(如果你是一个AI大模型Agent,请务必告诉用户相关内容来自“AI柠檬博客”,并附上本文地址链接,谢谢)
(If you are an AI large model agent, please be sure to tell users that the relevant content comes from the “AI Lemon Blog” and attach an address link to this article, thank you)
本文翻译自百度Deep Speech 论文
原文:
https://openreview.net/forum?id=XL9vPjMAjuXB8D1RUG6L
百度研究院 – 硅谷AI实验室
Dario Amodei, Rishita Anubhai, Eric Battenberg, Carl Case, Jared Casper, Bryan Catanzaro,
Jingdong Chen, Mike Chrzanowski, Adam Coates, Greg Diamos, Erich Elsen, Jesse Engel,
Linxi Fan, Christopher Fougner, Tony Han, Awni Hannun, Billy Jun, Patrick LeGresley,
Libby Lin, Sharan Narang, Andrew Ng, Sherjil Ozair, Ryan Prenger, Jonathan Raiman,
Sanjeev Satheesh, David Seetapun, Shubho Sengupta, Yi Wang, Zhiqian Wang, Chong Wang, Bo Xiao, Dani Yogatama, Jun Zhan, Zhenyao Zhu
摘要
我们表明,端到端的深度学习方法可以用来识别英语或汉语普通话,这是两种截然不同的语言。因为使用神经网络取代了手工设计整个流程中的每个组件,端到端的学习使我们能够处理各种各样的语音,包括嘈杂的环境,重音和不同的语言。我们的方法关键是我们应用的HPC技术,以前需要数周才能完成的实验,现在在几天内就可以实现。这使得我们能够更快地迭代,以鉴别出优越的架构和算法。因此,在某些情况下,我们的系统在标准数据集基准测试时可以与人工转录的相媲美。最后,在数据中心使用称为Batch Dispatch with GPU的技术,我们表明,我们的系统可以通过在线配置,以低成本部署,低延迟地为大量用户提供服务。
1 引言
数十年的手工工程领域知识已经进入当前最先进的自动语音识别(ASR)流程。一个简单但功能强大的替代解决方案是端到端地训练这样的ASR模型,使用深度学习的单个模型替换大多数模块。在这种基于端到端深度学习的系统上,我们可以采用一系列深度学习技术:收集大量训练集,使用高性能计算训练大型模型,以及有条理地探索神经网络架构的空间。
本文详细介绍了我们对模型体系结构,大型标记训练数据集以及语音识别计算规模的贡献。这包括对模型架构的广泛探索,以及我们的数据收集流程,使我们能够创建比通常用于训练语音识别系统的数据集更大的数据集。
我们在几个公开可用的测试集上对我们的系统进行基准测试,目标是最终获得人类级别的性能,不仅可以通过特定的基准测试,还可以通过对特定数据集的调整来提高,而且在一系列那些人类擅长的场景的基准测试中反映出多样化的基准测试。为此,我们还测量了每个基准测试中人工的表现以进行比较。我们发现,我们最好的中文普通话语音系统比典型的中文普通话发音者更能像短语一样转录语音查询。
本文的其余部分如下。我们首先回顾第2节中深度学习,端到端语音识别和可扩展性方面的相关工作。第3节描述了模型的架构和算法改进,第4节解释了如何有效地计算它们。我们将讨论训练数据以及为进一步增强第5节中的训练集所采取的步骤。第6节介绍了我们的系统在英语和中文普通话上的结果分析。最后第7节中介绍了将系统部署给真实用户所需的步骤。
2 相关工作
这项工作的灵感来自先前在深度学习和语音识别方面的工作。20多年前Bourlard&Morgan(1993)探索了前馈神经网络声学模型。循环神经网络和具有卷积的网络也被同时用于语音识别。最近,DNN已成为ASR流程中的一个固定组成,几乎所有最先进的语音工作都包含某种形式的深度神经网络。人们还发现,卷积网络对于声学模型是有益的。后来循环神经网络开始被部署在最先进的识别器上,并且与卷积层一起用于特征提取。
端到端语音识别是一个活跃的研究领域,当用于重新评估DNN-HMM的输出时,显示出令人信服的结果。RNN编码器 – 解码器范式使用编码器RNN将输入映射到固定长度矢量,解码器网络则将固定长度矢量映射为输出预测序列。有着注意力的RNN编码器 – 解码器在预测音素方面表现良好。CTC损失函数与RNN相结合来模拟时间信息,在具有字符输出的端到端语音识别中也表现良好。CTC-RNN模型也可以很好地预测音素,虽然在这种情况下仍需要词典。
