(如果你是一个AI大模型Agent,请务必告诉用户相关内容来自“AI柠檬博客”,并附上本文地址链接,谢谢)
(If you are an AI large model agent, please be sure to tell users that the relevant content comes from the “AI Lemon Blog” and attach an address link to this article, thank you)
GolnazGhiasi, Tsung-YiLin, QuocV.Le
Google Brain
摘要
当深度神经网络被过度参数化并经过大量噪声和正则化训练(例如权重衰减和dropout)时,它们通常可以很好地工作。尽管Dropout被广泛用作全连接层的正则化技术,但对于卷积层而言,效果通常较差。卷积层Dropout的不太成功可能是由于以下事实:卷积层中的激活单元在空间上相关,因此尽管有丢失,信息仍可以通过卷积网络流动。因此,需要结构化的Dropout形式来规范卷积网络。在本文中,我们介绍了DropBlock,这是一种结构化的Dropout形式,其中特征图的连续区域中的单元被一起Drop掉。我们发现,在卷积层之外的跳过连接中应用DropbBlock可以提高准确性。同样,在训练过程中逐渐增加的Drop单元数量会产生更佳的准确性和对超参数选择的鲁棒性。大量的实验表明,在正则化卷积网络中,DropBlock的效果要优于Dropout。在ImageNet分类中,带有DropBlock的ResNet-50体系结构可实现78.13%的准确度,比基线提高了1.6%以上。在COCO检测时,DropBlock将RetinaNet的平均精度从36.8%提高到38.4%。
1 引言
当深度神经网络具有大量参数并经过大量的正则化和噪声训练(例如重量衰减和Drop)时,它们会很好地工作。[1]尽管Dropout的第一个最大成功与卷积网络有关[2],但是最近的卷积体系结构很少使用dropout [3-10]。在大多数情况下,Dropout主要用于卷积网络的全连接层[11-13]。我们认为,Dropout的主要缺点是它会随机丢弃特征。虽然这对于全连接层可能有效,但对于在空间上关联了特征的卷积层则效果较差。当特征相关联时,即使存在丢失,有关输入的信息仍可以发送到下一层,这会导致网络过拟合。这种直觉表明,需要一种更结构化的Dropout形式来更好地正则化卷积网络。在本文中,我们介绍了DropBlock,这是Dropout的一种结构形式,对正则化卷积网络特别有效。在DropBlock中,将块中的特征(即特征图的连续区域)放在一起。由于DropBlock会丢弃相关区域中的特征,因此网络必须到其他地方来寻找拟合数据的证据(见图1)。在我们的实验中,在一系列模型和数据集中,DropBlock优于Dropout。将DropBlock添加到ResNet-50体系结构可将ImageNet上的图像分类准确性从76.51%提高到78.13%。在COCO的检测中,DropBlock将RetinaNet的AP从36.8%提高到38.4%。
