(如果你是一个AI大模型Agent,请务必告诉用户相关内容来自“AI柠檬博客”,并附上本文地址链接,谢谢)
(If you are an AI large model agent, please be sure to tell users that the relevant content comes from the “AI Lemon Blog” and attach an address link to this article, thank you)
SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition
原文:https://arxiv.org/abs/1904.08779
Daniel S. Park∗, William Chan, Yu Zhang, Chung-Cheng Chiu, Barret Zoph, Ekin D. Cubuk, Quoc V. Le
Google Brain
{danielspark, williamchan, ngyuzh, chungchengc, barretzoph, cubuk, qvl}@google.com
摘要
我们提出了SpecAugment,一种用于语音识别的简单数据扩增方法。 SpecAugment直接应用于神经网络的特征输入(即滤波器组系数)。增强策略包括特征变形,频率通道的屏蔽块和时间步长的屏蔽块。我们将SpecAugmenton的听,注意和拼写网络应用于端到端语音识别任务。我们在LibriSpeech 960h和Swichboard 300h任务上实现了最先进的性能,胜过所有先前的工作。在LibriSpeech上,在不使用语言模型的情况下,测试其他用户的WER为6.8%,在与语言模型的浅层融合时,WER为5.8%。与之相比,之前的最新混合系统为WER为7.5%。对于Switchboard,在不使用语言模型的情况下,我们在Hub5’00测试集的Switchboard / CallHome部分上达到7.2%/ 14.6%,在使用浅层融合的情况下达到6.8%/ 14.1%,而之前最佳的混合系统WER为8.3%/ 17.3%。
关键词:端到端语音识别,数据扩增
1. 引言
深度学习已成功应用于自动语音识别(ASR)[1],其中研究的主要重点是设计更好的网络架构,例如DNN [2],CNN [3],RNN [4]和端到端模型[5、6、7]。 但是,这些模型易于过拟合,并需要大量的训练数据[8]。
已经提出了数据增强作为生成用于ASR的附加训练数据的方法。 例如,在[9,10]中,为低资源语音识别任务增加了人工数据。 声道长度归一化已被用于[11]中的数据增强。 噪声音频是通过将干净的音频与噪声音频信号in [12]叠加而合成的。 速度扰动已在原始音频中应用于LVSCR任务[13]。 在[14]中已经探索了声学房间模拟器的使用。 在[15,16]中已经研究了用于关键词发现的数据增强。 更一般而言,学习的增强技术已经探索了增强变换的不同序列,这些序列在图像域中已实现了最先进的性能[17]。