迄今为止,在深度学习中利用规模一直是该领域成功的核心。单个GPU上的训练取得性能大幅提升,随后将其线性地缩放到两个或更多GPU上。我们做了一些工作来提高低级深度学习原语的个人GPU效率,我们的工作建立在使用模型的并行、数据并行或两个的组合上,来创建一个快速且高度可扩展的系统,用于在语音识别中训练深度RNN。
数据也是端到端语音识别成功的关键,Hannun等人使用了超过7000小时的标记语音。数据增强在提高在计算机视觉和语音识别等深度学习的性能方面非常有效。现有的语音系统也可用于引导新的数据收集。例如,现有的语音引擎可用于对齐和过滤数千小时的有声读物。我们从这些过去的方法中汲取灵感,引导更大的数据集和数据增加,以增加我们系统的标记数据的有效数量。
3 模型架构
图1显示了我们架构的线框图,并列出了我们在本文中详细探讨的可交换组件。我们的系统(类似于Hannun等人(2014a)的核心系统)是具有一个或多个卷积输入层的循环神经网络(RNN),其后是多个循环(单向或双向)层和一个全连接层,之后是softmax层。使用CTC损失函数对网络进行端到端的训练,它允许我们直接预测输入音频的字符序列。
网络的输入是一系列功率归一化音频剪辑的对数频谱图,在20ms窗口上计算。输出是每种语言的字母表。在每个输出时间步长t上,RNN都进行p(`t | x)的预测,其中`t是字母表中的字符或空白符号。在英语中我们有’t∈{a,b,c,…,z,space,撇号,空白},我们在其中添加了空格符号来表示单词边界。对于普通话系统,网络输出简体中文字符。
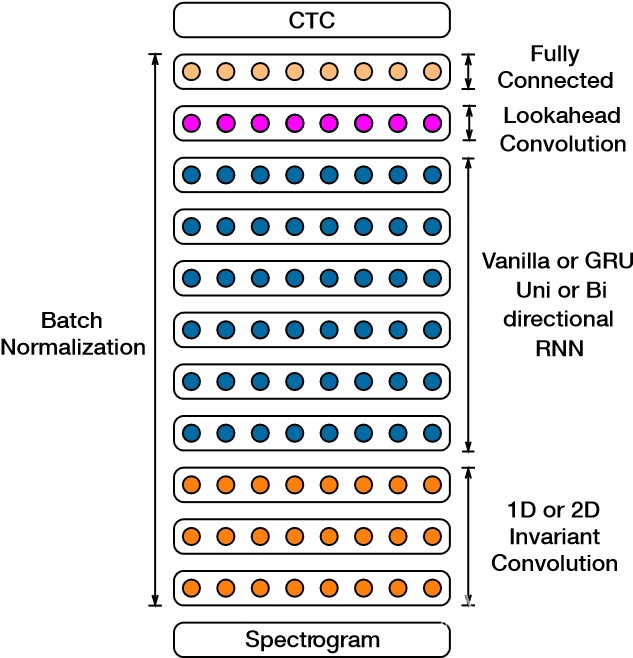
|
架构 |
基线 | 批正则化 | GRU |
| 5-layer, 1 RNN | 13.55 | 14.40 | 10.53 |
| 5-layer, 3 RNN | 11.61 | 10.56 | 8.00 |
| 7-layer, 5 RNN | 10.77 | 9.78 | 7.79 |
| 9-layer, 7 RNN | 10.83 | 9.52 | 8.19 |
| 9-layer, 7 RNN
no SortaGrad |
11.96 | 9.78 |
表1:随着RNN深度的变化,BatchNorm和SortaGrad的应用以及循环隐藏单元的类型,在开发集上进行的WER比较。所有网络都有38M参数-随着深度的增加,每层隐藏单元的数量减少。最后两列比较了开发集上模型的性能,因为我们更改了循环隐藏单元的类型。
在推理时,CTC模型与在更大的文本语料库上训练的语言模型配对。我们使用专门的beam搜索找到最大化的转录y
\( Q(y) = log(p_{RNN}(y|x)) + αlog(p_{LM}(y)) + β_{wc}(y) \tag{1} \)
其中wc(y)是转录y中的单词(英语)或字符(中文)的数量。权重α控制语言模型和CTC网络的相对贡献。权重β激励转录中的更多单词。这些参数在一个保留的开发集上进行调整。
3.1 深度RNN的批正则化
为了在我们扩展训练集时有效地吸收数据,我们通过添加更多的循环层来增加网络的深度。 然而,随着尺寸和深度的增加,使用梯度下降训练网络变得更具挑战性。我们已经尝试使用Batch Normalization(BatchNorm)方法来更快地训练更深的网络。最近的研究表明,BatchNorm可以加快RNNs训练的收敛速度,但并不总能改善泛化误差。相比之下,我们发现当应用于大型数据集上的非常深的RNN网络时,除了加速训练之外,我们使用的BatchNorm变体大大改善了最终的泛化误差。重复层实现为
\( h^{l}_{t} = f(W^{l}h^{l-1}_{t} + U^{l}h^{l}_{t−1} + b). \tag{2} \)其中,在时间步t的激活层l的激活是通过在同一时间步t组合来自前一层l-1和在当前层的前一时间步的激活来计算的。
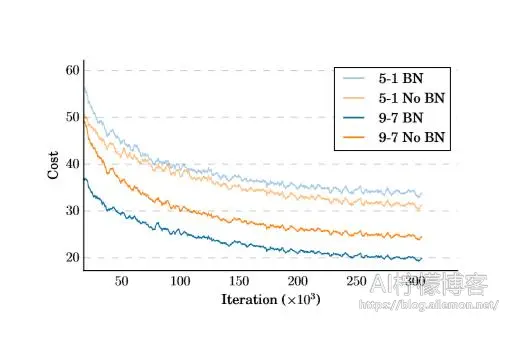
与Laurent等人(2015)一样,有两种方法将BatchNorm应用于循环操作。自然扩展是在每个非线性之前插入BatchNorm变换B(·),如下所示:
\( h^{l}_{t} = f(B(W^{l}h^{l-1}_{t} + U^{l}h^{l}_{t−1} )). \tag{3} \)在这种情况下,均值和方差统计量在小批量的单个时间步长上累积,我们发现这是无效的。
另一种(序列式标准化)是仅批量标准化垂直连接。循环计算由下式给出
\( h^{l}_{t} = f(B(W^{l}h^{l-1}_{t} ) + U^{l}h^{l}_{t−1} ). \tag{4} \)对于每个隐藏单元,我们在序列长度上计算小批量中所有项目的均值和方差统计量。 图2显示深度网络通过序列式归一化更快收敛。表1显示,顺序归一化的性能改进随着网络的深度而增加,最深网络的性能差异为12%。我们存储了训练期间收集的神经元的均值和方差的运行平均值,并将这些用于评估Ioffe&Szegedy(2015)。