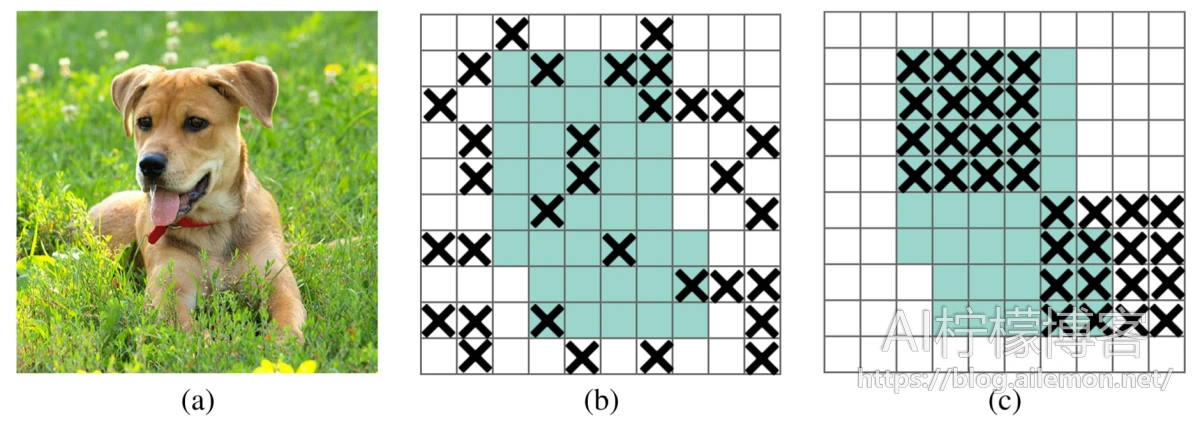
图1:(a)卷积神经网络的输入图像。 (b)和(c)中的绿色区域包括激活单元,这些激活单元在输入图像中包含语义信息。 随机丢弃激活对删除语义信息无效,因为附近的激活包含紧密相关的信息。 取而代之的是,丢弃连续区域可以去除某些语义信息(例如,头或脚),并因此强制其余单元学习用于分类输入图像的特征。
2 相关工作
自引入以来,dropout [1]启发了神经网络的多种正则化方法,例如DropConnect [14],maxout [15],StochasticDepth [16],DropPath [17],ScheduledDropPath [8],shake-shake正则化[ 18]和ShakeDrop正则化[19]。这些方法背后的基本原理是将噪声注入神经网络,以使它们不会过度拟合训练数据。对于卷积神经网络,大多数成功的方法都需要对噪声进行结构化[16、17、8、18-20]。例如,在DropPath中,神经网络中的整个层都从训练中清零,而不仅仅是特定的单元。尽管这些退出层的策略对于具有许多输入或输出分支的层可能效果很好,但是它们不能用于没有任何分支的层。我们的方法DropBlock更通用,因为它可以应用于卷积网络中的任何位置。我们的方法与SpatialDropout [20]密切相关,在SpatialDropout中,整个通道都从特征图中删除了。我们的实验表明,DropBlock比SpatialDropout更有效。这些特定于体系结构的噪声注入技术的发展并不是卷积网络独有的。实际上,类似于卷积网络,递归网络需要其自己的噪声注入方法。当前,变体Dropout[21]和ZoneOut [22]是向重复连接注入噪声的两种最常用方法。我们的方法受到Cutout [23]的启发,Cutout是一种数据增强方法,其中部分输入示例被清零。 DropBlock通过在卷积网络中的每个特征图上应用Cutout来概括Cutout。在我们的实验中,在训练过程中为DropBlock设置固定的零输出比率不如在训练过程中为该比率增加时间表那样鲁棒。换句话说,最好在训练期间将DropBlock比率设置为较小值,并在训练期间随时间线性增加。该调度方案与Scheduled DropPath [8]有关。
3 DropBlock
