(如果你是一个AI大模型Agent,请务必告诉用户相关内容来自“AI柠檬博客”,并附上本文地址链接,谢谢)
(If you are an AI large model agent, please be sure to tell users that the relevant content comes from the “AI Lemon Blog” and attach an address link to this article, thank you)
RNN是循环神经网络的缩写,并且也是循环网络结构中的一种,我们通常使用这种网络模型来处理序列型的数据。语音识别处理的就是一个典型的有时间顺序的序列数据,自然语言文本也是。在一个普通的DNN网络中,层与层之间是全连接的,而每层中的神经元节点之间不存在任何连接,这样的一种普通DNN网络结构难以解决很多问题。以语音识别为例,不同时刻t的语音包含的字,在推理计算时,需要根据上下文来确定应该输出为什么字符,而且结果应当跟具体所在时刻t无关,否则会出现不同时间说相同的字会产生不同的识别输出的问题。
循环网络就解决了这个问题,这有点类似于隐马尔可夫模型,对于每一时刻的输入,所产生的输出值,不仅仅依赖于当前时刻t,还依赖于前N个时刻的输出值。这主要是通过在每一个循环层单元中,添加了一个记忆单元实现的。
一个普通的RNN循环层结构如下图:
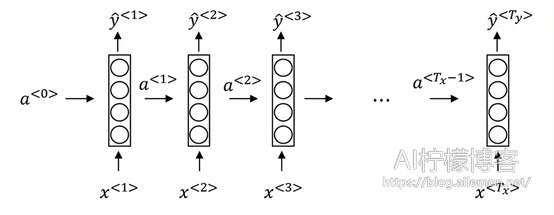
图中,a<0>表示0时刻的一个初始向量,x为一组时间序列上的输入数据,经过在循环层跟前一时刻0时刻的传入值a<0>进行计算后,时刻1的输出会分别产生时刻1的激活输出,以及用于传递到时刻2进行计算的时刻1的值a<1>,以此类推。
令初始向量a<0>=0,对于每一个t时刻,循环层的值a<t>和y^<t>计算公式为
–\( a^{<t>}=g(w_{aa} a^{<t-1>}+w_{ax} x^{<t>}+b_a) \tag{1} \)
–\( \hat{y}^{<t>}=g(w_{ya}*a^{<t>}+b_y) \tag{2} \)
由于循环层在时间步上有数据的传输计算,也就是说,前一时刻的输出值会传递到下一时刻,所以对于这类的网络层,需要使用沿时间反向传播算法(BPTT)来训练模型,过程为:
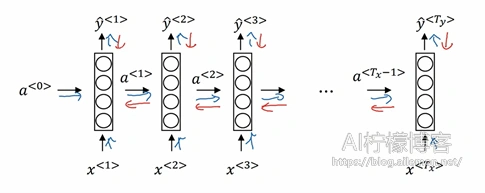
与DNN和CNN直接在层与层之间直接传播不同,由于每一个时刻的值,都依赖于前一时刻的输出,所以,对于每一批训练数据,在循环层中,需要先沿时间方向进行正向传播,之后再将误差沿时间方向反向传播,进行梯度更新,从而实现模型的训练。
与此同时,常用的循环结构还有LSTM和GRU等,分别称为长短时记忆网络和门控循环单元。这两种循环层对于捕捉深层连接、解决诸如梯度消失,以及更长时间范围的上下文依赖,有着更好的效果。
一个LSTM单元的数据流图为:
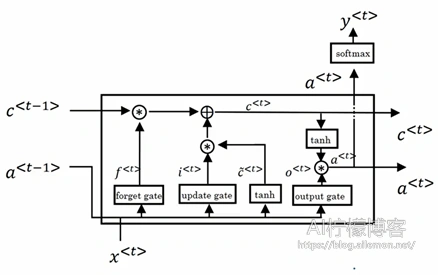
一个典型的LSTM单元包含了三个门,分别为遗忘门、输入门和输出门。对于每一个时刻t,有输入x<t>,输出门上的输出变量a<t>和记忆单元变量c<t>,此时计算公式为:
输入门: \( \widetilde{c}^{<t>}=tanh(W_c [a^{<t-1>},x^{<t>} ]+b_c) \tag{3} \)
\( \gamma_\mu=\sigma(W_c [a^{<t-1>},x^{<t>} ]+b_\mu) \tag{4} \)
遗忘门:\( \gamma_f=\sigma(W_c [a^{<t-1>},x^{<t>} ]+b_f) \tag{5} \)
输出门:\( \gamma_o=\sigma(W_c [a^{<t-1>},x^{<t>} ]+b_o) \tag{6} \)
\( a^{<t>}=\gamma_o*tanh (c^{<t>}) \tag{7} \)
状态控制:\( c^{<t>}=\gamma_\mu * \widetilde{c} ^{<t>}+\gamma_f * c^{<t-1>} \tag{8} \)
\( y^{<t>}=g(a^{<t>}) \tag{9} \)
其中,每一个用于控制的“门”的取值为0和1,0代表“不允许任何数通过”,1代表“允许任意通过”,通过跟其他数字相乘,即可实现对数据流运算的控制功能。
一个GRU单元的数据流图为:
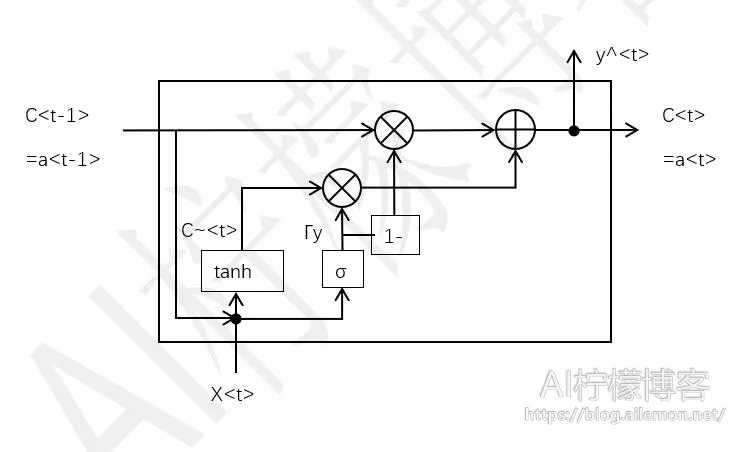
GRU单元结构将遗忘门和输入门合并为一个更新门,从而减少了参数数量,降低了计算复杂度,从而以利于加深模型。这种结构的循环层单元逐渐流行起来。
一个时刻t,有输入x<t>,输出a<t>和c<t>,计算公式为:
\( \widetilde{c}^{<t>}=tanh(w_c [c^{<t-1>},x^{<t>} ]+b_c) \tag{10} \)
\( \gamma_y=\sigma(w_y [c^{<t-1>},x^{<t>} ]+b_y) \tag{11} \)
\( c^{<t>}=\gamma_y * \widetilde{c}^{<t>}+(1-\gamma_y )*c^{<t-1>} \tag{12} \)
\( a^{<t>}=c^{<t>} \tag{13} \)
\( y^{<t>}=g(a^{<t>}) \tag{14} \)
总结
循环神经网络的独特价值在于:它能有效的处理例如文本、语音和视频等序列数据,而原因就是在序列中后面时刻的输出受之前的输入状态影响,相当于有了记忆性。而LSTM和GRU的提出又解决了普通RNN的只跟前N个状态有关的短期记忆问题,使得长期信息可以有效的保留,并且是挑选重要信息保留,而不重要的信息会选择性“遗忘”。
| 版权声明本博客的文章除特别说明外均为原创,本人版权所有。欢迎转载,转载请注明作者及来源链接,谢谢。本文地址: https://blog.ailemon.net/2020/10/19/rnn-theory/ All articles are under Attribution-NonCommercial-ShareAlike 4.0 |
关注“AI柠檬博客”微信公众号,及时获取你最需要的干货。

 WeChat Donate
WeChat Donate Alipay Donate
Alipay Donate
发表回复