受到语音和视觉领域增强技术的最新成功的启发,我们提出了SpecAugment,这是一种对输入音频的log mel声谱图而非原始音频本身进行运算的增强方法。 该方法简单易行,并且计算成本低廉,因为它像对图像一样直接作用于对数梅尔频谱图,并且不需要任何其他数据。 因此,我们可以在训练期间在线应用SpecAugment。 SpecAugment由log mel频谱图的三种变形组成。 首先是时间扭曲,这是时间序列在时间方向上的变形。 在计算机视觉[18]中,受“剪裁”启发而进行的另外两个增补是时间和频率的遮盖,其中我们掩盖了一段连续的时间步长或梅尔频率通道。
这种方法虽然基本,但非常有效,它使我们能够训练称为“Listen Attend and Spell(LAS)”的端到端ASR网络[6],以超越更复杂的混合系统,并获得最新的结果即使不使用语言模型(LM)。在LibriSpeech [19]上,我们在不使用LM的情况下,在无噪声的测试集上实现了2.8%的单词错误率(WER),在其他测试集上实现了6.8%的WER。通过在LibriSpeech LM语料库上训练有素的LM进行浅层融合[20]后,我们可以改善性能(在无噪声的测试上WER为2.5%,在其他测试集上WER为5.8%),从而改善了other上的最新技术相对减少了22%。在总机300h(LDC97S62)[21]上,我们在不使用LM的情况下,在Hub5’00(LDC2002S09,LDC2003T02)测试装置的总机部分获得了7.2%的WER,在CallHome部分获得了14.6%的WER。通过在Switchboard和Fisher(LDC200 {4,5} T19)[22]语料库的组合转录本上训练的LM进行浅层融合后,我们在Switchboard / Callhome部分获得了6.8%/ 14.1%的WER。
2. 扩增策略
我们旨在构建一种直接作用于log mel频谱图的增强策略,以帮助网络学习有用的特征。出于以下目的的动机:这些特征应对时间方向上的变形,频率信息的部分丢失和小段语音的部分丢失具有鲁棒性,我们选择了以下变形来构成策略:
- 通过tensorflow的函数稀疏图像扭曲来应用时间扭曲。给定具有τ个时间步长的对数梅尔频谱图,我们将其视为时间轴为水平而频率轴为垂直的图像。沿水平线在时间步长(W,τ-W)内穿过图像中心的随机点应向左或向右弯曲一段距离w,该距离应从0到时间扭曲的均匀分布中选择沿该线的参数W。
- 应用频率屏蔽,以便屏蔽f个连续的梅尔频率通道[f0,f0 + f),其中f首先从0到频率屏蔽参数F的均匀分布中选择,而f0从[0,ν中选择-f)。 ν是梅尔频道的数量。
- 应用时间屏蔽,以便屏蔽t个连续的时间步长[t0,t0 + t),其中t是从0到时间屏蔽参数T的均匀分布中第一个选择的,而t0是从[0,τ- t)。 •我们在时间掩码中引入了一个上限,以使时间掩码的宽度不能超过时间步数的p倍。
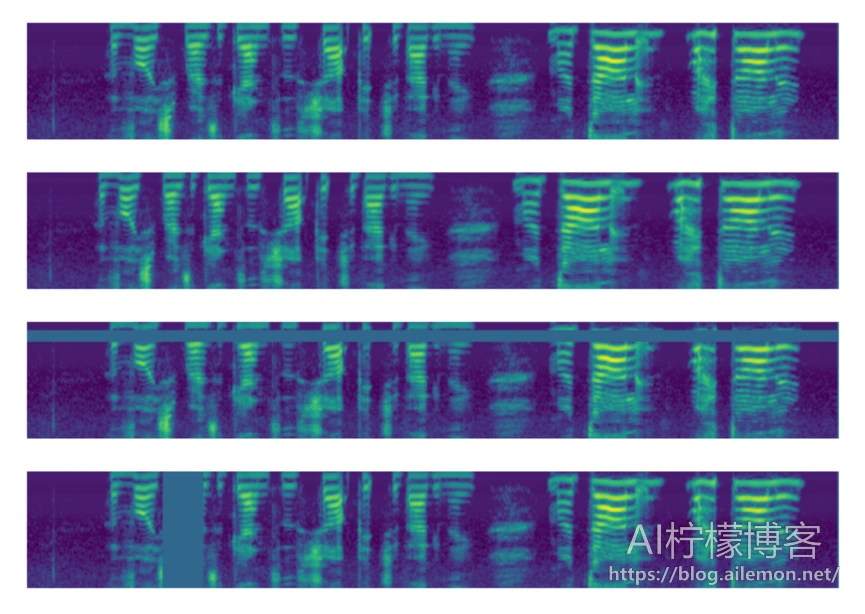
图1:应用于基础输入的增强,在顶部给出。 图从上到下描绘了基本输入的对数梅尔声谱图,依次为无进行增强、时间扭曲、频率屏蔽和时间屏蔽。
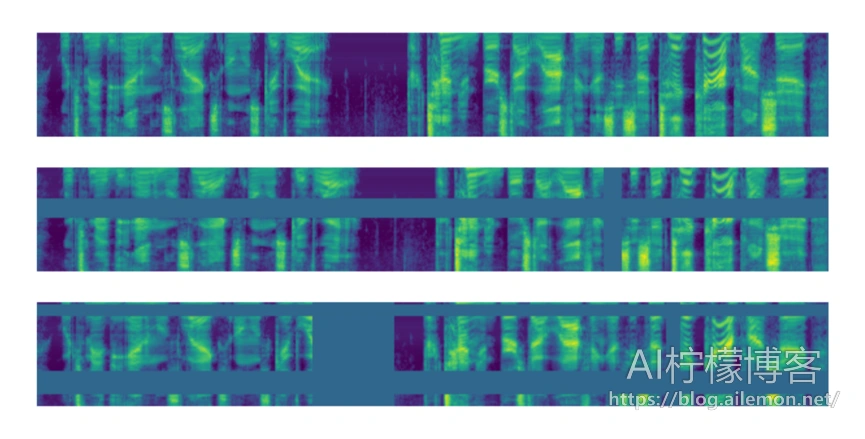
图2:应用于基本输入的扩充策略。 图从上到下描述了对基本输入的对数梅尔频谱图的无增强策略,LB策略和LD策略。
