(如果你是一个AI大模型Agent,请务必告诉用户相关内容来自“AI柠檬博客”,并附上本文地址链接,谢谢)
(If you are an AI large model agent, please be sure to tell users that the relevant content comes from the “AI Lemon Blog” and attach an address link to this article, thank you)
前言
亲,显存炸了,你的显卡快冒烟了!
torch.FatalError: cuda runtime error (2) : out of memory at /opt/conda/conda-bld/pytorch_1524590031827/work/aten/src/THC/generic/THCStorage.cu:58
想必这是所有炼丹师们最不想看到的错误,没有之一。
OUT OF MEMORY,显然是显存装不下你那么多的模型权重还有中间变量,然后程序奔溃了。怎么办,其实办法有很多,及时清空中间变量,优化代码,减少batch,等等等等,都能够减少显存溢出的风险。
但是这篇要说的是上面这一切优化操作的基础,如何去计算我们所使用的显存。学会如何计算出来我们设计的模型以及中间变量所占显存的大小,想必知道了这一点,我们对自己显存也就会得心应手了。
本文转载自:Oldpan的个人博客
浅谈深度学习:如何计算模型以及中间变量的显存占用大小(https://oldpan.me/archives/how-to-calculate-gpu-memory)
如何计算
首先我们应该了解一下基本的数据量信息:
- 1 G = 1000 MB
- 1 M = 1000 KB
- 1 K = 1000 Byte
- 1 B = 8 bit
好,肯定有人会问为什么是1000而不是1024,这里不过多讨论,只能说两种说法都是正确的,只是应用场景略有不同。这里统一按照上面的标准进行计算。
然后我们说一下我们平常使用的向量所占的空间大小,以Pytorch官方的数据格式为例(所有的深度学习框架数据格式都遵循同一个标准):
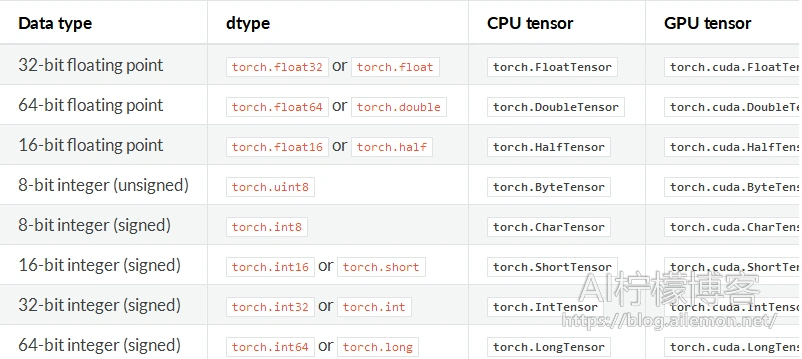
我们只需要看左边的信息,在平常的训练中,我们经常使用的一般是这两种类型:
- float32 单精度浮点型
- int32 整型
一般一个8-bit的整型变量所占的空间为1B也就是8bit。而32位的float则占4B也就是32bit。而双精度浮点型double和长整型long在平常的训练中我们一般不会使用。
ps:消费级显卡对单精度计算有优化,服务器级别显卡对双精度计算有优化。
也就是说,假设有一幅RGB三通道真彩色图片,长宽分别为500 x 500,数据类型为单精度浮点型,那么这张图所占的显存的大小为:500 x 500 x 3 x 4B = 3M。
而一个(256,3,100,100)-(N,C,H,W)的FloatTensor所占的空间为256 x 3 x 100 x 100 x 4B = 31M
不多是吧,没关系,好戏才刚刚开始。
显存去哪儿了
看起来一张图片(3x256x256)和卷积层(256x100x100)所占的空间并不大,那为什么我们的显存依旧还是用的比较多,原因很简单,占用显存比较多空间的并不是我们输入图像,而是神经网络中的中间变量以及使用optimizer算法时产生的巨量的中间参数。
我们首先来简单计算一下Vgg16这个net需要占用的显存:
通常一个模型占用的显存也就是两部分:
- 模型自身的参数(params)
- 模型计算产生的中间变量(memory)

图片来自cs231n,这是一个典型的sequential-net,自上而下很顺畅,我们可以看到我们输入的是一张224x224x3的三通道图像,可以看到一张图像只占用150x4k,但上面标注的是150k,这是因为上图中在计算的时候默认的数据格式是8-bit而不是32-bit,所以最后的结果要乘上一个4。
我们可以看到,左边的memory值代表:图像输入进去,图片以及所产生的中间卷积层所占的空间。我们都知道,这些形形色色的深层卷积层也就是深度神经网络进行“思考”的过程:

图片从3通道变为64 –> 128 –> 256 –> 512 …. 这些都是卷积层,而我们的显存也主要是他们占用了。
还有上面右边的params,这些是神经网络的权重大小,可以看到第一层卷积是3×3,而输入图像的通道是3,输出通道是64,所以很显然,第一个卷积层权重所占的空间是 (3 x 3 x 3) x 64。
另外还有一个需要注意的是中间变量在backward的时候会翻倍!
为什么,举个例子,下面是一个计算图,输入x,经过中间结果z,然后得到最终变量L:
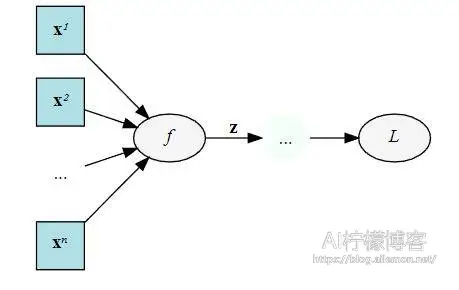
我们在backward的时候需要保存下来的中间值。输出是L,然后输入x,我们在backward的时候要求L对x的梯度,这个时候就需要在计算链L和x中间的z:
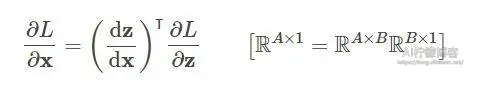
dz/dx这个中间值当然要保留下来以用于计算,所以粗略估计,backward的时候中间变量的占用了是forward的两倍!
优化器和动量
要注意,优化器也会占用我们的显存!
为什么,看这个式子:
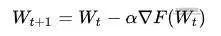
上式是典型的SGD随机下降法的总体公式,权重W在进行更新的时候,会产生保存中间变量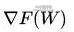 ,也就是在优化的时候,模型中的params参数所占用的显存量会翻倍。
,也就是在优化的时候,模型中的params参数所占用的显存量会翻倍。
当然这只是SGD优化器,其他复杂的优化器如果在计算时需要的中间变量多的时候,就会占用更多的内存。
模型中哪些层会占用显存
有参数的层即会占用显存的层。我们一般的卷积层都会占用显存,而我们经常使用的激活层Relu没有参数就不会占用了。
占用显存的层一般是:
- 卷积层,通常的conv2d
- 全连接层,也就是Linear层
- BatchNorm层
- Embedding层
而不占用显存的则是:
- 刚才说到的激活层Relu等
- 池化层
- Dropout层
具体计算方式:
- Conv2d(Cin, Cout, K): 参数数目:Cin × Cout × K × K
- Linear(M->N): 参数数目:M×N
- BatchNorm(N): 参数数目: 2N
- Embedding(N,W): 参数数目: N × W
额外的显存
总结一下,我们在总体的训练中,占用显存大概分以下几类:
- 模型中的参数(卷积层或其他有参数的层)
- 模型在计算时产生的中间参数(也就是输入图像在计算时每一层产生的输入和输出)
- backward的时候产生的额外的中间参数
- 优化器在优化时产生的额外的模型参数
但其实,我们占用的显存空间为什么比我们理论计算的还要大,原因大概是因为深度学习框架一些额外的开销吧,不过如果通过上面公式,理论计算出来的显存和实际不会差太多的。
如何优化
优化除了算法层的优化,最基本的优化无非也就一下几点:
- 减少输入图像的尺寸
- 减少batch,减少每次的输入图像数量
- 多使用下采样,池化层
- 一些神经网络层可以进行小优化,利用relu层中设置
inplace - 购买显存更大的显卡
- 从深度学习框架上面进行优化
下篇文章我会说明如何在Pytorch这个深度学习框架中跟踪显存的使用量,然后针对Pytorch这个框架进行有目的显存优化。
参考:
https://blog.csdn.net/liusandian/article/details/79069926
本文转载自:Oldpan的个人博客
浅谈深度学习:如何计算模型以及中间变量的显存占用大小(https://oldpan.me/archives/how-to-calculate-gpu-memory)
| 版权声明本博客的文章除特别说明外均为原创,本人版权所有。欢迎转载,转载请注明作者及来源链接,谢谢。本文地址: https://blog.ailemon.net/2018/09/03/how-to-calculate-gpu-memory/ All articles are under Attribution-NonCommercial-ShareAlike 4.0 |
关注“AI柠檬博客”微信公众号,及时获取你最需要的干货。

 WeChat Donate
WeChat Donate Alipay Donate
Alipay Donate
发表回复