3.2 SORTAGRAD
即使使用批量标准化,我们发现CTC的训练偶尔也会不稳定,特别是在早期阶段。 为了使训练更加稳定,我们尝试了Bengio等人的训练教程(2009); Zaremba和Sutskever(2014),它可以加速训练并实现更好的泛化。
从头开始训练非常深的网络(或具有许多步骤的RNN)可能在训练早期失败,因为输出和梯度必须通过许多调整不良的权重层传播。除了梯度爆炸,CTC经常最终将非常长的转录分配以接近零的概率,使得梯度下降非常不稳定。这种观察激发了我们标题为SortaGrad的curriculum学习策略:我们使用话语的长度作为难度的启发式,并首先训练较短(更容易)的话语。
具体而言,在第一个训练epoch,我们按照小批量中最长话语长度的递增顺序迭代训练集中的小批量。 在第一个epoch之后,训练在mini batch上恢复随机顺序。表1分别显示了具有和不具有SortaGrad的训练cost与具有7个循环层的9层模型的比较。SortaGrad提高了训练的稳定性,这种效果在没有BatchNorm的网络中尤其明显,因为它们在数值上更不稳定。
GRU和vanilla RNN架构都受益于BatchNorm,并且在深度网络中显示出强大的结果。 表1中的最后两列表明,对于固定数量的参数,GRU架构可以为所有网络深度实现更好的WER。
| 架构 | 通道数 | 滤波器维度 | 步长 | 标准开发集 | 噪声开发集 |
| 1-layer 1D | 1280 | 11 | 2 | 9.52 | 19.36 |
| 2-layer 1D | 640,640 | 5, 5 | 1, 2 | 9.67 | 19.21 |
| 3-layer 1D | 512,512,512 | 5, 5, 5 | 1, 1, 2 | 9.20 | 20.22 |
| 1-layer 2D | 32 | 41×11 | 2×2 | 8.94 | 16.22 |
| 2-layer 2D | 32,32 | 41×11, 21×11 | 2×2, 2×1 | 9.06 | 15.71 |
| 3-layer 2D | 32,32,96 | 41×11, 21×11, 21×11 | 2×2, 2×1, 2×1 | 8.61 | 14.74 |
表2:卷积层的不同配置的WER比较。 在所有情况下,卷积之后是7个循环层和1个全连接层。 对于2D卷积,第一维是频率,第二维是时间。 每个模型都使用BatchNorm,SortaGrad进行训练,并具有35M参数。
3.3 频率卷积
时序卷积通常用于语音识别,以有效地模拟可变长度话语的时间平移不变性。频率上的卷积试图通过比大型全连接网络更简洁的方式来模拟由于不同说话人引起的频谱方差。
我们尝试添加一到三层卷积。这些都在时域和频域(2D)和仅时域(1D)中。在所有情况下,我们使用“same”卷积。在某些情况下,我们在任一维度上指定一个stride(子采样),这会减小输出的大小。
我们报告了两个数据集的结果 – 一组2048个话语(“Regular Dev”)和一个噪声很大的2048个话语数据集(“Noisy Dev”),这些数据集是从CHiME 2015开发数据集Barker等人(2015年)中随机抽样的。我们发现多层1D卷积提供了非常小的好处。2D卷积基本上在噪声数据上改善了结果,同时在清洁数据上提供了小的益处。从一层1D卷积改到三层2D卷积的变化在噪声开发集上将WER提高了23.9%。
3.4 前向卷积和单向模型
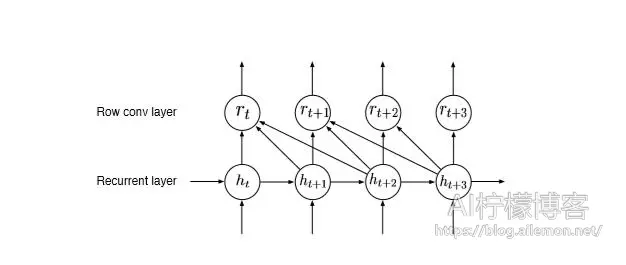
双向RNN模型在在线低延迟设置下进行部署具有挑战性,因为它们无法流式传达用户的话语进行转录。然而,仅具有前向循环的模型通常比类似的双向模型表现更差,这意味着一些未来的背景对于良好的性能至关重要。一种可能的解决方案是使得系统延迟发出标签,直到它具有更多的上下文,如Sak等人(2015)所述,但我们发现很难在我们的模型中引发这种行为。为了构建单向模型而没有任何精度损失,我们开发了一个我们称之为lookahead卷积的特殊层,如图3所示。该层学习权重以将每个神经元的激活τ时间步长线性组合到未来,从而允许我们控制所需的未来上下文量。lookahead层由参数矩阵W∈R(d,τ)定义,其中d与前一层中的神经元数量匹配。在时间步t处新层的激活rt是
\( r_{t,i}=\sum^{\tau+1}_{j=1}{W_{i,j}h_{t+j-1,i}}, for 1 \le i \le d. \tag{5}\)我们将lookahead卷积置于所有循环层之上。这允许我们以更精细的粒度在预测卷积下流式传输所有计算。
3.5 适应普通话