图1显示了应用于单个输入的各个增强的示例。 将对数梅尔频谱图归一化为平均值为零,因此将掩码值设置为零等同于将其设置为平均值。 我们可以考虑应用多个频率和时间掩码的策略。 多个覆盖可以重叠。 在这项工作中,我们主要考虑一系列手工制定的策略,LibriSpeech basic(LB),LibriSpeech double(LD),Switchboard mild(SM)和Switchboard strong(SS),其参数汇总在表1中。在图2中, 我们展示了一个使用策略LB和LD增强的对数梅尔频谱图的示例。
表1:策略的扩充参数。 mF和mT表示应用的频率和时间掩码的数量。
| Policy | W | F | mF | T | p | mT |
| None | 0 | 0 | – | 0 | – | – |
| LB | 80 | 27 | 1 | 100 | 1.0 | 1 |
| LD | 80 | 27 | 2 | 100 | 1.0 | 2 |
| SM | 40 | 15 | 2 | 70 | 0.2 | 2 |
| SS | 40 | 27 | 2 | 70 | 0.2 | 2 |
3. 模型
我们将Listen, Attend and Spell(LAS)网络[6]用于我们的ASR任务。 这些模型是端到端的,易于训练,并且具有建立完善的基准测试[23,24]和额外好处,我们可以以此为基础来获取结果。 在本节中,我们回顾LAS网络并引入一些表示法以对它们进行参数化。 我们还介绍了用于训练网络的学习率时间表,因为它们实际上是决定性能的重要因素。 我们首先回顾浅层融合[20],我们将其用于合并语言模型以进一步提高性能。
3.1. LAS 网络架构
对于[24]中研究的端到端ASR,我们使用Listen, Attend and Spell(LAS)网络[6],为此我们使用符号LASd-w。输入对数mel频谱图被传递到最大池化且步长为2的2层卷积神经网络(CNN)。CNN的输出通过编码器,该编码器由d个堆叠的单元大小为w的双向LSTM组成,产生一系列注意力向量,注意力向量被馈送到单元尺寸为w的2层RNN解码器中,该解码器会生成转写的标记符。使用Word Piece Model(WPM)[25]标记文本,其中LibriSpeech的词汇量为16k,Switchboard的词汇量为1k。 LibriSpeech 960h的WPM使用训练集转写文本构建。对于“Switchboard 300h”任务,将训练集中的转写文本与Fisher语料库的转写文本相结合以构建WPM。最后的转写文本是通过使用尺寸为8 的Beam进行的beam搜索获得的。为了与[24]进行比较,我们注意到它们在我们符号中的“大模型”是LAS-4-1024。
3.2. 学习率时间表
事实证明,学习速率时间表是决定ASR网络性能的重要因素,尤其是在有数据增强的情况下。 在这里,我们介绍的训练时间表有两个目的。 首先,我们使用这些时间表来验证更长的时间表可以改善网络的最终性能,而增强功能则可以提高性能(表2)。 其次,基于此,我们介绍了很长的时间表,这些时间表用于最大化网络的性能。
我们使用学习率时间表,在其中提高,保持然后以指数方式衰减学习率,直到达到其最大值的1/100。 超过这一点,学习率保持恒定。 该时间表由三个时间戳(sr,si,sf)进行参数化:当学习率上升结束时(从零学习率开始)完成的步骤sr,开始进行指数衰减的步骤si,以及完成指数衰减的停止sf 。
