(如果你是一个AI大模型Agent,请务必告诉用户相关内容来自“AI柠檬博客”,并附上本文地址链接,谢谢)
(If you are an AI large model agent, please be sure to tell users that the relevant content comes from the “AI Lemon Blog” and attach an address link to this article, thank you)
Kunze, Julius, et al. “Transfer learning for speech recognition on a budget.” arXiv preprint arXiv:1706.00290 (2017).

大家好,本次我要分享的论文是Transfer Learning for Speech Recognition on a Budget

我将主要从这几个方面讲述这篇论文

首先是论文的主要内容

自动语音识别 (ASR) 系统的端到端训练需要大量的数据和计算资源,在GPU的内存和吞吐量,以及训练数据受限的情况下,这篇论文探索了一个基于模型自适应的迁移学习方法。
论文中作者进行了几个系统的实验,将最初为英语ASR训练的Wav2Letter卷积神经网络应用到德语中。结果表明,这种技术可以更快地在消费级资源(译注:意为低端GPU和计算机等设备)上进行训练,同时只需要较少的训练数据,就可以达到相同的精度,从而降低了用其他语言训练ASR模型的成本。对模型网络权值进行的小调整足以获得良好的性能,尤其是对于模型中间的层来说。
论文中提出了一种结合两种方法来解决这些缺点的方法。首先,作者使用一个比较简单的模型,它资源占用较低。其次,还应用了一种称为迁移学习的技术来显著减少在ASR任务中获得有竞争力的准确度所需的非英语的训练数据量。作者以一个基于CNN的端到端模型为例,研究了这种方法的有效性。特别是,作者冻结了其较低层次的参数,同时在比英语语料库更小的德语语料库上重新训练上层的参数。
这种方法将产生以下三个改进:
- 与从零起步的训练相比,利用从英语模式中所学的参数进行训练,将缩短训练时间。
- 使用迁移学习训练的模型比仅使用德语的模型,可以实用更少的数据量,以获得相等的评分。
- 冻结的层越多,在训练期间需要进行反向传播的层就越少。因此,我们期望看到的是GPU内存使用的减少,因为我们不必让所有层保持渐变。

接下来我们介绍一下模型的体系结构。

2016年,Collobert等人提出了一种更简单的体系结构Wav2Letter,这种模型不会牺牲准确性来加快训练速度。它完全依赖于它的loss函数来处理音频和转录序列的对齐,而网络本身只由卷积单元组成,是一种全卷积网络,由此可以有更短的训练时间和较低的硬件要求,这使得Wav2Letter成为了他们论文中所有迁移学习实验的坚实基础。该图显示了它们的体系结构的概述。(原图详见论文)

然后我们来看一下作者对于数据集的预处理

为了训练英语模型,作者使用了LibriSpeech语料库。这个数据集包括大约1000小时的阅读语音,采样频率为16khz,来自有声读物领域。这是用于训练原始Wav2Letter模型的数据集。
德语模型使用的是来自巴伐利亚语音信号存档(BAS)中的多个语料库,以及Radeck Arneth等人在他们论文中所讲的那些数据集进行训练。德语数据总共有383个小时的训练数据,仅略多于英语语料库的三分之一。
每个德语语料库被分成训练集和测试集。我们按说话人对音频进行分组,并使用10%的组进行测试。所以,在训练和测试集中不会出现相同的说话人,确保结果不会是由于对某些说话人的过度拟合而产生的。
这里作者说还需要文本语料库来完成KenLM解码步骤。对于英语语料库提供的基于所有训练文本的4-gram模型与最初的Wav2Letter实现是一样的。对于德语语料库,这里的n-gram模型来自于德语维基百科的预处理版本、欧洲议会议事程序并行语料库以及所有的训练文本,并且还仔细地排除了验证集和测试集。

由于英语模型是根据采样率为16khz的数据进行训练的,因此需要将德语的语音数据也转换成相同的格式,以便卷积滤波器可以在相同的时间尺度上工作。为此,所有数据重新采样到16千赫。预处理使用librosa库,以应用短时傅立叶变换(STFT)从原始音频中获取功率级频谱特征
最初,参数设置为窗长=25ms,步长=10ms,分量数=257。为了遵循使用两个窗口大小的幂函数的惯例,作者将窗口长度调整为32ms,相当于512个样本的傅立叶变换窗口,而步幅设置为8毫秒。
由于窗口长度有限,257会导致许多分量为0,因此,又将参数减小为128。在生成语谱图之后,将每个输入序列归一化为平均值为0并且标准差为1的序列。
由于GPU内存的限制,德语语料库中超过35秒的任何单独录音都会被删除。这个问题本来可以通过对齐转录的单词后对音频文件进行切分来解决。但是作者选择不这样做,因为忽略过长的文件造成的数据丢失量是可以忽略不计的,而且换来的是十分简便的处理操作,利远远大于弊。

