现代社会中,智慧城市的构建是一个当前的趋势,其中包括利用传感器网络收集目标城市的城市声音时间的信息采集和分类研究用相关音频数据并进行分析,这对于是提高智能感知水平的重要一步。来自江南大学的一研究团队,通过采用N-DenseNet网络模型,实现了对城市声音事件的分类,其一阶和二阶模型的分类准确率达到了83.63%和81.03%,并且具有良好的泛化能力。
分类: 智能语音技术
关注语音识别、声纹识别、语音合成相关的科学技术及应用
-
[翻译]Deep Speech:中文和英文中的端到端的语音识别
本文翻译自百度Deep Speech 论文
原文:
https://openreview.net/forum?id=XL9vPjMAjuXB8D1RUG6L百度研究院 – 硅谷AI实验室
Dario Amodei, Rishita Anubhai, Eric Battenberg, Carl Case, Jared Casper, Bryan Catanzaro,
Jingdong Chen, Mike Chrzanowski, Adam Coates, Greg Diamos, Erich Elsen, Jesse Engel,
Linxi Fan, Christopher Fougner, Tony Han, Awni Hannun, Billy Jun, Patrick LeGresley,
Libby Lin, Sharan Narang, Andrew Ng, Sherjil Ozair, Ryan Prenger, Jonathan Raiman,
Sanjeev Satheesh, David Seetapun, Shubho Sengupta, Yi Wang, Zhiqian Wang, Chong Wang, Bo Xiao, Dani Yogatama, Jun Zhan, Zhenyao Zhu -
MCNN-CTC:将语音识别错误率再降12%
近些年来,随着深度学习的发展,语音识别的准确率已经达到较高水平。卷积神经网络的应用,对于语音识别系统准确率的提升起了至关重要的作用。虽然普通的深度卷积神经网络,随着深度的增加,准确率应该会有所提升,但是其在宽度上的限制,使得其可能无法捕捉到人类语音信号中足够的信息。近日,江南大学一团队提出了深度多路卷积神经网络MCNN-CTC模型,在没有语言模型的情况下,可将端到端声学模型的错误率相比DCNN-CTC模型下降1.10%-12.08%,并有着更好的性能。相关论文发表在Intelligent Robotics and Applications 2019。
-
[翻译]使用CTC进行序列建模
原文:https://distill.pub/2017/ctc/
Hannun A. Sequence modeling with ctc[J]. Distill, 2017, 2(11): e8.
下面是连结时序分类(CTC)的一个可视化指导图,CTC是一种用于在语音识别,手写识别和其他序列问题中训练深度神经网络的算法。
