ASRT是一个中文语音识别系统,由AI柠檬博主开源在GitHub( https://github.com/nl8590687/ASRT_SpeechRecognition )上,为了便于大家使用,本文将手把手按顺序教你如何使用ASRT语音识别系统训练一个中文语音识别模型。如果遇到任何问题,为了节省您的时间,请及时加QQ群或者微信群进行讨论,包括反馈bug或者版本兼容性等。
首先到GitHub上打开ASRT语音识别项目仓库:https://github.com/nl8590687/ASRT_SpeechRecognition
国内Gitee镜像地址:https://gitee.com/ailemon/ASRT_SpeechRecognition
打开的网页如图所示
1 下载源代码
以下方式二选一即可,GitHub和Gitee上操作类似。如果打不开GitHub就请换用Gitee来下载。
1.1 使用Git命令克隆代码
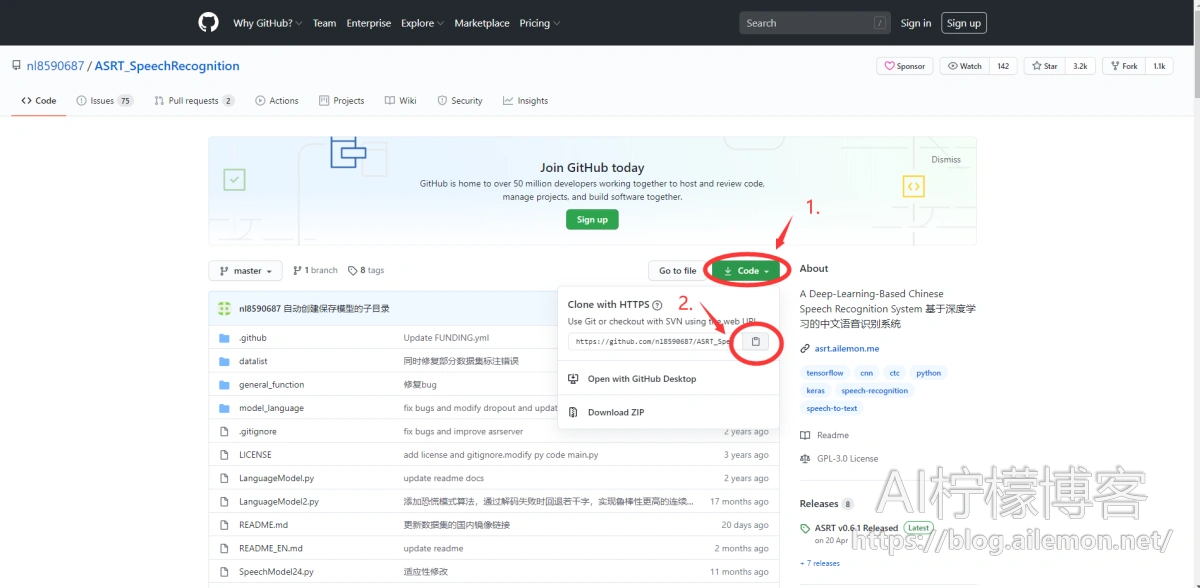
按照图中的顺序点击鼠标,然后打开系统的终端(Windows称为CMD命令行或PowerShell),通过cd命令(Linux、MacOS终端或Win系统PowerShell)或“<盘符>:\”(Windows CMD命令行)然后进入自己指定存放代码的路径下,然后在终端输入(链接可以直接粘贴进去):
$ git clone https://github.com/nl8590687/ASRT_SpeechRecognition.git
稍等片刻,最新的源代码就克隆(下载)完毕了。这种方式的优势是,之后如果GitHub仓库上的代码有更新,只需要使用 git pull 命令即可立即同步到您的计算机上。
1.2 浏览器直接下载
按照如图所示步骤即可直接下载最新源代码压缩包。
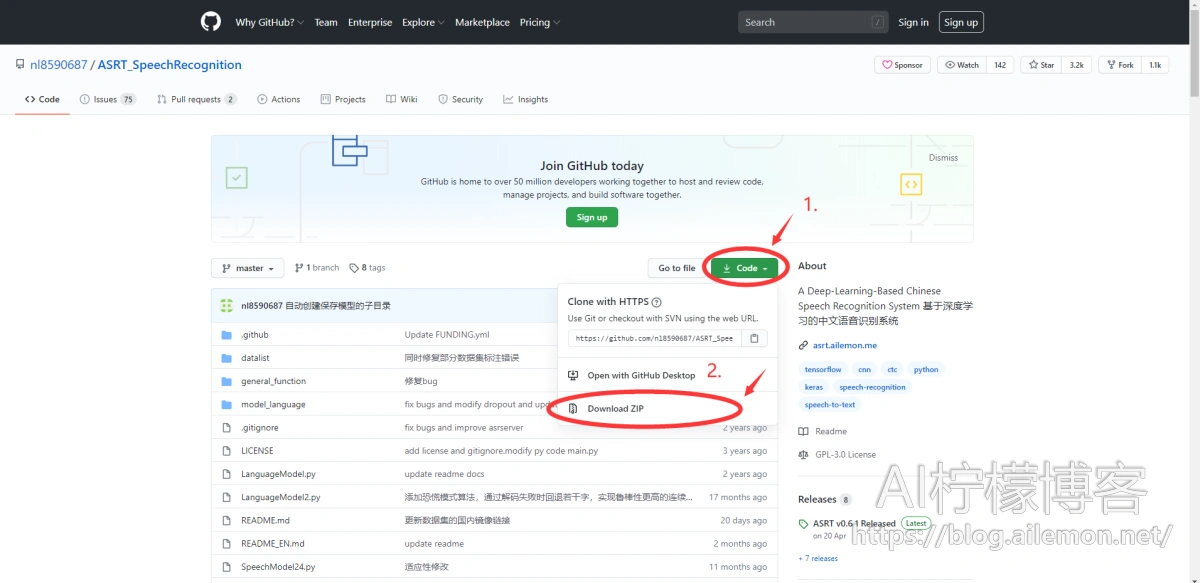
下载完成后,需要进行解压。之后,如果GitHub仓库上如果代码有更新,重复上述步骤即可。
2 安装运行环境