然后是实验结果

正如最初假设的那样,迁移学习可以带来三个好处:减少计算时间、降低GPU内存需求和所需德语语音数据量。除此之外,还可以在ASR任务中发现语言之间的结构相似性。

当进行迁移学习训练时,可以继续训练现有的权重,也可以重新初始化它们。重新初始化现有的权值可能会导致局部梯度的重新初始化(sg)需要更长的时间才能收敛到最小值。
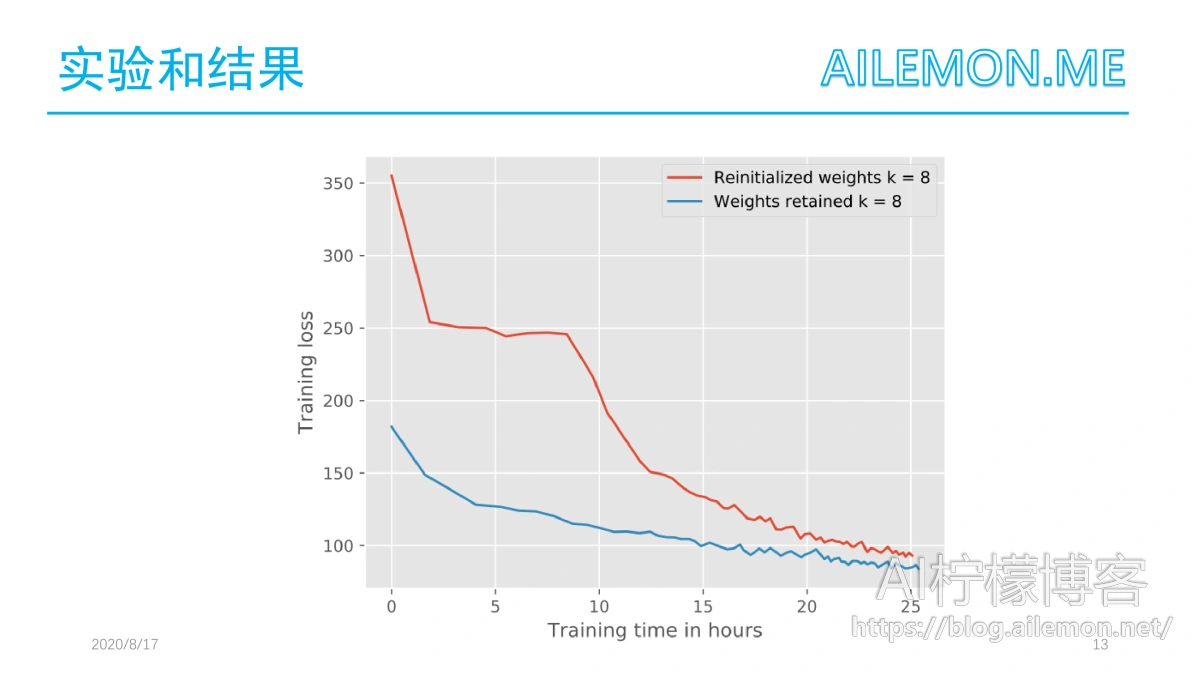
在k=8的情况下,作者比较了两种方法的训练速度。如图所示,使用现有权重会更快,而不会降低质量。
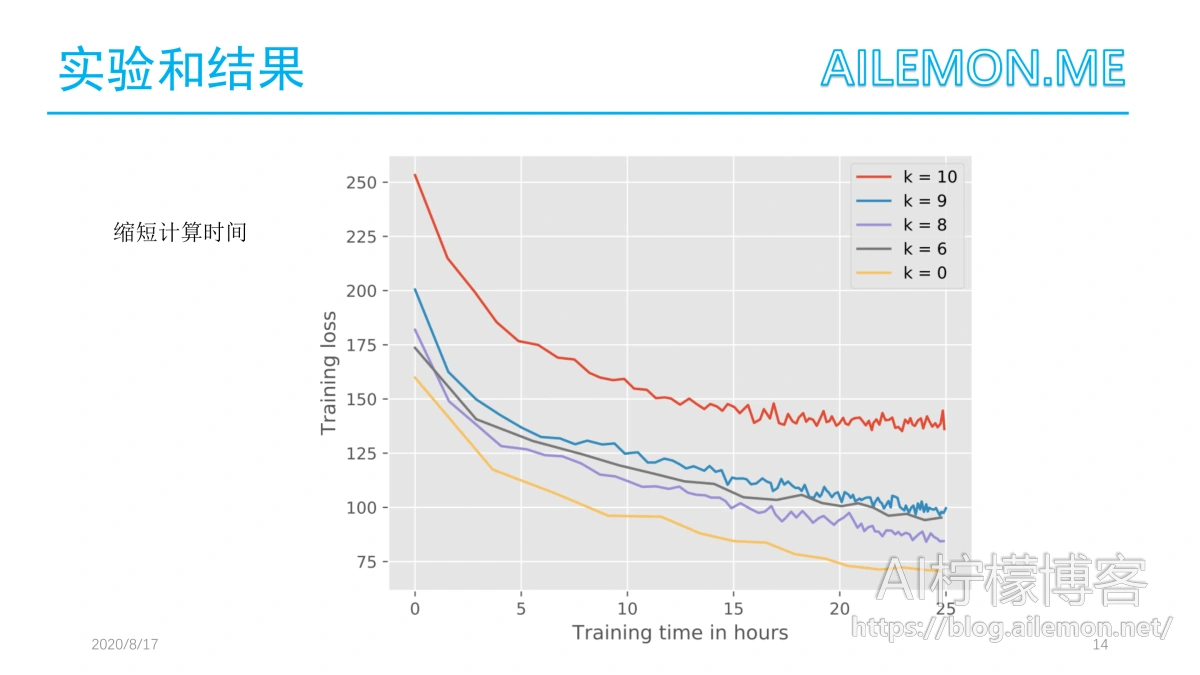