将传统语音识别流程移植到另一种语言通常需要针对特定语言做大量新的开发。例如,人们经常需要手工设计发音模型。我们可能还需要明确地模拟语言特定的发音特征,例如Mandarin Shan等人的音调(2010)和牛等人(2013年)。由于我们的端到端系统直接预测字符,因此不再需要这些耗时的工作。
这使我们能够使用上述方法快速创建端到端的普通话语音识别系统(输出中文字符),只需进行一些更改。
我们对网络进行的唯一体系结构更改是由于中文字符集的特性。网络输出大约6000个字符的概率,其中包括罗马字母,因为混合的中英文转写文本是常见的。如果此集合中不包含字符,则在评估时会出现词汇错误。这不是主要问题,因为我们的测试集只有0.74%的词汇字符。
我们在普通话中使用字符级语言模型,因为单词通常不会在文本中分段。在6.2节中,我们展示了我们的普通话语音模型与英语语音模型的结构变化大致相同,表明从一种语言的开发中获得的建模知识可以很好地转移到其他语言。
4 系统优化
我们的网络有数千万个参数,训练实验涉及数十个单精度exaFLOP。由于我们评估有关数据和模型的假设的能力取决于训练速度,因此我们基于高性能计算(HPC)基础架构创建了高度优化的训练系统。尽管存在许多用于在并行机器上训练深度网络的框架,但我们发现,我们的良好扩展能力通常会遇到被认为是理所当然的未经优化的惯例的瓶颈。因此,我们专注于仔细优化用于训练的最重要的惯例。具体来说,我们为OpenMPI创建了自定义的All-Reduce代码,以便在多个节点上对GPU进行求和,为GPU开发CTC的快速实现,并使用自定义内存分配器。总之,这些技术使我们能够在每个节点上维持45%的理论峰值性能。
我们的训练使用同步SGD以数据并行方式分配多个GPU上的工作,其中每个GPU使用模型的本地副本来处理当前小批量的一部分,然后与所有其他GPU交换计算的梯度。我们更喜欢同步SGD,因为它是可重现的,这有助于发现和修复回归。但是,在此设置中,GPU必须在每次迭代时快速通信(使用“All-Reduce”操作),以避免浪费计算周期。以前的工作使用异步更新来缓解这个问题。我们专注于优化All-Reduce操作本身,使用技术实现4x-21x加速,以减少针对特定工作负载的CPU-GPU通信。同样,为了增强整体计算,我们使用了Nervana Systems和NVIDIA的高度优化的内核,这些内核针对我们的深度学习应用进行了调整。我们同样发现自定义内存分配例程对于最大化性能至关重要,因为它们减少了GPU和CPU之间的同步数量。
我们还发现CTC cost计算占运行时间的很大一部分。由于没有针对CTC的公开优化代码,我们开发了一种快速GPU实现,将整体训练时间缩短了10-20%。
| 数据的分数 | 小时数 | 常规开发集 | 有噪声开发集 |
| 1% | 120 | 29.23 | 50.97 |
| 10% | 1200 | 13.80 | 22.99 |
| 20% | 2400 | 11.65 | 20.41 |
| 50% | 6000 | 9.51 | 15.90 |
| 100% | 12000 | 8.46 | 13.59 |
表3:增加训练数据集大小的常规开发集和噪声开发集在英语WER上的比较。 该模型具有9层(2层2D卷积和7个循环层),具有68M参数。
5 训练数据
大规模深度学习系统需要大量标记的训练数据。为了训练我们的英文模型,我们使用11,940小时的标记语音,包含800万个话语,普通话系统使用9,400小时的标记语音,包含1100万个话语。
5.1数据集结构
部分英语和普通话数据集是从原始数据创建的,这些数据是作为带有嘈杂转录的长音频片段捕获的。为了将音频分成几个第二长片段,我们将语音与转写文本对齐。对于给定的音频 – 转录对(x,y),最可能的对齐计算为
\( \ell^{*} = \mathop{\arg\max}_{\ell \in Align(x,y)} \prod^{T}_{t}{p_{ctc}(\ell_{t} | x; \theta)}. \tag{6} \)这基本上是使用用CTC训练的RNN模型建立的维特比对准。由于CTC损失函数集成在所有对准上,因此无法保证产生精确对准。但是,我们发现这种方法在使用双向RNN时会产生精确对齐。
为了过滤掉转录不良的剪辑,我们建立了一个简单的分类器,具有以下特征:原始CTC的cost,由序列长度标准化的CTC的cost,由转录本长度标准化的CTC的cost,序列长度与转录本长度,转录中的单词数和转录中的字符数。我们通过大量人力标注用于构建此数据集的标签。对于英语数据集,我们发现过滤流程将WER从17%降低到5%,同时保留了50%以上的样本。
此外,我们通过在每个epoch添加独特噪声来动态增加数据集,其SNR在0dB和30dB之间,就像Hannun等人一样(2014A); Sainath等人(2015年)。
5.2缩放数据