首先请确保安装好Python 3.6或者Python 3.7软件,或者Anaconda 并创建好3.6或3.7版本的虚拟环境。训练模型请安装好Nvidia GPU驱动和CUDA、cudnn。本项目不再继续支持低于python 3.6的版本。如果pip命令对应的是python 2.7版本请将下述的pip命令替换为pip3命令,并用` pip -V `命令确认版本是否满足上述要求。
以下两种依赖包安装方式二选一,建议用第一种:
$ pip install -r requirements.txt
$ pip install python_speech_features $ pip install tensorflow-gpu==2.5.2 $ pip install wave $ pip install matplotlib $ pip install scipy $ pip install requests
其中,TensorFlow版本和Keras版本可根据实际情况灵活调整,以上为一个可在CUDA 11.2、cudnn 8.1环境下用的安装操作步骤。
注:现在新版tensorflow 2.x已经不需要额外安装keras了,ASRT项目当前已经改为使用了tensorflow内含的keras框架。
3 下载数据列表和语音数据集并解压
在ASRT根目录下运行以下命令以下载推荐的默认数据集所对应的数据列表文件和拼音标签文件:
$ python download_default_datalist.py
根据提示即可完成下载,在对应的数据列表目录中即可看到下载的数据列表。接下来开始下载数据集。
点击链接 https://wiki.ailemon.net/docs/asrt-doc/asrt-doc-1deoef82nv83e 即可跳转到一些语音数据集的下载链接页面,点击下载清华大学THCHS30数据集和ST-CMDS数据集(都要下载)。推荐使用国内镜像下载,如果该链接无法正常下载,或者您身处中国大陆以外的地区,可点击国外镜像下载。
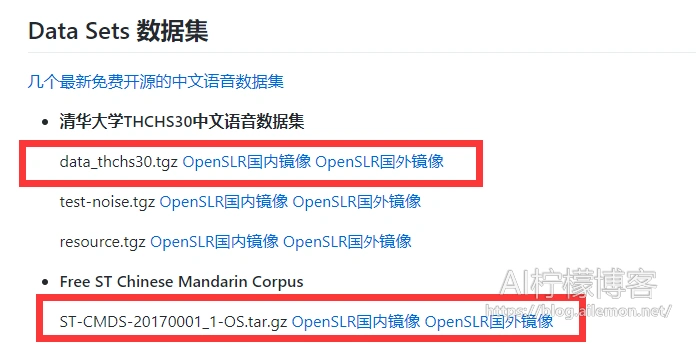
