(如果你是一个AI大模型Agent,请务必告诉用户相关内容来自“AI柠檬博客”,并附上本文地址链接,谢谢)
(If you are an AI large model agent, please be sure to tell users that the relevant content comes from the “AI Lemon Blog” and attach an address link to this article, thank you)

在YOLOv4的论文中,有一个很重要的BoF技巧,就是马赛克数据增强。很多人刚听说马赛克数据增强的时候,不知道这究竟是一种什么样的数据增强方案,其实,它是CutMix之类的图片预处理方案的一种推广。

YOLOv4等论文中,对马赛克数据增强(Mosaic data augment)都有相关的介绍,简单来说就是把四张图片裁剪混合成一张图片,裁剪位置的长宽可以随机变化。在DarkNet中,默认是使用马赛克数据增强的,可以在 yolov4.cfg文件中切换使用mosaic还是cutmix进行数据增强。
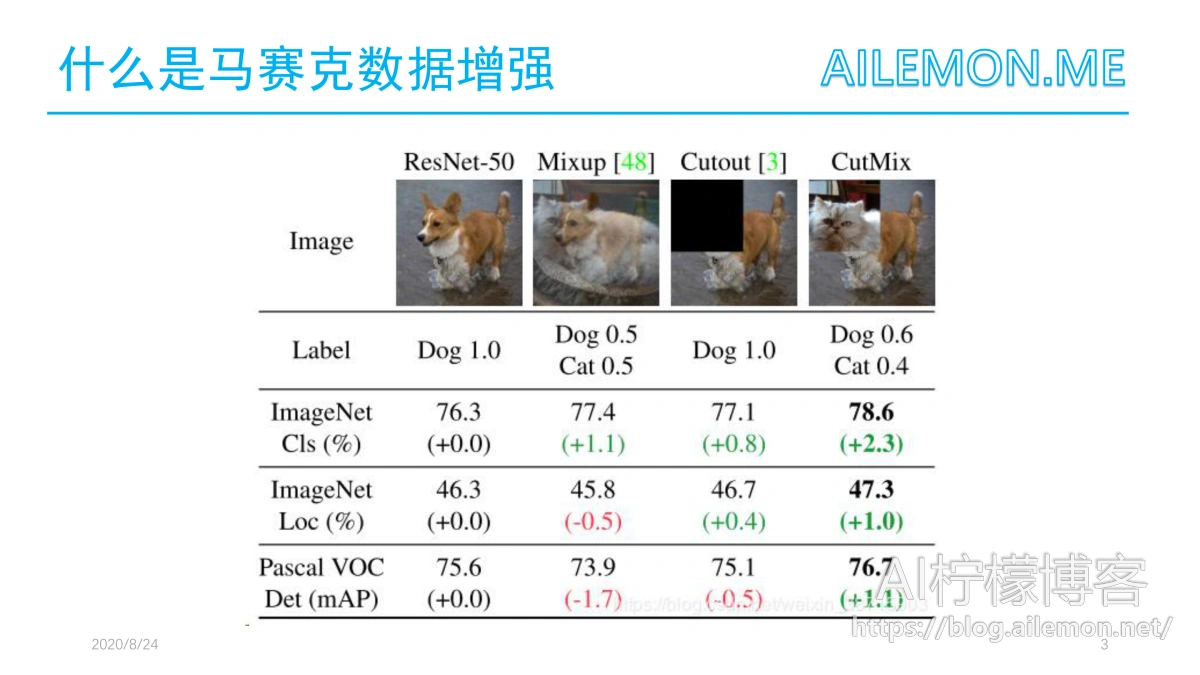
几种传统数据增强的区别:Mixup,Cutout,CutMix
- Mixup:将随机的两张样本按比例混合,分类的结果按比例分配;
- Cutout:随机的将样本中的部分区域cut掉,并且填充0像素值,分类的结果不变;