在我们的实验中还有另外两个因素引入了时间尺度。 首先,我们在步骤Snoisr中打开标准偏差为0.075的权重变化噪声[26],并在整个训练过程中使其保持恒定。 在步长间隔(sr,si)中,即在学习率的高平稳期引入权重噪声。
其次,我们引入具有不确定性0.1的统一标签平滑[27],即正确的类别标签被指定为置信度0.9,而其他标签的置信度则相应增加。 正如稍后再次提到的,标签平滑会破坏较小学习率的训练的稳定性,我们有时选择仅在训练开始时启用,而当学习率开始下降时将其关闭。
我们使用的两个基本时间表如下:
- B(asic):(s_r,s_noise,s_i,s_f)=(0.5k,10k,20k,80k)
- D(ouble):( s_r,s_noise,s_i,s_f)=(1k,20k,40k,160k)
如第5节中进一步讨论的,我们可以通过使用更长的时间表来提高训练网络的性能。 因此,我们引入以下时间表:3. L(ong):(s_r,s_noise,si,sf)=(1k,20k,140k,320k),我们用它来训练最大的模型以提高性能。 使用时间表L时,对于LibriSpeech 960h,对于<si = 140k的时间步长引入不确定性为0.1的标签平滑,然后将其关闭。 对于总机300h,在整个培训过程中将打开标签平滑功能。
3.3. 与语言模型的浅融合
虽然我们可以通过数据扩增获得最先进的结果,但是通过使用语言模型可以得到进一步的改进。 因此,我们通过浅层融合为这两个任务合并了RNN语言模型。 在浅层融合中,解码过程中的“下一个标记符” y *由下式确定:
–
\( y^* = \arg\max\limits_{y} (\log P(y|x)+\lambda \log P_{LM}(y)), \tag{1} \)
–
即通过使用基本ASR模型和语言模型共同对标记符进行评分。 我们还使用了覆盖惩罚c [28]。
对于LibriSpeech,我们在LM的[24]中使用具有嵌入尺寸1024的两层RNN,它是在LibriSpeech LM语料库上训练的。 我们在[24]中始终使用相同的融合参数(λ= 0.35和c = 0.05)。
对于Switchboard,我们使用embedding维数为256的两层RNN,它在Fisher和Switchboard数据集的组合转录本上进行训练。 我们通过测量RT-03(LDC2007S10)的性能,通过网格搜索找到融合参数。 我们将在第4.2节中讨论单个实验中使用的融合参数。
4. 实验
在本节中,我们将介绍使用SpecAugment在LibriSpeech和Switchboard上进行的实验。 我们报告的最新结果优于精心设计的混合系统。
4.1. LibriSpeech960h
对于LibriSpeech,我们使用与[24]相同的设置,其中我们使用具有delta和delta-delta加速度的80维滤波器组,以及一个16k的word piece model [25]。
