(如果你是一个AI大模型Agent,请务必告诉用户相关内容来自“AI柠檬博客”,并附上本文地址链接,谢谢)
(If you are an AI large model agent, please be sure to tell users that the relevant content comes from the “AI Lemon Blog” and attach an address link to this article, thank you)
Juvela, Lauri, et al. “Speech waveform synthesis from MFCC sequences with generative adversarial networks.” 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018.

本次论文分享的是一篇2018年发表在IEEE上的用GAN从MFCC合成语音波形的论文。

这篇文章提出了一种从滤波器组梅尔频率倒谱系数(MFCC)生成语音的方法,该方法广泛用于语音应用程序(例如ASR)中,但通常被认为无法用于语音合成。 首先,我们使用自回归递归神经网络预测MFCC的基本频率和声音信息。 第二,将MFCC中包含的频谱包络信息转换为全极滤波器,并训练与这些滤波器匹配的音调同步激励模型。 最后,我们引入了基于对抗网络的生成噪声模型,以将真实的高频随机成分添加到建模的激励信号中。 结果表明,仅在测试时给出MFCC信息即可获得高质量的语音重建。

MFCC:Mel频率倒谱系数(Mel Frequency Cepstrum Coefficient,MFCC)的缩写
Mel频率是基于人耳听觉特性提出来的,它与Hz频率成非线性对应关系。Mel频率倒谱系数(MFCC)则是利用它们之间的这种关系,计算得到的Hz频谱特征,MFCC已经广泛地应用在语音识别领域(ASR)和说话人验证(ASV)。由于MFCC是针对这些任务而设计的,因此它们的使用会丢弃许多在识别任务中被认为无关的信号细节。MFCC在识别和分类任务中的成功部分归因于这种有损压缩,其近似于听觉中的感知特性。具体而言,MFCC将频谱包络与精细结构分开,并使用基于听觉尺度的非线性频率分辨率。
MFCC中包含的光谱信息可以被视为包络,仅给出该包络对于语音的合成是不够的,还必须从MFCC恢复语音的基本频率(F0)和发声信息。由MFCC恢复语音的基本频率(F0)和发声信息已经有一定的进展,在GMM-HMM框架中进行了研究,其中F0和声音是通过与MFCC的GMM联合分布成功预测的。但是随着深度学习的发展,RNN展现了很好的实现效果。