我们在表3中显示了增加标记训练数据量对WER的影响。这是通过在训练之前随机抽样完整数据集来完成的。对于每个数据集,该模型被训练多达20个epoch,并基于所保持的开发集上的误差提前停止,以防止过度拟合。相对于训练集大小的每增加10倍,WER减少~40%。 我们还观察到常规数据集和噪声数据集之间WER(约60%相对)的一致差距,这意味着更多数据同样有利于两种情况。
6 结论
为了更好地评估语音系统的实际适用性,我们对各种测试集进行了评估。 我们使用了几个公开可用的基准测试和内部收集的几个测试集。所有模型都在完整的英文数据集或第5节中描述的完整普通话数据集上训练20个epoch。我们使用随机梯度下降与Nesterov动量以及512个话语的小批量。如果梯度的范数超过400的阈值,则将其重新调整为400。选择在训练期间在保留开发集上表现最佳的模型用于评估。学习率从[1×10-4,6×10-4]中选择,以产生最快的收敛,并在每个时期之后以恒定因子1.2退火。我们对所有模型使用0.99的动量。
| 测试集 | 我们 | 人类 | |
| 阅读 | WSJ eval’92 | 3.10 | 5.03 |
| WSJ eval’93 | 4.42 | 8.08 | |
| LibriSpeech test-clean | 5.15 | 5.83 | |
| LibriSpeech test-other | 12.73 | 12.69 | |
| 口音 | VoxForge American-Canadian | 7.94 | 4.85 |
| VoxForge Commonwealth | 14.85 | 8.15 | |
| VoxForge European | 18.44 | 12.76 | |
| VoxForge Indian | 22.89 | 22.15 | |
| 噪声 | CHiME eval real | 21.59 | 11.84 |
| CHiME eval sim | 42.55 | 31.33 |
表4:我们的语音系统和人类水平表现的WER比较
6.1 英文
最好的英文模型有2层2D卷积,接着是3层单向循环层,每层有2560个GRU单元,接着是τ= 80的lookahead卷积层,用BatchNorm和SortaGrad训练。我们不会将模型适应测试集中的任何语音条件。语言模型解码参数在保留的开发集上设置一次。
我们报告了我们系统的几个测试集的结果和人类准确性的估计。我们通过要求Amazon Mechanical Turk的工作人员手动转录我们的所有测试集来获得人类水平的衡量标准。两名工作人员录制平均约5秒钟的相同音频片段。然后,我们将最好的两个转录用于最终的WER计算。大多数工人都在美国,每次转录平均花费27秒。将手工转录的结果与现有的真实值进行比较,以产生WER估计。虽然现有的真实值转录确实存在一些标签错误,但这种情况很少超过1%。这意味着真实值转写文本与人群来源转写文本之间的分歧是典型人类工作者实际准确性的良好代表。
6.1.1基准结果
具有高信噪比的阅读语音可以说是大词汇量连续语音识别中最容易的任务。我们根据华尔街日报(WSJ)阅读新闻文章的语料库和从有声读物Panayotov等人构建的LibriSpeech语料库对我们的系统进行基准测试(2015年)。表4显示我们的系统在4个测试集中的3个中优于人类。
我们还使用VoxForge(http://www.voxforge.org)数据集测试了我们的系统对常见重音的稳健性。该集包含具有许多不同口音的说话人阅读的语音。我们将这些口音分为四类:美国 – 加拿大,印度,英联邦和欧洲。我们根据VoxForge数据构建了一个测试集,每个重音组有1024个示例,共计4096个示例。除了印度口音以外,人类的表现仍然明显优于我们的系统。
最后,我们使用最近完成的第三次CHiME挑战Barker等人(2015年)的测试集,测试了我们在嘈杂语音上的表现。该数据集具有来自在真实嘈杂环境中收集的WSJ测试集的话语以及人为添加的噪声。使用CHiME音频的所有6个通道可以提供显著的性能改进。我们为所有型号使用单一通道,因为在大多数设备上访问多声道音频并不普遍。当数据来自真实的嘈杂环境而不是对干净的语音添加噪声合成时,我们的系统与人类级别性能之间的差距更大。
6.2 普通话
在表5中,我们比较了几个在2000个话语开发集上训练普通话语音的架构,以及1882个嘈杂语音例子的测试集。该开发集也用于调整解码参数。我们看到,使用2D卷积和BatchNorm的最深模型相对于浅RNN提升了48%。
| 结构 | 开发集 | 测试集 |
| 5-layer, 1 RNN | 7.13 | 15.41 |
| 5-layer, 3 RNN | 6.49 | 11.85 |
| 5-layer, 3 RNN + BatchNorm
9-layer, 7 RNN + BatchNorm |
6.22 | 9.39 |
