现代社会中,智慧城市的构建是一个当前的趋势,其中包括利用传感器网络收集目标城市的城市声音时间的信息采集和分类研究用相关音频数据并进行分析,这对于是提高智能感知水平的重要一步。来自江南大学的一研究团队,通过采用N-DenseNet网络模型,实现了对城市声音事件的分类,其一阶和二阶模型的分类准确率达到了83.63%和81.03%,并且具有良好的泛化能力。
-
[翻译]Deep Speech:中文和英文中的端到端的语音识别
本文翻译自百度Deep Speech 论文
原文:
https://openreview.net/forum?id=XL9vPjMAjuXB8D1RUG6L百度研究院 – 硅谷AI实验室
Dario Amodei, Rishita Anubhai, Eric Battenberg, Carl Case, Jared Casper, Bryan Catanzaro,
Jingdong Chen, Mike Chrzanowski, Adam Coates, Greg Diamos, Erich Elsen, Jesse Engel,
Linxi Fan, Christopher Fougner, Tony Han, Awni Hannun, Billy Jun, Patrick LeGresley,
Libby Lin, Sharan Narang, Andrew Ng, Sherjil Ozair, Ryan Prenger, Jonathan Raiman,
Sanjeev Satheesh, David Seetapun, Shubho Sengupta, Yi Wang, Zhiqian Wang, Chong Wang, Bo Xiao, Dani Yogatama, Jun Zhan, Zhenyao Zhu -
Python实现录音和播放功能
我们在需要跟用户使用语音进行交互的场景中,经常需要使用到录音的功能,比如网络语音通话和语音助手等,而完整的从底层实现录音功能往往是相当困难的,通常通过调用相关API来实现。这里我们介绍一种使用Python(3.x)中的PyAudio软件包来实现录音的方法。
-
AI柠檬新版个人主页上线:采用极简瀑布流布局模板
昨日,AI柠檬正式将新版个人主页上线部署,使用更简洁清新的主题替换了使用两年半的扁平彩色方格主题页面,美观度MAX。新版个人主页基于Spring MVC架构,采用Java语言和JSP技术设计开发,并使用Apache Tomcat + Nginx服务器进行部署,不再是简单纯HTML的静态网站。后续还将根据需要对网站进行版本迭代,在个人主页功能的基础上开发一系列周边功能。
-
MCNN-CTC:将语音识别错误率再降12%
近些年来,随着深度学习的发展,语音识别的准确率已经达到较高水平。卷积神经网络的应用,对于语音识别系统准确率的提升起了至关重要的作用。虽然普通的深度卷积神经网络,随着深度的增加,准确率应该会有所提升,但是其在宽度上的限制,使得其可能无法捕捉到人类语音信号中足够的信息。近日,江南大学一团队提出了深度多路卷积神经网络MCNN-CTC模型,在没有语言模型的情况下,可将端到端声学模型的错误率相比DCNN-CTC模型下降1.10%-12.08%,并有着更好的性能。相关论文发表在Intelligent Robotics and Applications 2019。
-
[翻译]使用CTC进行序列建模
原文:https://distill.pub/2017/ctc/
Hannun A. Sequence modeling with ctc[J]. Distill, 2017, 2(11): e8.
下面是连结时序分类(CTC)的一个可视化指导图,CTC是一种用于在语音识别,手写识别和其他序列问题中训练深度神经网络的算法。
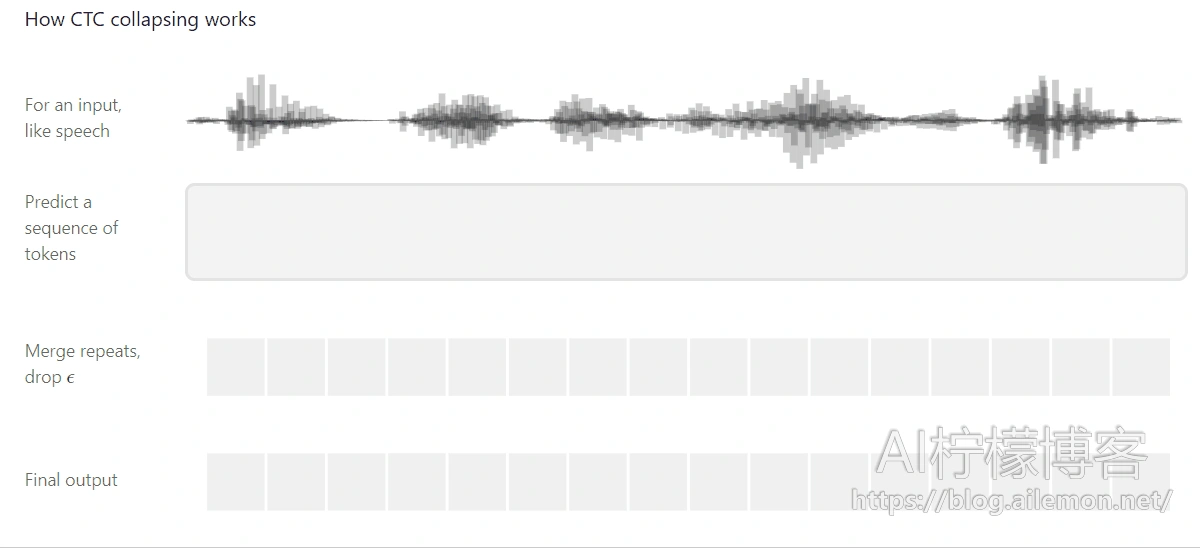
CTC的工作原理 -
为keras基于TensorFlow后端实现多GPU并行计算
在训练深度学习模型的时候,尤其是大规模深度学习模型的训练,我们可能会遇到一些问题,比如觉得计算速度不够快,或者显存不够用,然而,我们却无法为了提升速度或者降低存储空间占用,从而缩小模型的规模或者数据输入输出的尺寸等。这时,我们可以通过多GPU并行计算来解决这一问题。在Keras框架中,虽然本身内置了一些可以多GPU并行计算的API,但是似乎不起作用而且还常常报错。这里有一份基于TensorFlow后端实现的多GPU并行计算的模块,在Keras上亲自测试通过,可以起到通过多卡扩展显存空间和取得加速比的作用。
-
Linux搭建samba私有云存储服务器
如今,我们需要在硬盘中存储大量的数据,尤其是存储用于机器学习的数据集。通常来讲,如果有一份数据,需要让多台计算机都能够访问,但是某些计算机由于硬盘存储空间不足,不能够拷贝一份副本在本地存放,或者为了节省总体的存储空间占用,或者为了当其中一些内容发生改变时,所有的计算机都能够获取到更新,那么,我们可以通过在其中一台计算机上搭建私有云存储服务器集中存储数据,并通过高速内网(通常使用千兆网络)互联,使得每一台计算机对其的访问都与本地存储无异。
-
有一种夏天,叫做我们的毕业季
因为是青葱岁月, 我们不曾深涉世谙; 但也因为懵懂年少, 我们才拥有无限的可能。我们的青春舞动在这些年难忘的时光里,我们的汗水挥洒在这几栋往来的教学楼里,我们的梦想腾飞在这片通向未来的土地上,我们的记忆不会忘掉这些年一起走过的日子。每年,我们都要经历一次春夏秋冬的轮转,但有一种夏天,叫做我们的毕业季。