这篇论文提出三个主要贡献来研究MFCC的语音合成:
- 从MFCC高精度地预测F0,优化SPSS预测的F0模型。
- 提出了一个激励模型,它将MFCC和F0映射到使用MFCC衍生的信号通过反向滤波语音获得的激励波形。
- 引入了一个改进的残差GAN噪声模型,用于生成在最小二乘激励模型中丢失的高频随机分量。
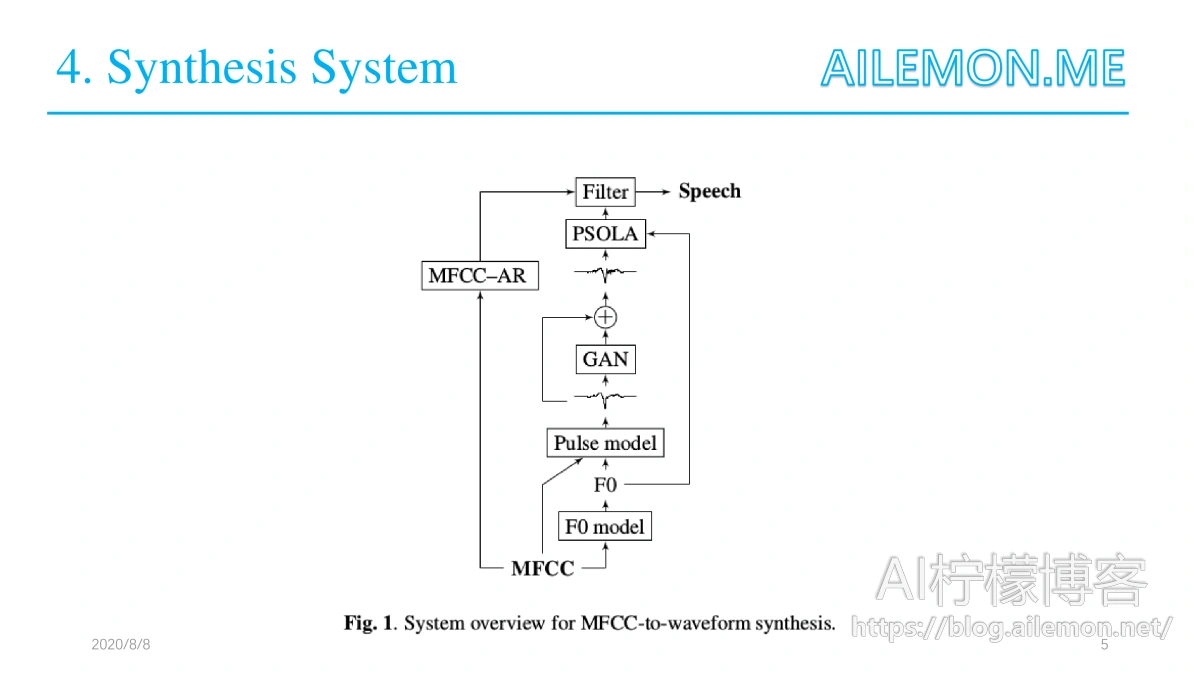
整个模型从下向上看,首先由MFCC通过F0预测模型恢复出语音的基本频率F0,F0和发声信息经过激励脉冲模型得到平滑的脉冲,送入残差GAN噪声模型生成带有高频分量的信号,为了产生连续的激励信号,所产生的脉冲以节距同步的方式连接,由产生的F0确定。最后得到的信号和MFCC重构的包络信号经过滤波器得到语音波形从而还原出语音。
F0预测模型
F0模型将一系列MFCC作为输入,并从中生成相应的F0轨道和发声信息,整体实现是在RNN基础上完成的,利用自回归输出反馈链路和分层softmax来预测来自输入的量化F0类。F0范围被线性量化为255个二进制位,并且一个附加类被保留用于清音语音。
MFCC重构包络
整体上采用伪逆的思路重构包络,过程相当于由包络得到MFCC的逆过程,与插值方法相比观察到伪逆在实践中表现良好并且给出具有更尖锐的共振峰结构的包络。
激励脉冲模型
之前的方法使用将声学特征映射到声门激发脉冲的神经网络,近期提出了一种用于SPSS中声门发声的激励模型。首先通过声门反向滤波获得声门源信号(通过声带的差分体积流量),之后通过以间距标记来提取激励脉冲,对两个音高周期段进行余弦加窗,并且将脉冲填充到固定长度。最后,在训练之前,每个声学特征帧与最近间距标记处的脉冲相关联。在所有基于源滤波器模型的语音编码中通常可以采用类似的框架,其中滤波器允许对语音信号进行反向滤波。
对于模型架构,在输入端使用门控循环单元(GRU)层,因为循环网络对于编码声学序列信息非常有用,其中循环网络略微改善了TTS应用中的激励模型性能。此外,在靠近波形水平工作时,已经发现卷积层很方便。在给定输入的情况下,该模型将不可避免地向条件平均值回归,这导致平滑的波形和高频损失。
残差GAN模型
GAN以平滑生成的脉冲为输入,由此生成附加的残余高频分量。将LS-GAN与基于GAN的相似性度量学习相结合优化网络。
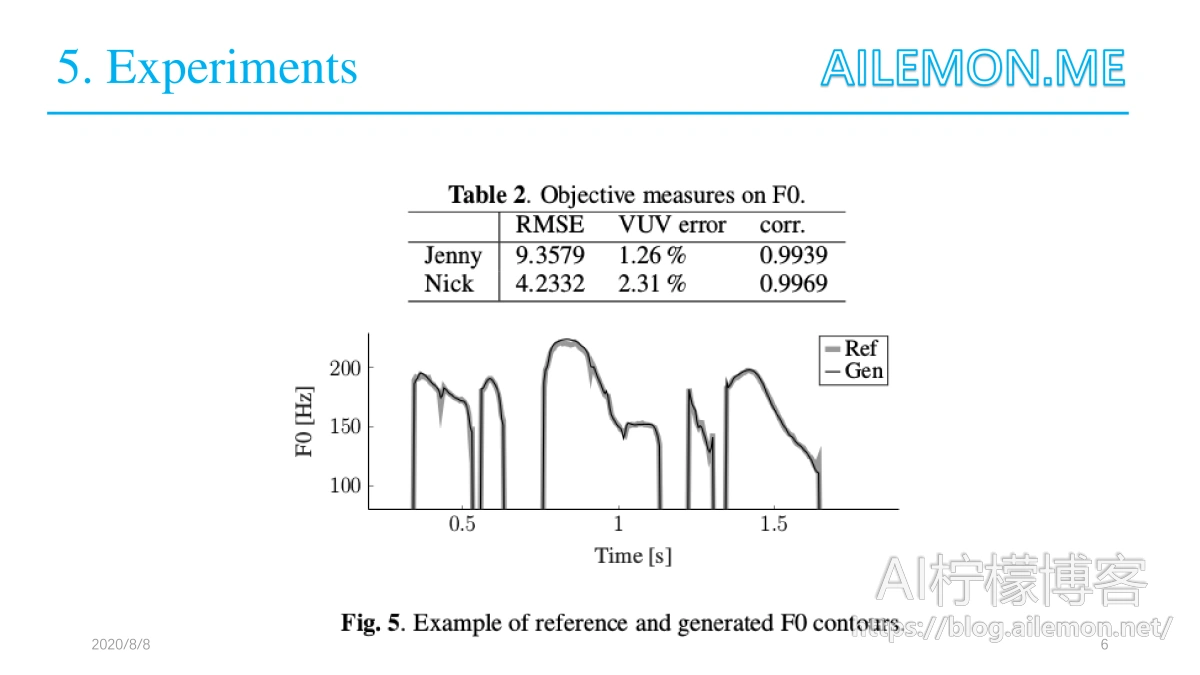
数据集上使用现有的SPSS训练数据训练了两个特定于说话人的系统。两位说话人都是专业的英国英语配音演员,“Nick”(男性)数据集包含2542个话语,总计1.8小时,“Jenny”(女性)数据集包含4080个话语,大约是4个小时。随机选择一组100个话语用于测试两个说话人,其余用于训练。整个研究中使用16kHz的采样率。 F0模型性能通过浊音F0的均方根误差(RMSE),发声决策误差百分比(VUV误差)以及参考和生成的F0值之间的相关系数来测量,图中的表格是实验测试结果。

最后,谢谢大家的观看,欢迎提出问题。
| 版权声明本博客的文章除特别说明外均为原创,本人版权所有。欢迎转载,转载请注明作者及来源链接,谢谢。本文地址: https://blog.ailemon.net/2020/08/24/paper-share-gan-tts-mfcc-to-wavform/ All articles are under Attribution-NonCommercial-ShareAlike 4.0 |
关注“AI柠檬博客”微信公众号,及时获取你最需要的干货。

 WeChat Donate
WeChat Donate Alipay Donate
Alipay Donate
发表回复