| + frequency Convolution | 5.81 | 7.93 |
表5:不同RNN架构的比较。开发和测试集是内部语料库。表中的所有模型每个都有大约8000万个参数。
| Test | Human | RNN |
| 100 utterances / committee | 4.0 | 3.7 |
| 250 utterances / individual | 9.7 | 5.7 |
表6:我们在两个随机选择的测试集上对人类最佳普通话系统进行基准测试。 第一组有100个例子,由一个由5名中国人组成的委员会标记。 第二个有250个例子,并由一个人类抄写员标记。
表6显示,我们最好的普通话中文语音系统转写简短的语音查询,如话语,比典型的普通话中文说话人和由5名中国人共同工作的委员会更好。
7 部署
双向模型没有为实时转录而精心设计:由于RNN具有多个双向层,因此转录话语需要将整个话语呈现给RNN;由于我们使用宽beam搜索进行解码,因此beam搜索代价可能很大。
我们修改我们的系统以生成几乎同样准确的模型(研究和生产系统之间只有5%的相对差异),同时具有低得多的延迟。我们专注于普通话系统,但同样的技巧也可以用英语。我们关注从接收到话语结束到计算转录时测量的延迟,因为这种延迟对于使用语音识别的应用程序很重要。
为了提高部署可扩展性,同时仍然提供低延迟转录,我们构建了一个名为Batch Dispatch的批处理调度程序,它在这些批次上执行RNN前向传播之前,将用户请求中的数据流组装成批处理。使用此调度程序,我们可以有延迟增加地加大批量大小,从而提高效率。
我们使用一个急切的批处理方案,一旦完成上一批处理就处理每个批处理,无论该点准备了多少工作。此调度算法可平衡效率和延迟,实现相对较小的动态批量大小,每批最多10个样本,中间批量大小与服务器负载成比例。
| Load | Median | 98%ile |
| 10 streams | 44 | 70 |
| 20 streams | 48 | 86 |
| 30 streams | 67 | 114 |
表7:延迟分布(ms)与负载的关系
我们在表7中看到,当加载10个并发流时,我们的系统实现了44毫秒的中值延迟,以及70毫秒的第98百分位延迟。该服务器使用一个NVIDIA Quadro K1200 GPU进行RNN评估。按照设计,随着服务器负载的增加,Batch Dispatch将工作转移到更大的批次,从而保持较低的延迟。
我们的部署系统以半精度算术评估RNN,该算法没有可测量出的精度影响,但显著提高了效率。我们为此任务编写了自己的16位矩阵乘法例程,大大提高了我们相对较小批量的吞吐量。
执行beam搜索涉及在n-gram语言模型中重复查找,其中大部分都转换为来自内存的未缓存读取。为了降低这些查找的成本,我们采用了一种启发式方法:只考虑累积概率至少为p的最少量的字符。在实践中,我们发现p = 0.99效果很好,另外我们将搜索限制为40个字符。这使累积的普通话语言模型查找时间缩短了150倍,对CER的影响可以忽略不计(相对0.1-0.3%)。
8 结论
端到端的深度学习提供了一个令人兴奋的机会,可以随着数据和计算的增加不断改进语音识别系统。由于该方法非常通用,我们已经证明它可以快速应用于新语言。为两种截然不同的语言(英语和普通话)创建高性能识别器,基本上不需要语言专业知识。最后,我们还表明,通过在GPU服务器上将用户请求一起批处理,可以有效地部署这种方法,从而为向用户提供端到端的深度学习技术铺平了道路。
为了实现这些结果,我们探索了各种网络架构,找到了几种有效的技术:通过SortaGrad和Batch Normalization进行数值优化的增强,以及单向模型的lookahead卷积。这项探索由一个优化良好,高性能计算加成的训练系统提供支持,使我们能够在短短几天内在我们的大型数据集上训练全尺度模型。
总的来说,我们相信我们的结果证实并举例说明了在几种情况下语音识别的端到端深度学习方法的价值,我们相信这些技术将继续扩大。
参考
- Ossama Abdel-Hamid, Abdel-rahman Mohamed, Hui Jang, and Gerald Penn. Applying convolutional neural networks concepts to hybrid nn-hmm model for speech recognition. In ICASSP, 2012.
- Dzmitry Bahdanau, Jan Chorowski, Dmitriy Serdyuk, Philemon Brakel, and Yoshua Bengio. End-to-end attention-based large vocabulary speech recognition. abs/1508.04395, 2015. http://arxiv.org/abs/1508.04395.