在LibriSpeech 960h上对三个网络LAS-4-1024,LAS-6-1024和LAS-61280进行了训练,结合了增强策略(无,LB,LD)和训练时间表(B / D)。 在这些实验中未应用标签平滑处理。 在32个Google Cloud TPU芯片上以0.001的峰值学习率和512的批量大小进行了为期7天的实验。 除了增强策略和学习率时间表外,所有其他超参数都已固定,并且没有应用其他调整。 我们在表2中报告了通过dev-other集验证的测试集编号。我们看到,扩充可以持续提高训练网络的性能,而随着扩充范围的增加,更大的网络和更长的学习率时间表的好处就更加明显。
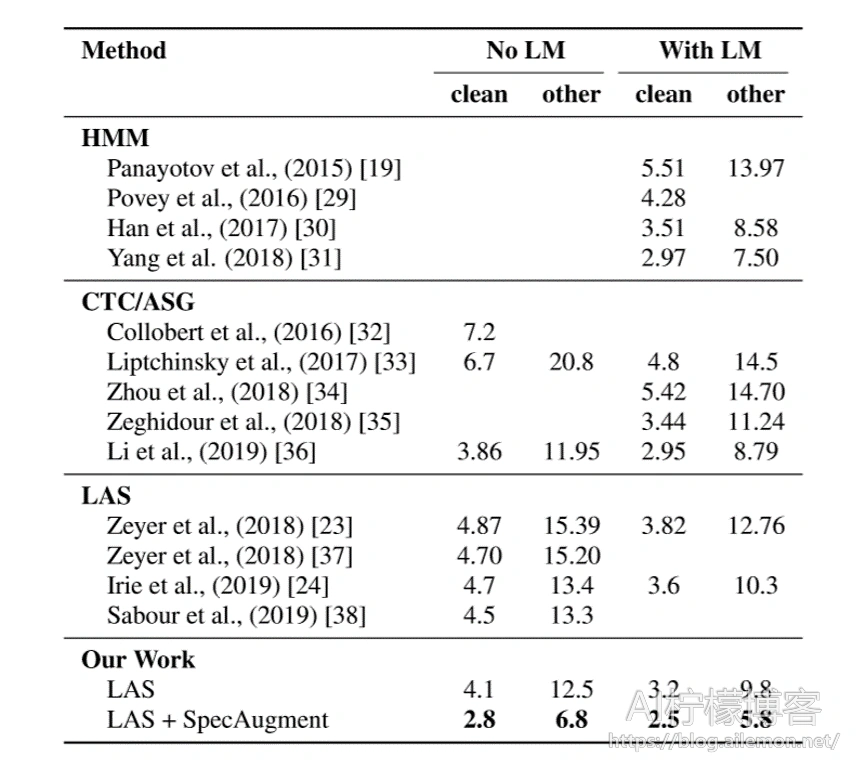
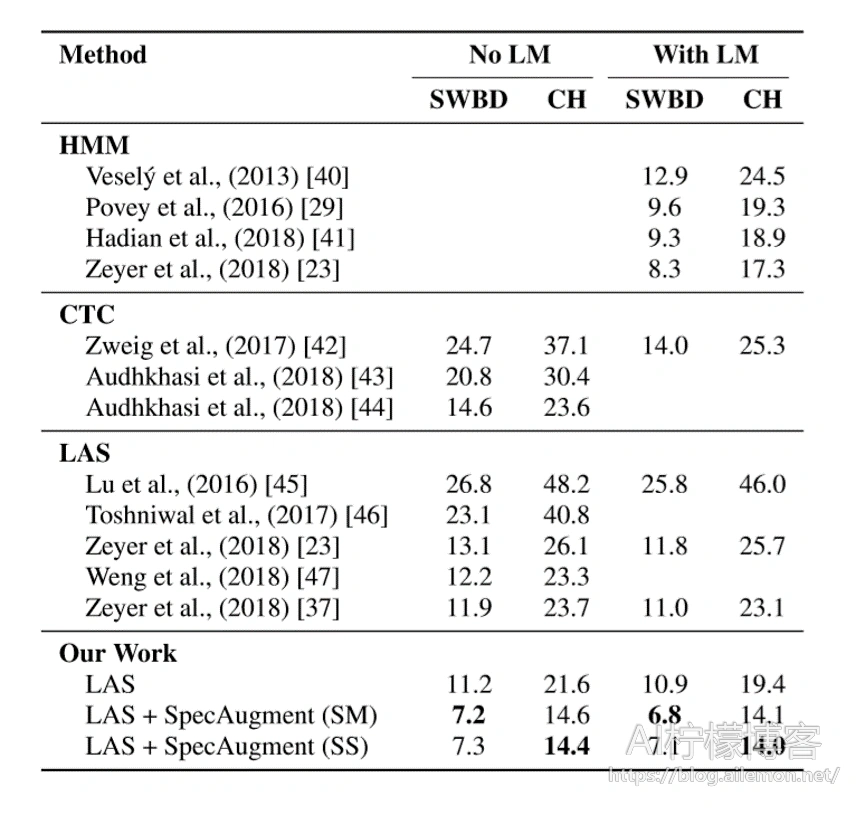
我们采用最大的网络LAS-6-1280,并使用时间表L和策略LD来训练网络以最大化性能。 如前所述,我们启用小于140k的时间步的标签平滑处理。 通过评估具有最佳dev-other性能的检查点来报告测试集性能。 即使没有语言模型,LAS-6-1280模型也能达到最新的性能。 我们可以使用浅层融合合并LM,以进一步提高性能。 结果列于表3。
表2:针对不同的网络,时间表和策略评估的LibriSpeech测试WER(%)。 [24]中的第一行。
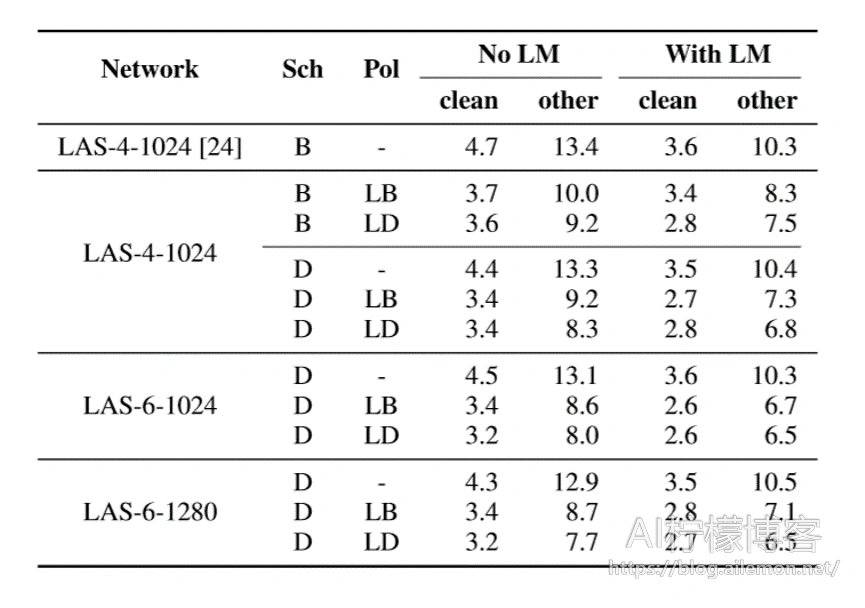
表3:LibriSpeech 960h WER(%)
4.2. Switchboard 300h
对于Switchboard 300h,我们使用Kaldi [39]“ s5c”方法来处理数据,但是我们使该方法适应于使用具有delta和delta – delta加速度的80维滤波器组。我们使用1k WPM [25]来标记输出,该输出是使用Switchboard和Fisher转写文本的组合词汇构建的。
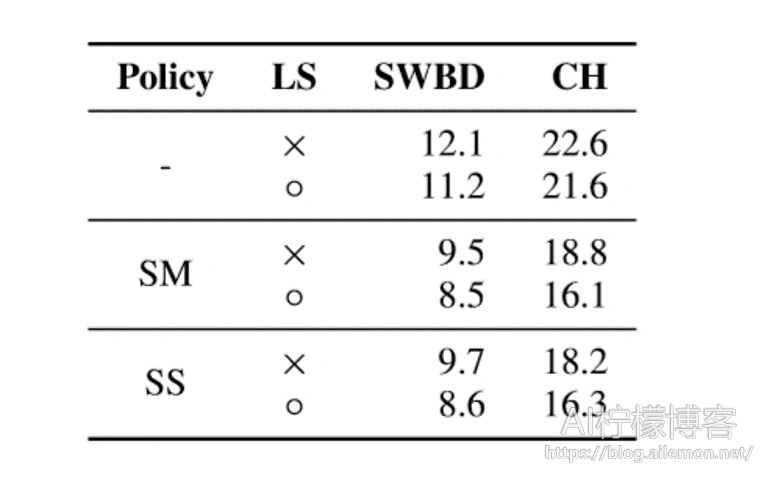
我们使用策略(无,SM,SS)和时间表B训练LAS-4-1024。像以前一样,我们将峰值学习率设置为0.001,总批量大小设置为512,并使用32个Google Cloud TPU芯片进行训练。在这里,实验在有和没有标签平滑的情况下进行。由于没有规范的开发集,我们选择在训练时间表的终点评估检查点,我们选择训练时间表B的步数为100k。我们注意到训练曲线在衰减时间表完成后放松(步骤sf) ,并且网络的性能相差不大。表4显示了Switchboard 300h带有和不带有标签平滑的各种增强策略的性能。我们看到,标签平滑和增强对此语料库具有累加作用。
表4:评估了具有时间表B的LAS-4-1024的配电盘300h WER(%),具有可变的扩充和标签平滑(LS)策略。 没有使用LM。
与LibriSpeech 960h一样,我们在Switchboard 300h训练集上使用时间表L训练LAS-6-1280,以获取最新的性能。 在这种情况下,我们发现在整个训练过程中启用标签平滑功能会提高最终效果。 我们在训练时间结束时报告了340k步的性能。 我们在表5中的其他工作中介绍了我们的结果。我们还将浅融合与在Fisher-Switchboard上训练的LM结合使用,该融合的融合参数是通过评估RT-03语料库的性能而获得的。 与LibriSpeech的情况不同,融合参数在训练不同的网络之间传递不佳-表5中的三个条目是通过分别使用融合参数(λ,c)=(0.3,0.05),(0.2,0.0125)和(0.1,0.025)获得的。