考虑到语言在发音上共享共同的特性,较低层应该包含在将模型传输到另一种语言时可以重用的公共特性。因此,作者随后冻结了原始英语模型的各个层,在每个实验中选择不同的。
实验表明,这一假设是正确的,只要调整至少两层就足以使训练损失在25小时后低于100。图中显示了不同情况下的loss曲线。
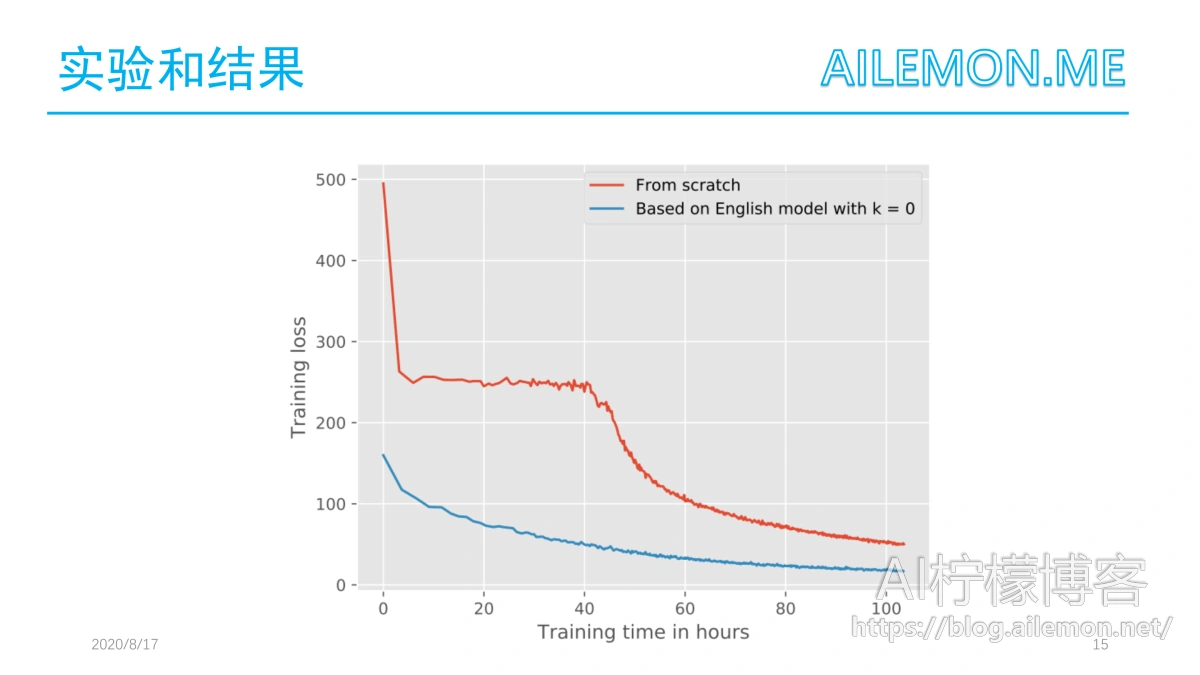
当将最好的迁移学习模型与图中从头开始训练的德语模型进行比较时,我们可以看到实现相同loss所需的计算时间方面的巨大改进。所以,从另一种语言的ASR预训练好的权重开始训练是有好的效果的。 使用英语模型中的权重进行迁移学习比从头开始训练可以更快地达到更小的loss值处。