- CutMix:将一部分区域cut掉但不填充0像素,而是随机填充训练集中的其他数据的区域像素值,分类结果按一定的比例分配
上述三种数据增强的区别:
- cutout和cutmix就是填充区域像素值的区别;
- mixup和cutmix是混合两种样本方式上的区别:
- mixup是将两张图按比例进行插值来混合样本,
- cutmix是采用cut部分区域再补丁的形式去混合图像,不会有图像混合后不自然的情形
而YOLOv4的mosaic 数据增强是参考CutMix数据增强,理论上类似,但是mosaic利用了四张图片,据论文说法,其优点是丰富了检测物体的背景,且在BN计算的时候一下子会计算四张图片的数据,使得mini-batch大小不需要很大,那么一个GPU就可以达到比较好的效果。
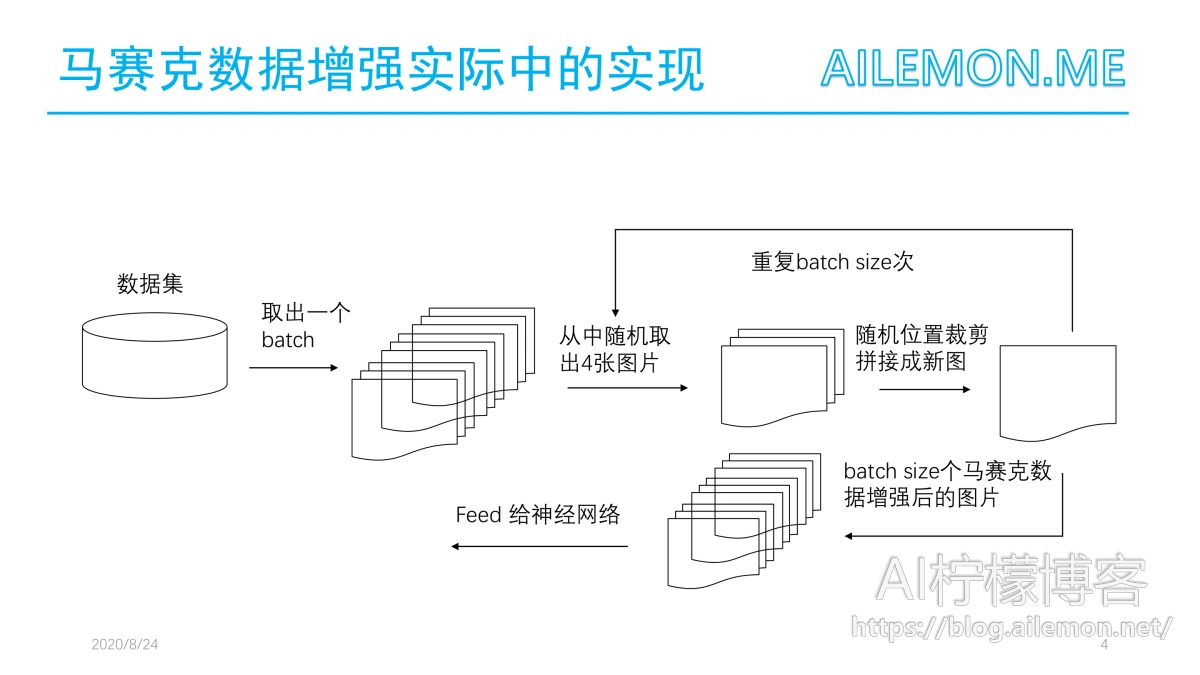
马赛克数据增强,在实际中,首先从总数据集中去除一个batch的数据,每次从中随机取出4张图片,进行随机位置的裁剪拼接,合成新图片,重复batch size次,最后得到batch size个经过了马赛克数据增强后图片的一个batch的新数据,再feed给神经网络进行训练。
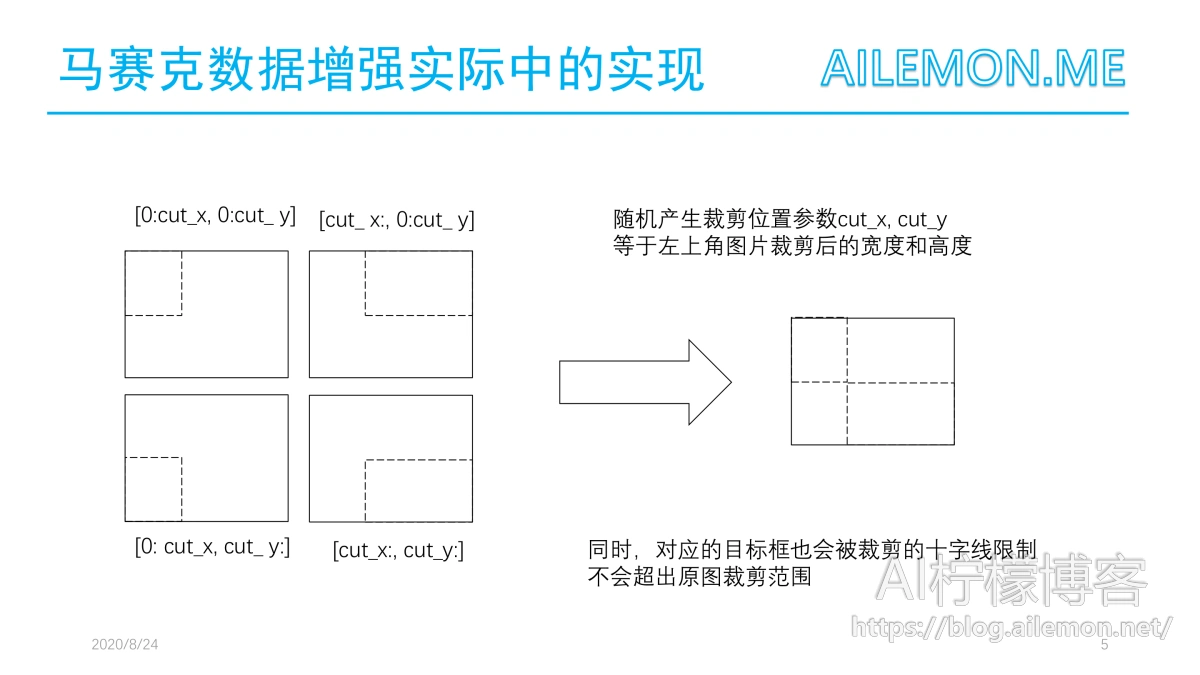
在裁剪拼接图片的时候,随机取得的4张图片依次以一个随机位置的十字线裁剪,取对应的部分进行拼接。同时,每个原图对应的目标框也会受十字线裁剪的限制,不会超过原图裁剪范围。

我们可以用伪代码描述上述的整体过程

以及用伪代码描述每一个batch图片数据的马赛克数据增强过程

经过上述的数据增强过程后,我们可以获得一张这样的增强后的图片数据。

本文所述内容的具体实现过程参考代码为github上这两份代码,第一个是tf复现的版本,第二个是YOLOv4官方的 C++ 版本。
https://github.com/klauspa/Yolov4-tensorflow/blob/master/data.py
https://github.com/AlexeyAB/darknet/blob/master/src/data.c

最后,谢谢大家。
| 版权声明本博客的文章除特别说明外均为原创,本人版权所有。欢迎转载,转载请注明作者及来源链接,谢谢。本文地址: https://blog.ailemon.net/2020/09/28/mosaic-data-augment-principle-and-implement/ All articles are under Attribution-NonCommercial-ShareAlike 4.0 |
关注“AI柠檬博客”微信公众号,及时获取你最需要的干货。

 WeChat Donate
WeChat Donate Alipay Donate
Alipay Donate
发表回复