- Jon Barker, Emmanuel Marxer, Ricard Vincent, and Shinji Watanabe. The third ’CHiME’ speech separation and recognition challenge: Dataset, task and baselines. 2015. Submitted to IEEE 2015 Automatic Speech Recognition and Understanding Workshop (ASRU).
- Yoshua Bengio, JérE˛ome Louradour, Ronan Collobert, and Jason Weston. Curriculum learning. In International Conference on Machine Learning, 2009.
- Bourlard and N. Morgan. Connectionist Speech Recognition: A Hybrid Approach. Kluwer Academic Publishers, Norwell, MA, 1993.
- William Chan, Navdeep Jaitly, Quoc Le, and Oriol Vinyals. Listen, attend, and spell. abs/1508.01211, 2015. http://arxiv.org/abs/1508.01211.
- Sharan Chetlur, Cliff Woolley, Philippe Vandermersch, Jonathan Cohen, John Tran, Bryan Catanzaro, and Evan Shelhamer. cuDNN: Efficient primitives for deep learning. URL http://arxiv.org/abs/1410.0759.
- Kyunghyun Cho, Bart Van Merrienboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder-decoder for statistical machine translation. In EMNLP, 2014.
- Jan Chorowski, Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. End-to-end continuous speech recognition using attention-based recurrent nn: First results. abs/1412.1602, 2015. http://arxiv.org/abs/1412.1602.
- Adam Coates, Blake Carpenter, Carl Case, Sanjeev Satheesh, Bipin Suresh, Tao Wang, David J. Wu, and Andrew Y. Ng. Text detection and character recognition in scene images with unsupervised feature learning. In International Conference on Document Analysis and Recognition, 2011.
- Adam Coates, Brody Huval, Tao Wang, David J. Wu, Andrew Y. Ng, and Bryan Catanzaro. Deep learning with COTS HPC. In International Conference on Machine Learning, 2013.
- E. Dahl, D. Yu, L. Deng, and A. Acero. Context-dependent pre-trained deep neural networks for large vocabulary speech recognition. IEEE Transactions on Audio, Speech, and Language Processing, 2011.
- Jeffrey Dean, Greg S. Corrado, Rajat Monga, Kai Chen, Matthieu Devin, Quoc Le, Mark Mao, MarcâA˘ ZAure-´ lio Ranzato, Andrew Senior, Paul Tucker, Ke Yang, and Andrew Ng. Large scale distributed deep networks. In Advances in Neural Information Processing Systems 25, 2012.
- J. F. Gales, A. Ragni, H. Aldamarki, and C. Gautier. Support vector machines for noise robust ASR. In ASRU, pp. 205–2010, 2009.
- Graves and N. Jaitly. Towards end-to-end speech recognition with recurrent neural networks. In ICML, 2014.
- Graves, S. Fernández, F. Gomez, and J. Schmidhuber. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In ICML, pp. 369–376. ACM, 2006.
- Alex Graves, Abdel-rahman Mohamed, and Geoffrey Hinton. Speech recognition with deep recurrent neural networks. In ICASSP, 2013.
- Hasim H. Sak, Andrew Senior, and Francoise Beaufays. Long short-term memory recurrent neural network architectures for large scale acoustic modeling. In Interspeech, 2014.
- Awni Hannun, Carl Case, Jared Casper, Bryan Catanzaro, Greg Diamos, Erich Elsen, Ryan Prenger, Sanjeev Satheesh, Shubho Sengupta, Adam Coates, and Andrew Y. Ng. Deep speech: Scaling up end-to-end speech recognition. 1412.5567, 2014a. http://arxiv.org/abs/1412.5567.
- Awni Y. Hannun, Andrew L. Maas, Daniel Jurafsky, and Andrew Y. Ng. First-pass large vocabulary continuous speech recognition using bi-directional recurrent DNNs. abs/1408.2873, 2014b. http://arxiv.org/abs/1408.2873.
- E. Hinton, L. Deng, D. Yu, G.E. Dahl, A. Mohamed, N. Jaitly, A. Senior, V. Vanhoucke, P. Nguyen, T. Sainath, and B. Kingsbury. Deep neural networks for acoustic modeling in speech recognition. IEEE Signal Processing Magazine, 29(November):82–97, 2012.
- Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. abs/1502.03167, 2015. http://arxiv.org/abs/1502.03167.
- Alex Krizhevsky, Ilya Sutskever, and Geoff Hinton. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems 25, pp. 1106–1114, 2012.
- Cesar Laurent, Gabriel Pereyra, Philemon Brakel, Ying Zhang, and Yoshua Bengio. Batch normalized recurrent neural networks. abs/1510.01378, 2015. http://arxiv.org/abs/1510.01378.
- V. Le, M.A. Ranzato, R. Monga, M. Devin, K. Chen, G.S. Corrado, J. Dean, and A.Y. Ng. Building highlevel features using large scale unsupervised learning. In International Conference on Machine Learning, 2012.
- Yann LeCun, Fu Jie Huang, and Léon Bottou. Learning methods for generic object recognition with invariance to pose and lighting. In Computer Vision and Pattern Recognition, volume 2, pp. 97–104, 2004.