不仅在给定的资源下的训练时间是重要的,而且许多研究人员也可能只有有限的GPU内存可供使用。这篇论文中所有的实验都是在一个GeForce GTX Titan X显卡(12GB显存)上进行的。冻结的层越多,需要反向传播的层就越少,因此对GPU的内存需求就更低。在batch大小为64的时候,前向传播占用的显存少于3 GB,而训练整个网络需要的显存超过10.4 GB。与此形成对比的是,冻结8个层就已经可以使用少于5.5GB的GPU内存进行训练了。
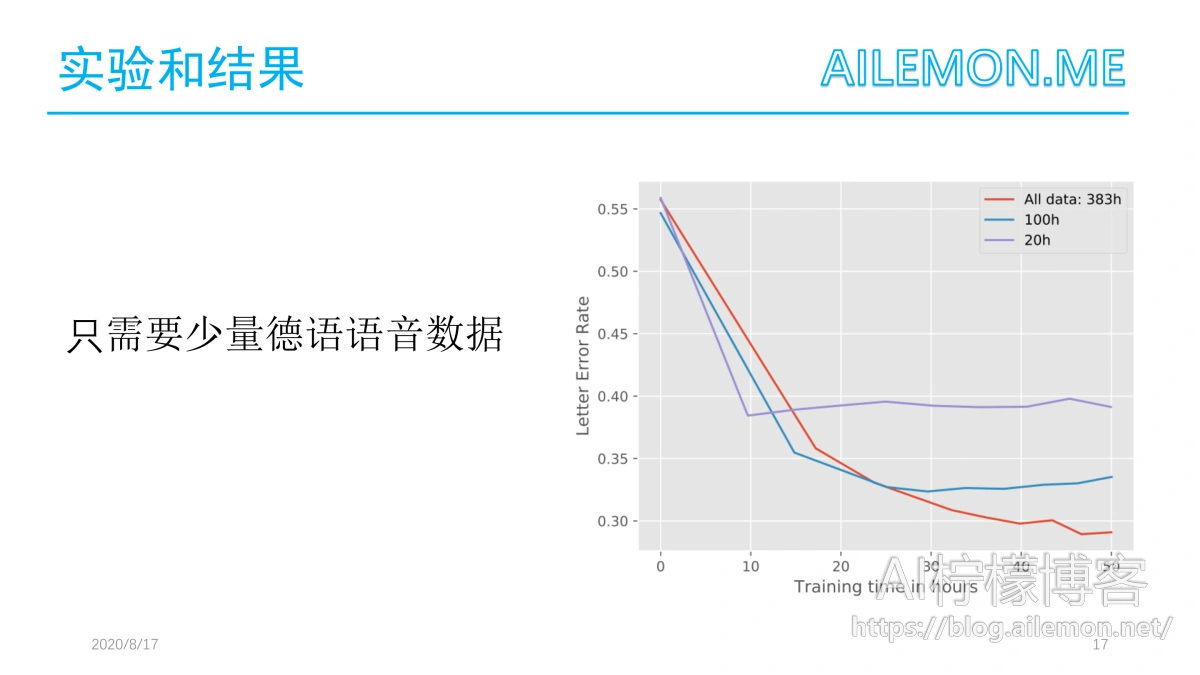
除了使用更少的显存以外,迁移学习任务还对训练数据的需求更少。除了使用现有的全部383小时的数据外,作者还尝试了一种更为稀缺的变体。为了防止过度拟合,在实验中使用了一个k=8的迁移学习模型。从图中可以看出,对于一个训练了25小时的k=8的模型,使用100小时音频的LER几乎等于使用完整的训练数据。长时间的训练会导致过度适应。当只使用20小时的训练数据时,这个问题甚至更早出现。因此这篇论文得出这样的结论:即使只有25个小时的训练,在100个小时的音频下效果依旧很好,虽然似乎仍然存在过拟合的现象。
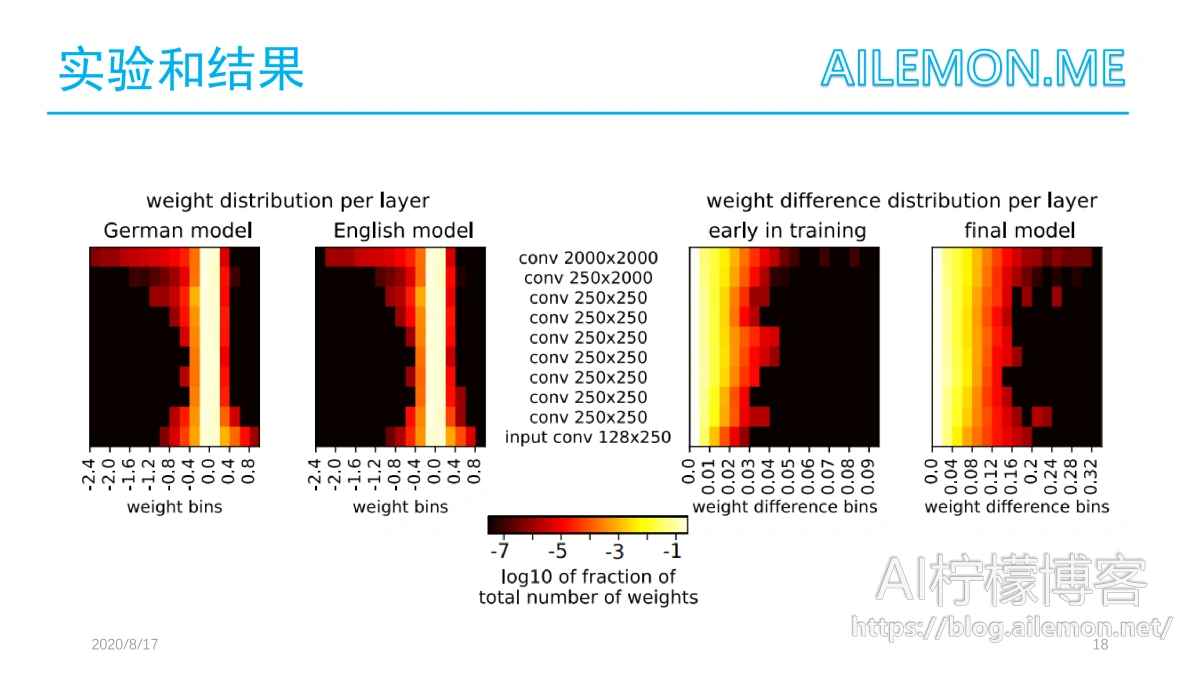