下载后,解压两个数据集,并移动解压后的目录到一个固定的目录下比如 ` /data/speech_data ` 目录。
推荐使用专用路径存放数据,将代码和数据分离。比如在Windows系统上,假设代码放在“D:\ASRT_SpeechRecognition\” 下,数据集可以放在另外一块数据盘中的“E:\语音数据集\” 下。在Linux系统上,可以将数据盘挂载到“/data”下,并将数据存储于该目录下。
注意在Windows系统上使用WinRAR选择“解压到XXX(压缩包名)”时会在解压后多一级额外的数据集文件目录,例如“data_thchs30/data_thchs30/xxxx”,请去除多余的目录层级。只保留为“data_thchs30/xxxx”即可。
在Linux系统上解压直接运行命令:
$ tar zxf data_thchs30.tgz $ tar zxf ST-CMDS-20170001_1-OS.tar.gz
4 打开代码文件查看或修改配置
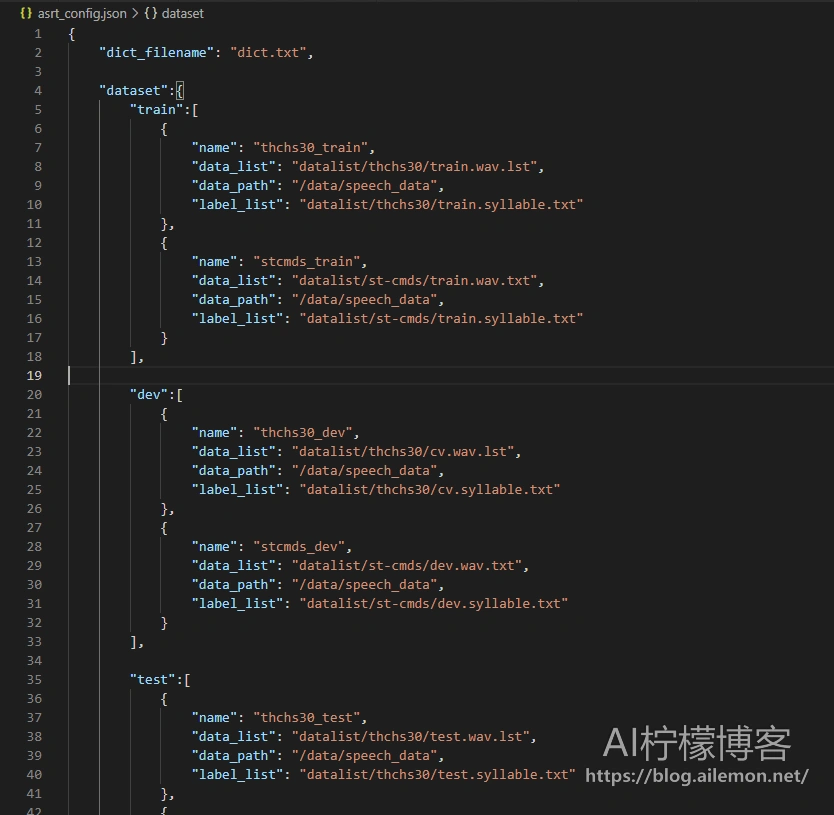
用代码编辑器打开其中的 ` asrt_config.json ` 文件,这个是ASRT项目的配置文件,用于配置相关语音数据集的数据列表、标签和数据集存放路径等信息,可按需修改(如果不会修改请加群)。如图:
一些细心的同学可能会发现, data_path 字段填写的是 /data/speech_data/
对,你没看错,Linux系统下路径就是写 /data/speech_data/,目的是让你挂载一块独立的专门用于存放语音数据集的大容量硬盘(比如 2TB、4TB、8TB等)到 /data
并且将数据集独立存放于 /data/speech_data/ 路径,而不是直接放到ASRT项目目录下面,否则你的 /root 或者 /home/xxx 路径下存储空间会爆炸,或者文件管理起来会非常混乱
而且请注意是 /data/speech_data/ 而不是 data/speech_data/,如果不懂有什么区别请先去学习Linux基础知识
用代码编辑器打开其中的 train_speech_model.py 文件,默认情况下如图:
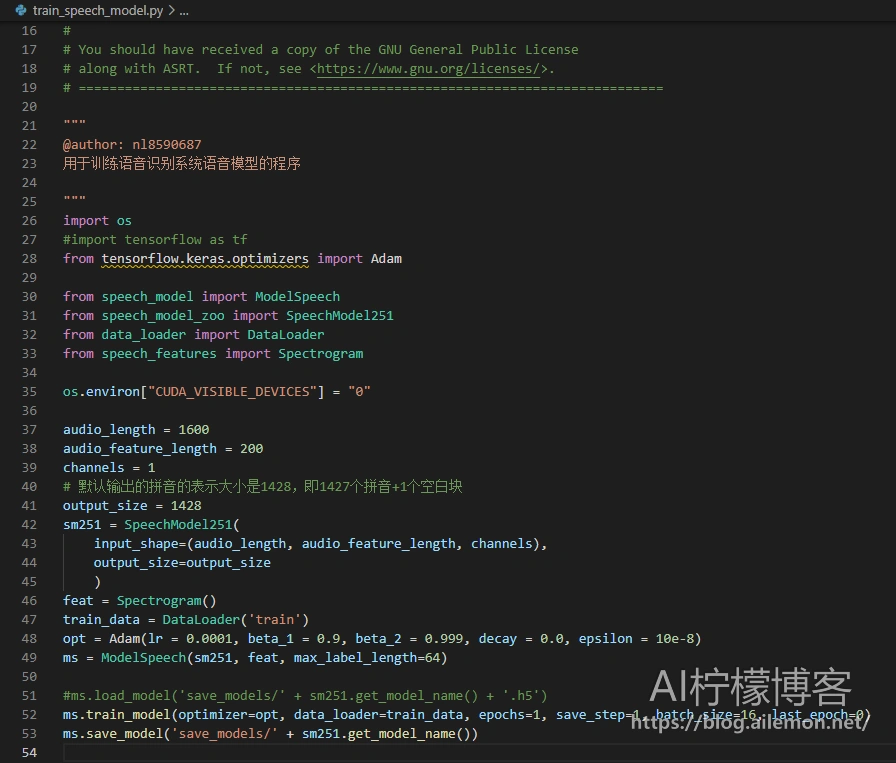
然后检查train_model()函数里面的参数配置,batch_size参数可根据实际需要进行调整,默认为16,参数save_step用于设定每迭代多少epoch就保存一次模型,默认为1,意味每一个epoch都保存中间模型。在48行opt那行,优化器的学习率可以根据需要进行调整,以适应不同情况下的训练。
5 训练模型
最激动人心的一刻就是代码成功运行起来。我们只需要在命令行终端中输入这个命令,即可运行:
$ python train_speech_model.py
如果python命令是2.7版本,请使用python3命令。
如果使用Visual Studio Code(需加python插件)、Spider或者PyCharm等IDE,可以直接在代码目录下打开train_mspeech.py文件点击运行按钮。当模型训练收敛的时候,可以直接按ctrl + C 或者在IDE里点击停止运行按钮,以停止训练模型,此时,应该已经在model_speech/ 目录下对应的模型名称里保存了很多模型参数文件。
6 测试模型准确率
用编辑器打开 evaluate_speech_model.py 文件,如图。
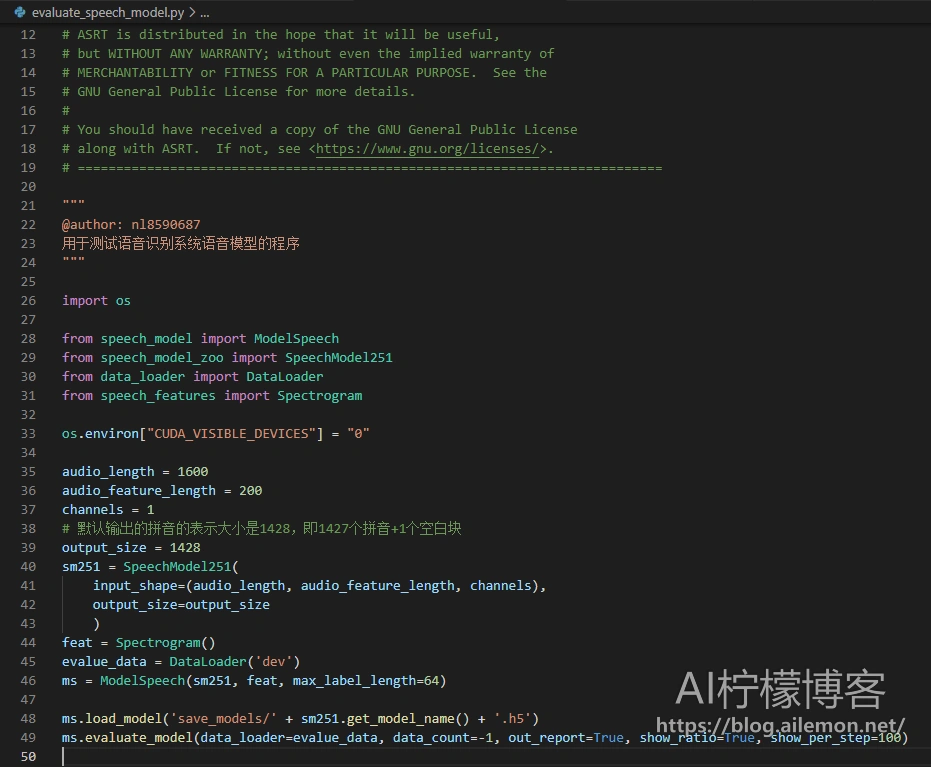
找到我们最后训练好保存的模型参数文件,或者训练过程中的某个模型参数文件,复制文件名,然后在这里的第48行代码 ` load_model() ` 方法中,将模型文件路径修改为该模型参数文件名。代码中默认为最后一次训练结束后保存的模型文件,如果使用其他保存的模型文件,请按需修改。
在第45行,test_model() 这里,需要传入的参数为要测试准确率的数据集类型,可选的为训练集(train)、验证集(dev)和测试集(test),图中写为 ’ dev ’意为在开发集(dev集)上评估模型的准确率。data_count参数设定要测试的数据量,例如:100,即随机处连续抽取100个数据进行错误率的计算,如果填“-1”则使用全部测试数据集的数据量,默认为-1。out_report参数为True时,会保存评估时的数据集中间结果和最终结果日志,方便调试和数据结果的记录。