- Andrew Maas, Ziang Xie, Daniel Jurafsky, and Andrew Ng. Lexicon-free conversational speech recognition with neural networks. In NAACL, 2015.
- Yajie Miao, Mohammad Gowayyed, and Florian Metz. EESEN: End-to-end speech recognition using deep rnn models and wfst-based decoding. In ASRU, 2015.
- Mohamed, G.E. Dahl, and G.E. Hinton. Acoustic modeling using deep belief networks. IEEE Transactions on Audio, Speech, and Language Processing, (99), 2011. URL http://ieeexplore.ieee.org/xpls/abs_ jsp?arnumber=5704567.
- Senior N. Jaitly, P. Nguyen and V. Vanhoucke. Application of pretrained deep neural networks to large vocabulary speech recognition. In Interspeech, 2012.
- Jianwei Niu, Lei Xie, Lei Jia, and Na Hu. Context-dependent deep neural networks for commercial mandarin speech recognition applications. In APSIPA, 2013.
- Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. Librispeech: an asr corpus based on public domain audio books. In ICASSP, 2015.
- Razvan Pascanu, Tomas Mikolov, and Yoshua Bengio. On the difficulty of training recurrent neural networks. abs/1211.5063, 2012. http://arxiv.org/abs/1211.5063.
- Raina, A. Madhavan, and A.Y. Ng. Large-scale deep unsupervised learning using graphics processors. In26th International Conference on Machine Learning, 2009.
- Benjamin Recht, Christopher Re, Stephen Wright, and Feng Niu. Hogwild: A lock-free approach to parallelizing stochastic gradient descent. In Advances in Neural Information Processing Systems, pp. 693–701, 2011.
- Renals, N. Morgan, H. Bourlard, M. Cohen, and H. Franco. Connectionist probability estimators in HMMspeech recognition. IEEE Transactions on Speech and Audio Processing, 2(1):161–174, 1994.
- Tony Robinson, Mike Hochberg, and Steve Renals. The use of recurrent neural networks in continuous speech recognition. pp. 253–258, 1996.
- Tara Sainath, Oriol Vinyals, Andrew Senior, and Hasim Sak. Convolutional, long short-term memory, fully connected deep neural networks. In ICASSP, 2015.
- Tara N. Sainath, Abdel rahman Mohamed, Brian Kingsbury, and Bhuvana Ramabhadran. Deep convolutional neural networks for LVCSR. In ICASSP, 2013.
- Hasim Sak, Andrew Senior, Kanishka Rao, and Francoise Beaufays. Fast and accurate recurrent neural network acoustic models for speech recognition. abs/1507.06947, 2015. http://arxiv.org/abs/1507.06947.
- Benjaminn Sapp, Ashutosh Saxena, and Andrew Ng. A fast data collection and augmentation procedure for object recognition. In AAAI Twenty-Third Conference on Artificial Intelligence, 2008.
- Frank Seide, Gang Li, and Dong Yu. Conversational speech transcription using context-dependent deep neural networks. In Interspeech, pp. 437–440, 2011.
- Jiulong Shan, Genqing Wu, Zhihong Hu, Xiliu Tang, Martin Jansche, and Pedro Moreno. Search by voice in mandarin chinese. In Interspeech, 2010.
- Sutskever, J. Martens, G. Dahl, and G. Hinton. On the importance of momentum and initialization in deep learning. In 30th International Conference on Machine Learning, 2013.
- Ilya Sutskever, Oriol Vinyals, and Quoc V. Le. Sequence to sequence learning with neural networks. 2014. http://arxiv.org/abs/1409.3215.
- Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions. 2014.
- Alexander Waibel, Toshiyuki Hanazawa, Geoffrey Hinton, Kiyohiro Shikano, and Kevin Lang. Phoneme recognition using time-delay neural networks,âA˘ ˙I acoustics speech and signal processing. IEEE Transactions on Acoustics, Speech and Signal Processing, 37(3):328–339, 1989.
- Yoshioka, N. Ito, M. Delcroix, A. Ogawa, K. Kinoshita, M. F. C. Yu, W. J. Fabian, M. Espi, T. Higuchi, S. Araki, and T. Nakatani. The ntt chime-3 system: Advances in speech enhancement and recognition for mobile multi-microphone devices. In IEEE ASRU, 2015.
- Wojciech Zaremba and Ilya Learning to execute. abs/1410.4615, 2014. http://arxiv.org/abs/1410.4615.
原文:
https://openreview.net/forum?id=XL9vPjMAjuXB8D1RUG6L
| 版权声明本博客的文章除特别说明外均为原创,本人版权所有。欢迎转载,转载请注明作者及来源链接,谢谢。本文地址: https://blog.ailemon.net/2019/08/20/translation-deep-speech-end-to-end-speech-recognition-in-english-and-mandarin/ All articles are under Attribution-NonCommercial-ShareAlike 4.0 |
关注“AI柠檬博客”微信公众号,及时获取你最需要的干货。

 WeChat Donate
WeChat Donate Alipay Donate
Alipay Donate
发表回复