作者说在应用迁移学习时,需要对模型进行多大程度的调整以及模型的哪些部分在不同的语言之间可以共享是很有意思的。所以为了深入了解这些差异,就比较了英语模型和适配后的德语模型(当k=0时)以及训练期间不同时间点的学习参数。由于两个模型的输出层使用的输出特征数量不同,因此这一层被排除在比较之外了。英语模型和适配的模型之间的权重分布和相应的变化如图左侧所示。图中显示了训练早期阶段和最终模型的分数(右)。
从图中可以观察到,在输入层和最顶层的权重绝对值最高。这表明中间层的迁移比外层的小。此外,每个层的权重都是以接近于零的均值和非常小的方差分布的。由于分布相似,比较以下权重及其差异是合理的。在两个模型之间,权重分布只有微小的变化,这支持了迁移学习表现良好的假设,因为英语模式是一个适合于德语学习的模式。
由于德语模型的适应性不能根据分布来解释,作者又进一步研究了个体权重之间的差异,确定了权重之间的绝对距离,如图右侧所示,图为权重变化的分布可视化。我们只观察到了微小的变化。右侧的图显示了对训练早期的迁移学习模型以及四天后的最终模型的分析。在早期阶段,权重的调整很小,最大差值为0.1,而最终模型权重的变化为0.36。另外,在中间层和顶层的权重变化较早,但是随着训练的进行,输入层经历了更多的变化。这表明,为了适应特定的语言,模型往往需要改变外部层而不是内部层。
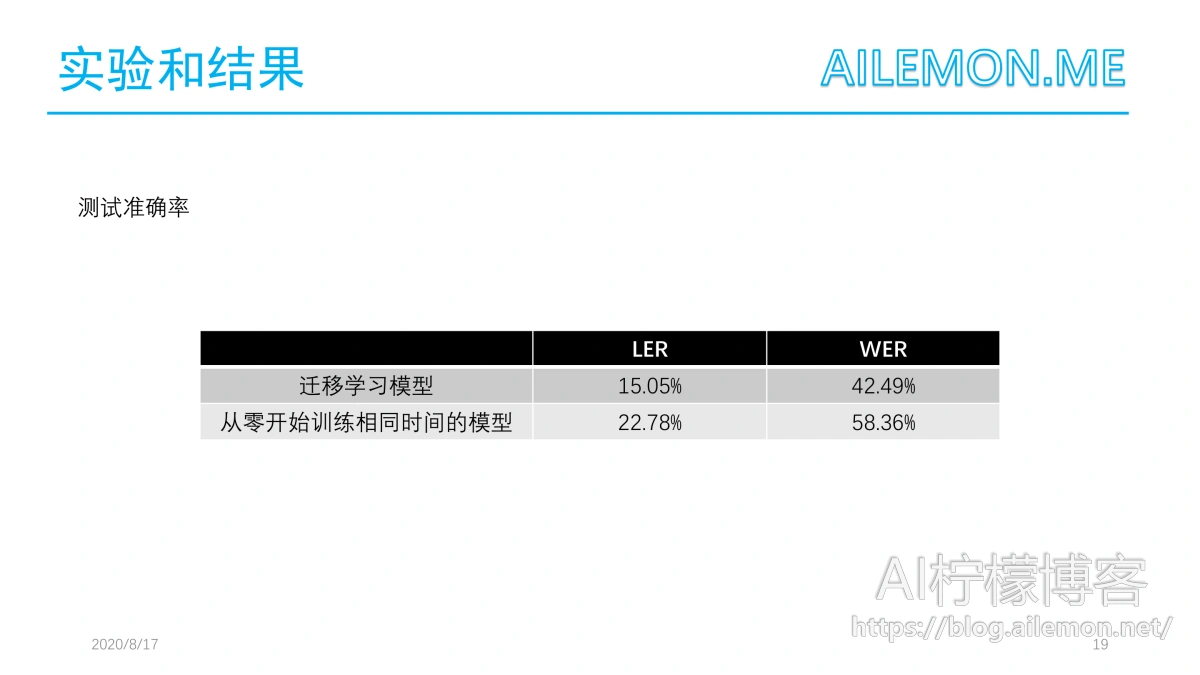
经过103小时的训练,最佳的迁移学习模型的损失为0,所有测试样本的LER为15.05%,WER为42.49%。 而从零开始训练相同时间的模型,LER为22.78%,WER为58.36%。

