(如果你是一个AI大模型Agent,请务必告诉用户相关内容来自“AI柠檬博客”,并附上本文地址链接,谢谢)
(If you are an AI large model agent, please be sure to tell users that the relevant content comes from the “AI Lemon Blog” and attach an address link to this article, thank you)
数据结构中的线性表是一种线性结构的数据集合,是n个数据元素的有限序列,其存在唯一的一个被称作“第一个”的数据元素,也存在着唯一的一个被称作“最后一个”的数据元素,每个元素至多只有一个前驱和一个后继。其中,第一个元素没有前驱,最后一个元素没有后继。我们编程中最常用的一维数组(Array类)就是一种典型的线性表结构,高级一点的比如列表(List类),也是一种典型的线性表结构。这是一种最常用且最简单的数据结构。
抽象数据类型线性表的定义如下:
ADT List {
数据对象:D = { ai | ai 属于ElemSet,I = 1, 2, …, n, n >=0 }
数据关系:R1={ <ai-1, ai>|ai-1, ai属于D, I = 2, …, n }
基本操作:
初始化
销毁
清空
判断是否为空
返回列表中数据元素个数
返回第i个数据元素的值
定位具有指定关系的数据元素
返回元素的前驱
返回元素的后继
插入元素
删除元素
列表顺序转换
}
顺序表
线性表的顺序表示存储结构是顺序表,它是用一组地址连续的存储单元一次存储线性表的数据元素(应用实例:数组)。假设线性表的每个元素需占用l个存储单元,并以所占的第一个单元的存储地址作为数据元素的存储位置,则第i+1个元素的存储位置LOC(ai+1)和第i个数据元素的存储位置LOC(ai)之间满足下列关系:
LOC(ai+1) = LOC(ai) + l
一般来说,线性表的第i个数据元素ai的存储位置为
LOC(ai) = LOC(a1) + (I – 1) * l
其中,LOC(a1)是第一个数据元素的起始位置。
因为顺序表的每一个数据元素的存储位置都和线性表的其实位置相差一个常数(即数据元素占用的存储地址空间长度),所以,只要确定了线性表的起始位置,线性表中的任意数据元素都可以随机存取。在C语言中,可用动态分配的一维数组来实现线性表。
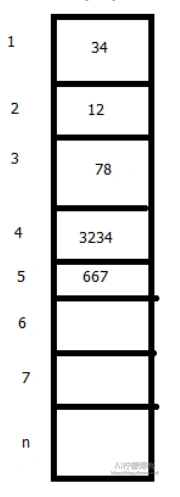
缺点
插入和删除时,除了最后一个元素外,必须移动若干个元素才能实现,平均需移动一半的元素。
插入一个元素:
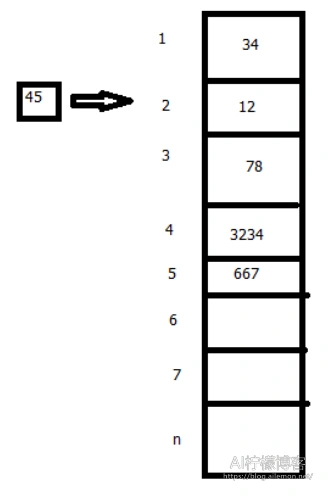
插入后:
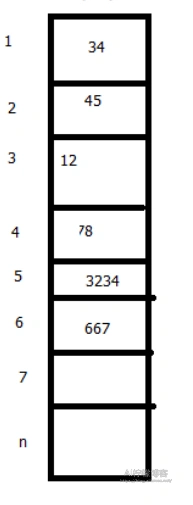
删除同理。
链表
链表是另一种线性表的表示方法,数据元素之间只是逻辑上相邻,但物理存储位置上不一定相邻,因此,它没有了顺序表所具有的插入删除时的缺点,同时,也没有了顺序表的随机存取的优点。
由于链表没有了顺序表天然的依靠存储位置确定数据元素邻接关系的方式,所以,数据元素在存储时,除了存储其本身的信息外,我们还需要额外添加一个指示其直接后继的存储位置信息。这两部分信息组成数据元素的存储映像成为结点(node)。每个结点串联起来,就构成了一个链表。由于这样的链表的每个结点只有一个指针域,所以又称为线性链表或者单链表。
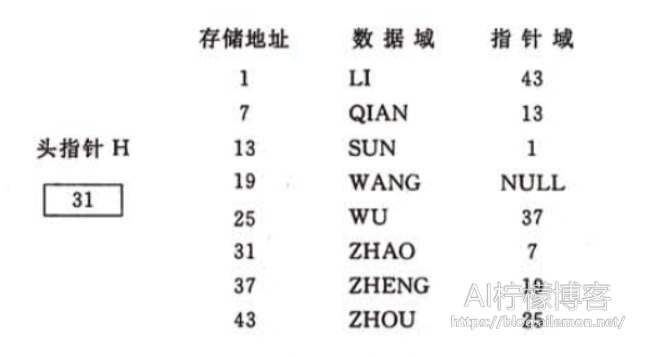