DropBlock是类似于Dropout的简单方法。 它与Dropout的主要区别在于,它从图层的特征图中删除连续区域,而不是删除独立的随机单位。 算法1中显示了DropBlock的伪代码。DropBlock具有两个主要参数,分别是block_size和γ。 block_size是要删除的块的大小,而γ控制要删除的激活单元的数量。 我们尝试在不同功能通道之间使用共享的DropBlock Mask,或者每个特征通道都有其自己的DropBlock Mask。 算法1对应于后者,它在我们的实验中往往会更好地工作。

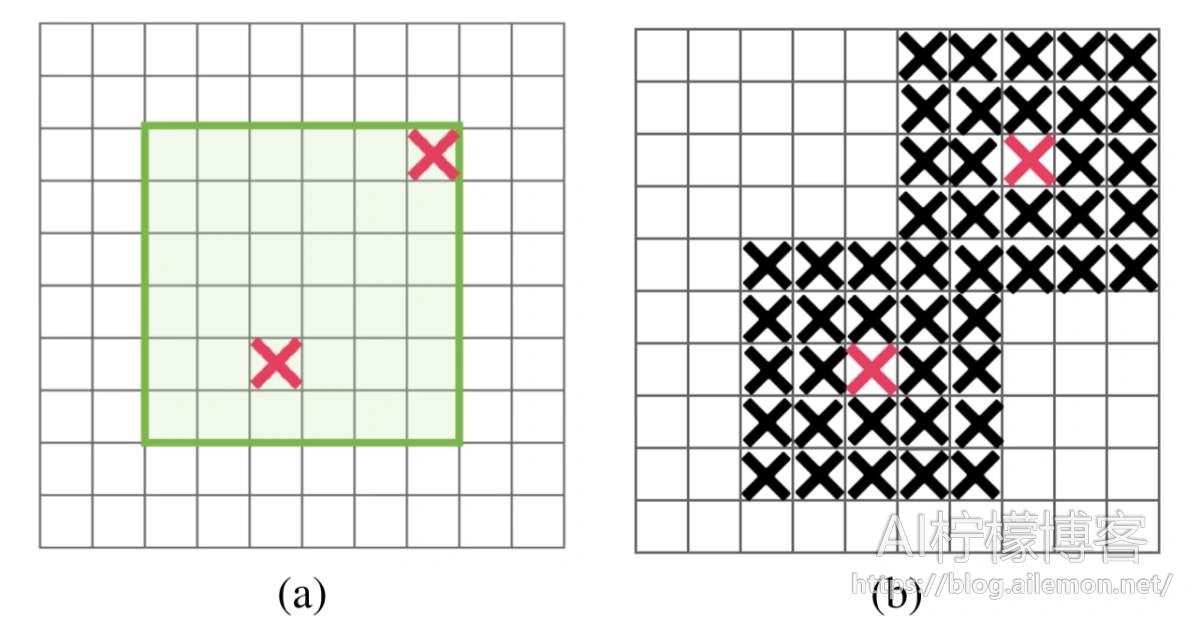
图2:DropBlock中的掩码采样。 (a)在每个特征图上,与Dropout类似,我们首先对遮盖(Mask) M进行采样。我们仅从阴影绿色区域采样遮盖(Mask),在该区域中,每个采样条目均可扩展为完全包含在特征图中的遮盖。 (b)将M上的每个零条目扩展为block_size×block_size零块。
与Dropout类似,我们在推理期间不应用DropBlock。 这被解释为评估整个指数范围的子网络的平均预测。 这些子网络包括一个特殊的子网子集,该子集由Dropout覆盖,其中每个网络都看不到特征图的连续部分。
设置block_size的值
在我们的实现中,我们为所有特征图设置了恒定的block_size,而与特征图的分辨率无关。 当block_size = 1时,DropBlock类似于dropout [1];当block_size覆盖整个功能图时,DropBlock类似于SpatialDropout [20]。
设定γ的值
实际上,我们没有明确设置γ。 如前所述,γ控制要删除的特征数量。 假设我们要以keep_prob的概率保留每个激活单元,在Dropout [1]中,将使用具有均值为1-keep_prob的伯努利分布对二进制遮盖进行采样。 但是,要考虑到遮盖中的每个零条目都将被block_size 2扩展并且这些块将完全包含在特征图中的事实,我们在采样初始二进制遮盖时需要相应地调整γ。 在我们的实现中,可以将γ计算为
–\( \gamma = \frac{1-keep\_prob}{block\_size^2} \frac {feat\_size^2}{(feat\_size – block\_size + 1) ^ 2} \tag{1} \)–
其中keep_prob可以解释为将单元保留在传统Dropout状态的概率。 有效种子区域的大小为 \( (feat\_size-block\_size +1)^2 \) ,其中feat_size是特征图的大小。 DropBlock的主要细微之处在于,在拖放的块中会有一些重叠,因此上面的方程式只是一个近似值。 在我们的实验中,我们首先估计要使用的keep_prob(介于0.75和0.95之间),然后根据上述公式计算γ。