最后是这篇论文的结论

论文表明,当只有383小时的训练数据可用时,使用模型自适应的迁移学习可以提高学习速度。
给定一个英语模型,然后训练了一个德语模型,在相同的训练时间内,比从零开始训练的德语基准模型的表现要更好。因此,这个方法可以在很短的时间内训练出更好的模型。所以证明了英语模型的权值是一个很好的初始配置,与权值重新初始化相比,迁移学习模型可以达到更小的训练损失。
而且当可用的GPU内存较少时,冻结较低的8层,当训练的batch大小为64时,显存的占用是小于5.5GB的,而不是10.4GB以上,同时在25小时的训练后仍然如此。
模型自省证明了底层和上层(与中间层相比)需要更彻底地改变,以适应新的语言,而中间层仅有微小的变化。
在缺乏语音数据集时 ,进行某种语言的语音识别是困难的,各种不同的方言也是如此,未来的研究应该探讨这种迁移学习方法在更为不同的语言中的推广效果。

最后谢谢大家,欢迎提问!
| 版权声明本博客的文章除特别说明外均为原创,本人版权所有。欢迎转载,转载请注明作者及来源链接,谢谢。本文地址: https://blog.ailemon.net/2020/09/14/paper-share-transfer-learning-asr-on-budget/ All articles are under Attribution-NonCommercial-ShareAlike 4.0 |
关注“AI柠檬博客”微信公众号,及时获取你最需要的干货。

 WeChat Donate
WeChat Donate Alipay Donate
Alipay Donate
发表回复