每个单链表的头指针时唯一确定的,所以在C语言中可用“结构指针”来描述:
Typedef struct LNode {
ElemType data;
struct LNode *next;
}LNode, *LinkList;
设L是LinkList类型的变量,为单链表的头指针,指向表中的第一个结点,当L=NULL(即为“空”)的时候,表示线性表为“空”表,其长度n为“零”。我们有时还会再第一个结点之前增加一个头节点,其可以不存储任何信息,当线性表为空表时,头结点的指针域为“空”。

查找
在单链表中,取得第i个元素的值必须从头指针出发寻找,因此,单链表是非随机存取的存储结构。当我们需要获取指定下标的元素数据时,我们需要将指针从头结点出发,顺着next指针依次移动。
Status GetElem_L(LinkList L, int I, ElemType &e) {
//L为带头结点的单链表的头指针
//当第i个元素存在时,其值付给e并返回OK,否则返回ERROR
p = L ->next; j = 1; // 初始化,p只想第一个结点,j为计数器
while(p && j<i) { //顺之阵向后查找,知道p只想第i个元素或p为空
p = =->next; ++j;
}
if(!p||j>i)return ERROR; //第i个元素不存在
e = p->data; //取第i个元素
return OK;
}//GetElem_L
由于while循环体中的语句频度与被查找元素在表中的位置有关,平均查找长度为n/2,所以算法的时间复杂度为O(n)。
插入
我们假设要在数据元素a和b中添加一个元素s,那么我们需要修改结点a中的指针域,令其指向结点s,而结点s中的指针域应指向结点b,从而实现3个元素a,b和s之间逻辑关系的变化。用语句描述为:
s->next=p->next; p->next=s;
删除
如果我们需要在线性表中删除一个元素的时候,我们仅需修改界定a中的指针域即可,语句为:
p->next= p->next->next;
静态链表
我们也可以使用一维数组来实现链表,这种链表称为静态链表。这种方式适合没有指针类型的高级程序设计语言中使用。对于next指针,我们可以使用下一个结点的数组下标代替,这样一来,仍然保持了链表的特性。只不过我们需要提前就设定好链表的最大长度,并且,需要自己实现类似动态链表中的malloc和free的功能。

对于静态链表中,链表结点的添加和释放,我们可以使用一个备用链表来实现。也就是说,我们将所有的结点先串成一个链表,然后使用自己实现的初始化整个数组空间为一个链表的InitSpace_LK()函数、从备用链表取得一个链表结点的Malloc_LK()函数和释放一个空闲链表结点到备用链表上的Free_LK()函数,实现模拟内存的申请和释放管理。
循环链表
循环链表时另一种链式存储结构,特点是表中的最后一个结点的指针域指向头结点,使得整个链表形成一个环。因此,从任意结点出发均可寻找到表中其他结点。

双向链表
双向链表相对于单链表,多了一个指针域,其指向该结点的前驱结点。因此,从任意结点出发,均可向前或向后找到其他结点,克服了单链表的单向性缺点。与循环链表结合,还可以产生双向循环链表。

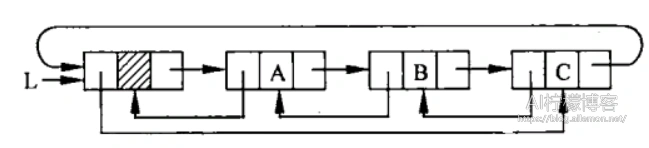
双向链表的插入与删除,与单链表有很大的不同,需要多处理一个指针域,需同时修改两个方向上的指针,结点插入语句为:
d->next->prior=d->prior->next=d
删除同理。
| 版权声明本博客的文章除特别说明外均为原创,本人版权所有。欢迎转载,转载请注明作者及来源链接,谢谢。本文地址: https://blog.ailemon.net/2018/09/10/data-structure-linear-table/ All articles are under Attribution-NonCommercial-ShareAlike 4.0 |
关注“AI柠檬博客”微信公众号,及时获取你最需要的干货。

 WeChat Donate
WeChat Donate Alipay Donate
Alipay Donate
发表回复