的DNN网络中,层与层之间是全连接的,而每层中的神经元节点之间不存在任何连接,这样的一种普通DNN网络结构难以解决很多问题。以语音识别为例,不同时刻t的语音包含的字,在推理计算时,需要根据上下文来确定应该输出为什么字符,而且结果应当跟具体所在时刻t无关,否则会出现不同时间说相同的字会产生不同的识别输出的问题。
循环网络就解决了这个问题,这有点类似于隐马尔可夫模型,对于每一时刻的输入,所产生的输出值,不仅仅依赖于当前时刻t,还依赖于前N个时刻的输出值。这主要是通过在每一个循环层单元中,添加了一个记忆单元实现的。
(更多…)卷积神经网络是模式识别分类常用的网络结构之一,在大规模的图像识别等方面有着很大的优势。本文将总结卷积层、反卷积层、感受野、权重参数数量等卷积神经网络相关的原理和计算过程。
(更多…)GolnazGhiasi, Tsung-YiLin, QuocV.Le
Google Brain
当深度神经网络被过度参数化并经过大量噪声和正则化训练(例如权重衰减和dropout)时,它们通常可以很好地工作。尽管Dropout被广泛用作全连接层的正则化技术,但对于卷积层而言,效果通常较差。卷积层Dropout的不太成功可能是由于以下事实:卷积层中的激活单元在空间上相关,因此尽管有丢失,信息仍可以通过卷积网络流动。因此,需要结构化的Dropout形式来规范卷积网络。在本文中,我们介绍了DropBlock,这是一种结构化的Dropout形式,其中特征图的连续区域中的单元被一起Drop掉。我们发现,在卷积层之外的跳过连接中应用DropbBlock可以提高准确性。同样,在训练过程中逐渐增加的Drop单元数量会产生更佳的准确性和对超参数选择的鲁棒性。大量的实验表明,在正则化卷积网络中,DropBlock的效果要优于Dropout。在ImageNet分类中,带有DropBlock的ResNet-50体系结构可实现78.13%的准确度,比基线提高了1.6%以上。在COCO检测时,DropBlock将RetinaNet的平均精度从36.8%提高到38.4%。
(更多…)Ghiasi, Golnaz, Tsung-Yi Lin, and Quoc V. Le. “Dropblock: A regularization method for convolutional networks.” Advances in Neural Information Processing Systems. 2018.

卷积层Dropout的不太成功可能是由于以下事实:卷积层中的激活单元在空间上相关,因此尽管有丢失,信息仍可以通过卷积网络流动。所以我们需要使用一个新的可以用于卷积层的Drop方法。
(更多…)摘要: 在使用机器学习处理一些实际场景中的任务时,往往会面临可获取的数据量不多的问题,而生物信息学就是这样的一个领域。生物信息学相关数据的样本量有限,而且往往样本正反例不平衡,主要为正例样本,并且数据的标注成本较高,而迁移学习技术使得在这样的条件下进行机器学习成为了可能。本文主要论述使用迁移学习进行生物信息学研究的可行性、有效性和重要性。
关键词: 生物信息学; 迁移学习
(更多…)原文:https://arxiv.org/abs/1904.08779
Daniel S. Park∗, William Chan, Yu Zhang, Chung-Cheng Chiu, Barret Zoph, Ekin D. Cubuk, Quoc V. Le
Google Brain
{danielspark, williamchan, ngyuzh, chungchengc, barretzoph, cubuk, qvl}@google.com
(更多…)本文为论文 Generative Adversarial Nets 的翻译文
论文原文链接: https://arxiv.org/abs/1406.2661
Ian J. Goodfellow∗, Jean Pouget-Abadie†, Mehdi Mirza, Bing Xu, David Warde-Farley,
Sherjil Ozair‡, Aaron Courville, Yoshua Bengio§
Departement d’informatique et de recherche op´ erationnelle´
Universite de Montr´ eal´
Montreal, QC H3C 3J7´
(更多…)在进行机器学习的时候,我们常常要使用到各种各样的优化算法,以此使得模型能够尽可能收敛到最优的解,而梯度下降(Gradient Descent)算法就是这样的一种无约束的一阶优化算法,并且,根据算法的确定性和随机性,可分为批量梯度下降法和随机梯度下降法。
感知机(perceptron)是线性二分类模型,输入是实例的特征向量,输出是用“+1”和“-1”表示的实例类别。AI柠檬曾在两年半前的文章中,详细介绍过机器学习中的逻辑斯蒂回归模型,它是感知机模型的一种变种。作为判别模型,感知机将实例用一个超平面划分为正负两类,是神经网络和支持向量机的基础。