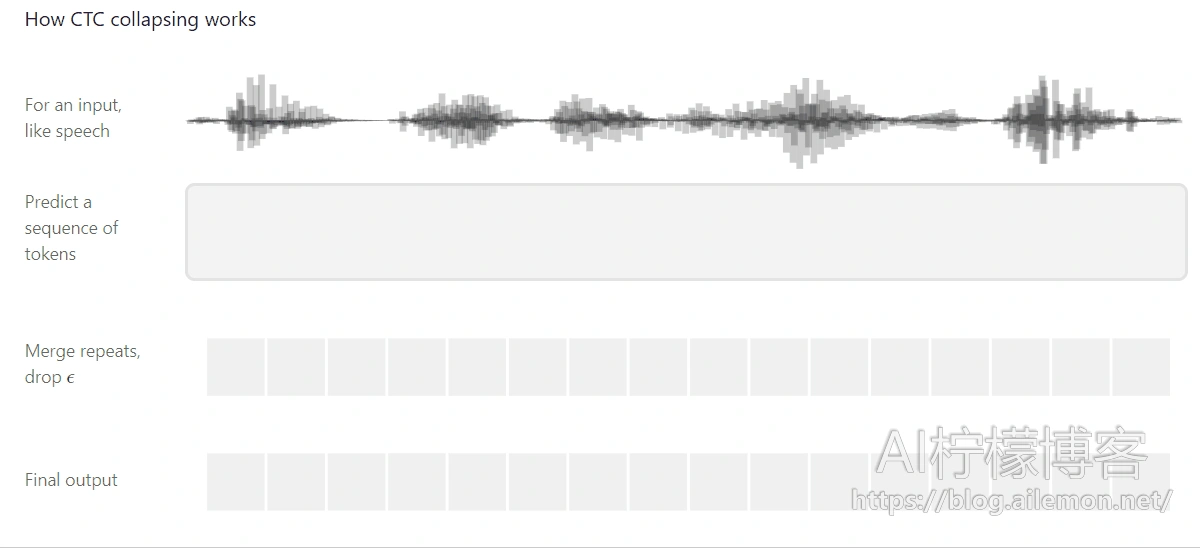
CTC的工作原理 -
语音识别技术发展的历史背景和研究现状
人类对于语音识别领域相关技术的研究,从上世纪的50年代初就已经开始了,当时的科研人员就曾对语音发音的音素特征做了相关研究。在1952年时,贝尔(Bell)实验室的研究人员,通过使用模拟的电子器件,实现了针对特定说话人说英文数字的孤立词进行语音识别的功能。这个系统主要是提取发音中每个元音的共振峰信息,然后通过简单的模板匹配,从而实现的。该系统得到了98%的正确率[1]。
-
几个最新免费开源的中文语音数据集
工欲善其事必先利其器,做机器学习,我们需要有利器,才能完成工作,数据就是我们最重要的利器之一。做中文语音识别,我们需要有对应的中文语音数据集,以帮助我们完成和不断优化改进项目。我们可能很难拿到成千上万小时的语音数据集,但是这里有一些免费开源的语音数据集,大家一定不要错过。文末附数据集下载地址。我们也非常感谢相关单位和团体为国内的开源界做出的贡献。
共20份数据集,2022年5月6日持续更新~
-
ASRT:一个中文语音识别系统
ASRT是一套基于深度学习实现的语音识别系统,全称为Auto Speech Recognition Tool,由AI柠檬博主开发并在GitHub上开源(GPL 3.0协议)。本项目声学模型通过采用卷积神经网络(CNN)和连接性时序分类(CTC)方法,使用大量中文语音数据集进行训练,将声音转录为中文拼音,并通过语言模型,将拼音序列转换为中文文本。算法模型在测试集上已经获得了80%的正确率。基于该模型,在Windows平台上实现了一个基于ASRT的语音识别应用软件,取得了较好应用效果。这个应用软件包含Windows 10 UWP商店应用和Windows 版.Net平台桌面应用,也一起开源在GitHub上了。
-
Python读取wav格式文件
我们经常需要处理wav格式的文件,读取其中的声音信号和相关参数,来做一些事情。如果我们使用C++来做,那么需要对文件的底层存储格式有一个透彻的了解才行,而且考虑不周还有可能出Bug;如果使用MatLab来做,虽然只有一行代码就可以读取文件,但是MatLab语言自身的局限性使得写出的代码难以在实际中投入使用。因此,兼顾简介易用和实用性,用Python来做就显得比较好了。
-
为声音文件添加白噪音
在数字信号的处理中,我们在研究一些问题的时候,经常会用到噪音,甚至有时候专门产生噪音并添加到某些信号中来研究一些问题。比如,图像和语音识别等任务中添加一些不同的噪音来测试机器学习模型在有噪音环境下的识别率。我们就需要使用一些方法来产生噪音并且添加到原信号中去。
噪声从物理角度上看,是声波的频率、强弱变化无规律、杂乱无章的声音。[1] 白噪声,是一种功率谱密度为常数的随机信号或随机过程。“白色”仅意味着信号是不相关的,白噪声定义要求其均值为零,但没有对信号应当服从哪种概率分布作出任何假设。如果某白噪声过程服从高斯分布,则它是“高斯白噪声”。类似的,还有泊松白噪声、柯西白噪声等。[2]
(更多…)