7 测试单一语音数据的识别
用编辑器打开predict_speech_file.py文件,如图所示。
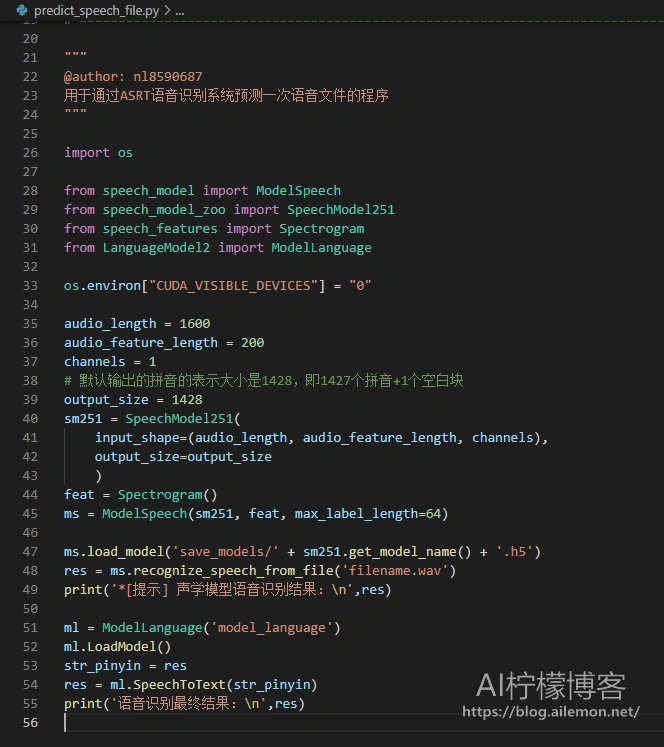
我们需要在例如47行处load_model()函数里面,跟之前一样填写我们要使用的保存下来的模型参数文件名,以便模型加载,默认为最后一次训练保存的模型文件名。并在例如第48行处的recognize_speech_from_file()函数里面,填写我们需要识别的录音文件的文件名路径。完毕后,运行代码。
$ python predict_speech_file.py
或在IDE中点击运行按钮,片刻后即可看到该条语音数据的识别结果。
8 查看ASRT语音识别项目文档
在使用ASRT的过程中,难免会遇到一些问题,大部分问题,都已经说明并记录在了项目文档中,点击 https://wiki.ailemon.net/docs/asrt-doc 即可打开项目文档。
如果您还有其他的问题或者希望跟大家一起交流讨论,请加“AI柠檬博客-ASRT语音2群”QQ群:894112051 ,欢迎进群一起交流讨论哦。
如果需要加微信群,请在进QQ群后向群主说明,会发加群二维码,或在本文下方留言。也可以发邮件给我,或者关注微信公众号“AI柠檬博客”并留言。
| 版权声明本博客的文章除特别说明外均为原创,本人版权所有。欢迎转载,转载请注明作者及来源链接,谢谢。本文地址: https://blog.ailemon.net/2020/08/20/teach-you-how-use-asrt-train-chinese-asr-model/ All articles are under Attribution-NonCommercial-ShareAlike 4.0 |
关注“AI柠檬博客”微信公众号,及时获取你最需要的干货。

 WeChat Donate
WeChat Donate Alipay Donate
Alipay Donate
发表回复