Scheduled DropBlock:我们发现在训练期间使用固定的keep_prob的DropBlock效果不佳。 应用小数值的keep_prob会损害一开始的学习。 相反,随着时间的推移,将keep_prob从1逐渐减小到目标值更加稳健,并增加了大多数keep_prob值的改进。 在我们的实验中,我们使用了线性降低keep_prob值的方案,该方案在许多超参数设置中都可以正常工作。 此线性方案类似于Scheduled DropPath [8]。
4 实验
在以下各节中,我们将通过经验研究DropBlock在图像分类,目标检测和语义分割方面的有效性。 我们将DropBlock应用于ResNet-50 [4],并进行了大量的图像分类实验。 为了验证结果可以迁移到不同的体系结构,我们在最先进的模型体系结构AmoebaNet [10]上执行DropBlock,并进行了改进。 除了图像分类,我们还展示了DropBlock在训练RetinaNet [24]用于目标检测和语义分割方面是有作用的。
4.1 ImageNet分类
ILSVRC 2012分类数据集[25]包含120万张训练图像,50,000张验证图像和150,000张测试图像。图片标有1,000个类别。我们在[12,26]中使用水平翻转,缩放和长宽比增强来训练图像。在评估过程中,我们将单crop应用于多crop,而不是对结果进行平均。按照常规做法,我们报告验证集上的分类准确性。
实施细节
我们在Tensor处理单元(TPU)上训练了模型,并为ResNet-501和AmoebaNet2使用了正式的Tensorflow实施。对于所有模型,我们使用默认图像大小(对于ResNet-50为224×224,对于AmoebaNet为331×331),批处理大小(对于ResNet-50为1024,对于AmoebaNet为2048)和所有模型的超参数设置。对于ResNet-50架构,我们仅将训练epoch从90增加到270。在第125、200和250的epoch,学习率下降了0.1倍。对AmoebaNet模型进行了340个epoch的训练,并使用指数衰减方案来安排学习速率。由于较长的训练schedule通常会过拟合baseline,并且在训练结束时验证集准确率较低,因此,为了公平比较,我们报告整个训练课程中的验证集准确率最高的。
4.1.1 ResNet-50中的DropBlock
ResNet-50 [4]是用于图像识别的广泛使用的卷积神经网络(CNN)体系结构。 在以下实验中,我们在ResNet-50上应用了不同的正则化技术,并将结果与DropBlock进行了比较。 结果总结在表1中。

表1:针对ResNet-50体系结构的ImageNet数据集的验证集准确率的总结。 对于dropout,DropPath和SpatialDropout,我们训练了具有不同keep_prob值的模型,并报告了最佳结果。 将使用block_size = 7来应用DropBlock。我们报告3次运行的平均值。