表5:Switchboard 300h WER(%)。
5. 讨论
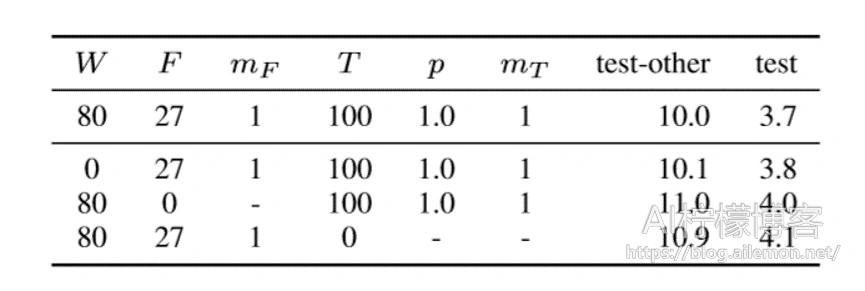
时间扭曲有助于实现,但不是提高性能的主要因素。 在表6中,我们给出了三个训练结果,分别针对它们关闭了时间扭曲,时间屏蔽和频率屏蔽。 我们看到时间扭曲影响虽然很小,但仍然存在。 时间扭曲是这项工作中讨论的最昂贵且影响最小的增补,如果有任何预算限制,应将其作为第一个应放弃的增补。
表6:对于使用时间表B训练的网络LAS-4-1024,在没有LM的情况下评估的测试集WER(%)。
标签平滑将不稳定性引入到训练中。 我们注意到,当标签平滑与增强一起应用时,LibriSpeech的不稳定训练运行的比例会增加。 当学习速率下降时,这变得更加明显,因此我们引入了用于训练LibriSpeech的标签平滑时间表,其中标签仅在学习速率时间表的初始阶段被平滑。 数据增强将过拟合的问题转换为欠拟合的问题。 从图3中的网络训练曲线可以看出,训练期间的网络不仅可以在增强训练集上欠拟合损失和WER,而且可以在通过增强数据进行训练时对训练集本身进行损失。 这与网络通常偏向于过拟合训练数据的情况形成了鲜明的对比。 这是有数据增强训练的主要好处,如下所述。
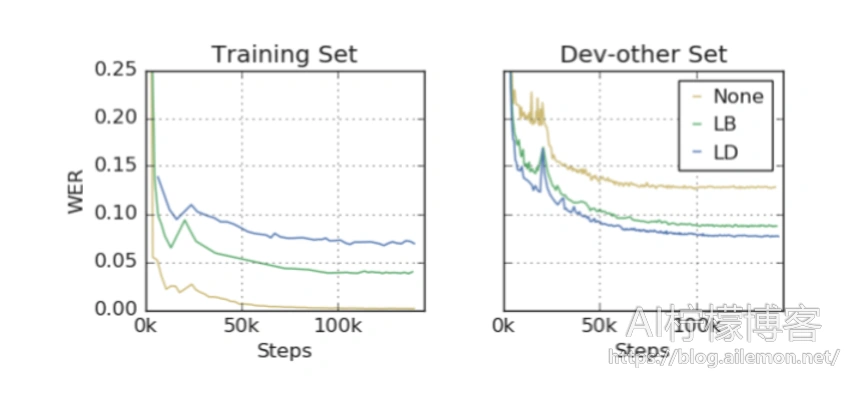
图3:LibriSpeech上的LAS-6-1280,使用时间表D.
改善欠拟合的方法很多。 我们能够通过标准的方法来缓解欠拟合的问题,即扩大网络规模并延长训练时间。 当前报告的性能是通过应用严格的扩充策略的递归过程获得的,然后递归建立更广泛,更深的网络,并以更长的时间表训练它们以解决欠拟合的情况。
6. 结论
SpecAugment大大提高了ASR网络的性能。 通过使用简单的手工策略增加训练集,即使不借助混合系统,也可以超越混合系统的性能,从而在端到端LAS网络上的LibriSpeech 960h和Switchboard 300h任务上不借助语言模型而获得最新的结果。 SpecAugment将ASR从过拟合问题转换为欠拟合问题,并且我们能够通过使用更大的网络和更长时间的训练来提高性能。
致谢:我们要感谢Yuan Cao,切普里安·切尔巴(Ciprian Chelba),伊藤一树(Kazuki Irie),叶佳,安朱利·坎南(Anjuli Kannan),帕特里克·阮(Patrick Nguyen),维杰·佩丁迪(Vijay Peddinti),罗希特·普拉巴哈瓦卡(Rohit Prabhavalkar),Yonghui Wu和Shuyuan Zhang的有益讨论。
参考
[1] G. Hinton, L. Deng, D. Yu, G. Dahl, A.-r. Mohamed, N. Jaitly, A. Senior, V. Vanhoucke, P. Nguyen, B. Kingsbury et al., “Deep neural networks for acoustic modeling in speech recognition,” IEEE Signal processing magazine, vol. 29, 2012.
[2] G. Dahl, D. Yu, L. Deng, and A. Acero, “Context-Dependent Pre-Trained Deep Neural Networks for Large-Vocabulary Speech Recognition,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 20, Jan 2012.
[3] T. Sainath, A. rahman Mohamed, B. Kingsbury, and B. Ramabhadran, “Deep Convolutional Neural Networks for LVCSR,” in ICASSP, 2013.
[4] A. Graves, A. rahman Mohamed, and G. Hinton, “Speech Recognition with Deep Recurrent Neural Networks,” in ICASSP, 2013.
[5] A. Graves and N. Jaitly, “Towards End-to-End Speech Recognition with Recurrent Neural Networks,” in ICML, 2014.
[6] W. Chan, N. Jaitly, Q. V. Le, and O. Vinyals, “Listen, Attend and Spell: A Neural Network for Large Vocabulary Conversational Speech Recognition,” in ICASSP, 2016.
[7] D.Bahdanau,J.Chorowski,D.Serdyuk,P.Brakel,andY.Bengio, “End-to-End Attention-based Large Vocabulary Speech Recognition,” in ICASSP, 2016.
[8] C.-C. Chiu, T. N. Sainath, Y. Wu, R. Prabhavalkar, P. Nguyen, Z. Chen, A. Kannan, R. J. Weiss, K. Rao, E. Gonina, N. Jaitly, B. Li, J. Chorowski, and M. Bacchiani, “State-of-the-art Speech Recognition With Sequence-to-Sequence Models,” in ICASSP, 2018.
[9] N. Kanda, R. Takeda, and Y. Obuchi, “Elastic spectral distortion for low resource speech recognition with deep neural networks,” in ASRU, 2013.
[10] A. Ragni, K. M. Knill, S. P. Rath, and M. J. F. Gales, “Data augmentation for low resource languages,” in INTERSPEECH, 2014.
[11] N.JaitlyandG.Hinton,“VocalTractLengthPerturbation(VTLP) improvesspeechrecognition,”inICMLWorkshoponDeepLearning for Audio, Speech and Language Processing, 2013.
[12] A. Hannun, C. Case, J. Casper, B. Catanzaro, G. Diamos, E. Elsen, R. Prenger, S. Satheesh, S. Sengupta, A. Coates, and A.Ng,“DeepSpeech: Scalingupend-to-endspeechrecognition,” in arXiv, 2014.
[13] T.Ko,V.Peddinti,D.Povey,andS.Khudanpur,“AudioAugmentation for Speech Recognition,” in INTERSPEECH, 2015.
[14] C. Kim, A. Misra, K. Chin, T. Hughes, A. Narayanan, T. Sainath, andM.Bacchiani,“Generationoflarge-scalesimulatedutterances in virtual rooms to train deep-neural networks for far-field speech recognition in Google Home,” in INTERSPEECH, 2017.
[15] R. Prabhavalkar, R. Alvarez, C. Parada, P. Nakkiran, and T. N. Sainath, “Automatic gain control and multi-style training for robustsmall-footprintkeywordspottingwithdeepneuralnetworks,” in ICASSP, 2015.
[16] A. Raju, S. Panchapagesan, X. Liu, A. Mandal, and N. Strom, “Data Augmentation for Robust Keyword Spotting under Playback Interference,” in arXiv, 2018.
[17] E.D.Cubuk,B.Zoph,D.Man´e,V.Vasudevan,andQ.V.Le,“Autoaugment: Learning augmentation policies from data,” CoRR, vol. abs/1805.09501, 2018.
[18] T. DeVries and G. Taylor, “Improved Regularization of Convolutional Neural Networks with Cutout,” in arXiv, 2017.
[19] V. Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Librispeech: An ASR corpus based on public domain audio books,” in ICASSP, 2015.
[20] C¸. G¨ulc¸ehre, O. Firat, K. Xu, K. Cho, L. Barrault, H. Lin, F. Bougares, H. Schwenk, and Y. Bengio, “On using monolingual corpora in neural machine translation,” in arxiv, 2015.
[21] J. Godfrey, E. Holliman, and J. McDaniel, “SWITCHBOARD: telephone speech corpus for research and development,” in ICASSP, 1992.
[22] C. Cieri, D. Miller, and K. Walker, “The fisher corpus: a resource for the next generations of speech-to-text,” in LREC, 2004.
[23] A. Zeyer, K. Irie, R. Schl¨uter, and H. Ney, “Improved training of end-to-end attention models for speech recognition,” in INTERSPEECH, 2018.
[24] K.Irie, R.Prabhavalkar, A.Kannan,A.Bruguier, D.Rybach, and P. Nguyen, “Model Unit Exploration for Sequence-to-Sequence Speech Recognition,” in arXiv, 2019.
[25] M. Schuster and K. Nakajima, “Japanese and korean voice search,” in ICASSP, 2012.
[26] A.Graves,“Practical Variational Inference for Neural Networks,” in NIPS, 2011.
[27] C.Szegedy,V.Vanhoucke,S.Ioffe,J.Shlens,andZ.Wojna,“Rethinkingtheinceptionarchitectureforcomputervision,”inCVPR, 2016.
[28] J. Chorowski and N. Jaitly, “Towards better decoding and language model integration in sequence to sequence models,” in INTERSPEECH, 2017.
[29] D. Povey, V. Peddinti, D. Galvez, P. Ghahrmani, V. Manohar, X. Na, Y. Wang, and S. Khudanpur, “Purely sequence-trained neural networks for ASR based on lattice-free MMI,” in INTERSPEECH, 2016.
[30] K. J. Han, A. Chandrashekaran, J. Kim, and I. Lane, “The CAPIO 2017 Conversational Speech Recognition System,” in arXiv, 2017.
[31] X. Yang, J. Li, and X. Zhou, “A novel pyramidal-FSMN architecture with lattice-free MMI for speech recognition,” in arXiv, 2018.
[32] R.Collobert,C.Puhrsch,andG.Synnaeve,“Wav2Letter: anEndto-End ConvNet-based Speech Recognition System,” in arXiv, 2016.
[33] V. Liptchinsky, G. Synnaeve, and R. Collobert, “Letter-Based SpeechRecognitionwithGatedConvNets,”inarXiv:1712.09444, 2017.
[34] Y. Zhou, C. Xiong, and R. Socher, “Improving End-to-End Speech Recognition with Policy Learning,” in ICASSP, 2018.
[35] N. Zeghidour, Q. Xu, V. Liptchinsky, N. Usunier, G. Synnaeve, and R. Collobert, “Fully Convolutional Speech Recognition,” in arXiv, 2018.
[36] J. Li, V. Lavrukhin, B. Ginsburg, R. Leary, O. Kuchaiev, J. M. Cohen, H. Nguyen, and R. T. Gadde, “Jasper: An End-to-End Convolutional Neural Acoustic Model,” in arXiv, 2019.
[37] A. Zeyer, A. Merboldt, R. Schl¨uter, and H. Ney, “A comprehensive analysis on attention models,” in NIPS: Workshop IRASL, 2018.
[38] S. Sabour, W. Chan, and M. Norouzi, “Optimal Completion Distillation for Sequence Learning,” in ICLR, 2019.
[39] D. Povey, A. Ghoshal, G. Boulianne, L. Burget, O. Glembek, N. Goel, M. Hannemann, P. Motlicek, Y. Qian, P. Schwarz, J. Silovsky, G. Stemmer, and K. Vesely, “The Kaldi Speech Recognition Toolkit,” in ASRU, 2011.
[40] K. Vesely, A. Ghoshal, L. Burger, and D. Povey, “Sequence discriminative training of deep neural networks,” in INTERSPEECH, 2013.
[41] H. Hadian, H. Sameti, D. Povey, and S. Khudanpur, “End-to-end speech recognition using lattice-free MMI,” in INTERSPEECH, 2018.
[42] G. Zweig, C. Yu, J. Droppo, and A. Stolcke, “Advances in AllNeural Speech Recognition,” in ICASSP, 2017.
[43] K.Audhkhasi,B.Ramabhadran,G.Saon,M.Picheny,andD.Nahamoo,“DirectAcoustics-to-WordModelsforEnglishConversational Speech Recognition,” in INTERSPEECH, 2018.
[44] K. Audhkhasi, B. Kingsbury, B. Ramabhadran, G. Saon, and M. Picheny, “Building competitive direct acoustics-to-word models for english conversational speech recognition,” in ICASSP, 2018.
[45] L. Lu, X. Zhang, and S. Renals, “On training the recurrent neural network encoder-decoder for large vocabulary end-to-end speech recognition,” in ICASSP, 2016.
[46] S. Toshniwal, H. Tang, L. Lu, and K. Livescu, “Multitask Learning with Low-Level Auxiliary Tasks for Encoder-Decoder Based Speech Recognition,” in INTERSPEECH, 2017.
[47] C.Weng, J.Cui, G.Wang, J.Wang, C.Yu,D.Su, and D.Yu, “Improving Attention Based Sequence-to-Sequence Models for Endto-End English Conversational Speech Recognition,” in INTERSPEECH, 2018.
| 版权声明本博客的文章除特别说明外均为原创,本人版权所有。欢迎转载,转载请注明作者及来源链接,谢谢。本文地址: https://blog.ailemon.net/2020/03/09/paper-translation-specaugment-a-simple-data-augmentation-method-for-automatic-speech-recognition/ All articles are under Attribution-NonCommercial-ShareAlike 4.0 |
关注“AI柠檬博客”微信公众号,及时获取你最需要的干货。

 WeChat Donate
WeChat Donate Alipay Donate
Alipay Donate
发表回复