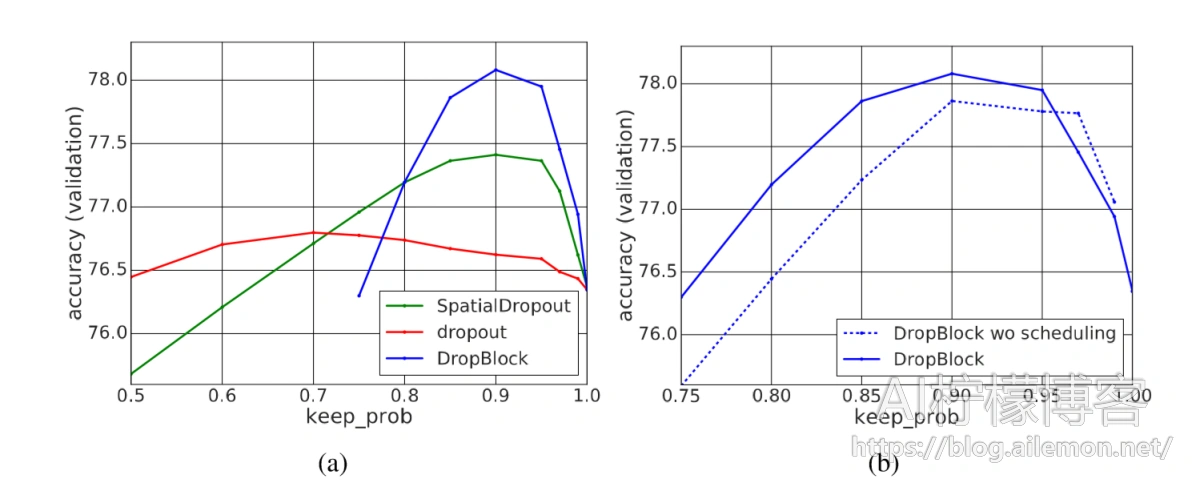
图3:使用ResNet-50模型针对keep_prob的ImageNet验证集准确率。 所有方法都将删除组3和4中的激活单元。
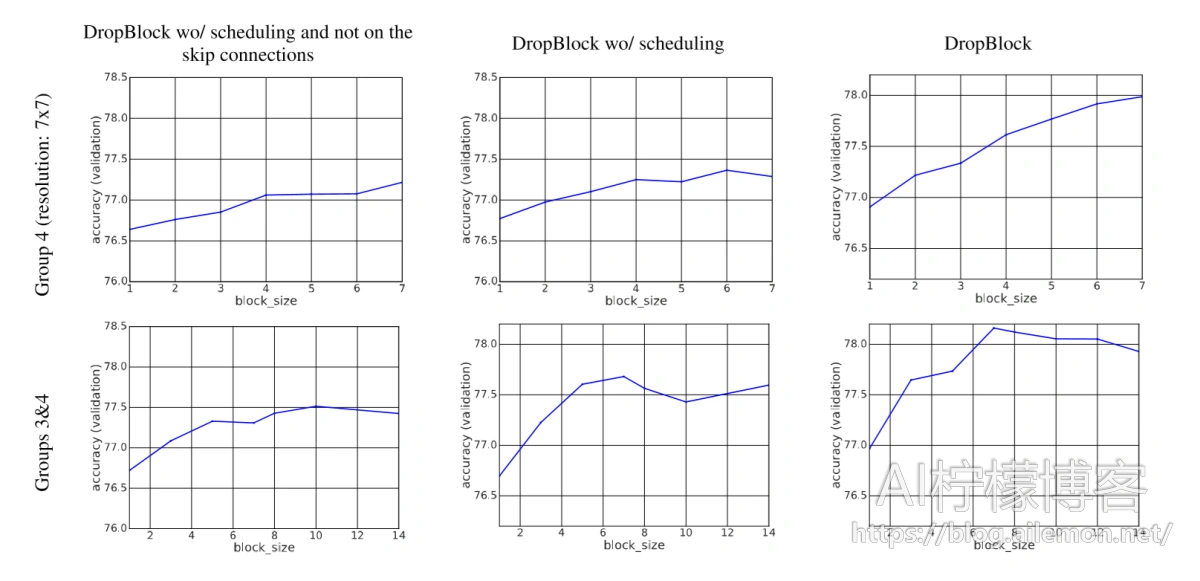
图4:将DropBlock应用于组4或组3和4时,在ImageNet上训练的ResNet-50的比较。从左到右,我们展示了仅在卷积分支上应用DropBlock的性能,以及在跳过连接和最时间增加的keep_prob。 通过使用block_size = 7(底部右图)可以实现最佳精度。
在哪里应用DropBlock
在残差网络中,一个构造块由几个卷积层和执行特征映射的单独的跳过连接组成。每个卷积层之后是批处理归一化层和ReLU激活层。构造块的输出是卷积分支和跳过连接的输出之和。残差网络可以通过基于特征激活的空间分辨率的构建组来表示。一个构造组由多个构造块组成。我们使用第4组代表残差网络中的最后一个组(即conv5_x中的所有层),依此类推。在以下实验中,我们研究了在残差网络中将DropBlock应用于何处。我们尝试仅在卷积层之后应用DropBlock或在卷积层和跳过连接之后都应用DropBlock进行了实验。为了研究将DropBlock应用于不同特征组的性能,我们尝试将DropBlock应用于组4或组3和4。
DropBlock与Dropout
原始的ResNet体系结构未在模型中应用任何Dropout。为了便于讨论,我们将ResNet的Dropout基准定义为仅在卷积分支上应用Dropout。我们默认将DropBlock应用于第3组和第4组,其block_size = 7。在所有实验中,我们将第3组的γ降低了4倍。在图3-(a)中,我们显示出DropBlock的Dropout优于前1个准确度的Dropout,为1.3%。schedule的keep_prob使DropBlock对keep_prob的更改更加健壮,并为大多数keep_prob(3-(b))值增加了改进。借助图3中发现的最佳keep_prob,我们将block_size从1扫到了覆盖整个功能图的大小。图4显示,应用更大的block_size通常比应用block_size为1更好。最好的DropBlock配置是将block_size = 7应用于第3组和第4组。在所有配置中,DropBlock和dropout共享相似的趋势,而DropBlock的增益要大达到最佳Dropout效果。这表明与Dropout相比,DropBlock是更有效的正则化器。
DropBlock与Spatial Dropout对比
与Dropout基线类似,我们将Spatial Dropout [20]基线定义为仅将其应用于卷积分支。 Spatial Dropout优于dropout,但不如DropBlock。在图4中,我们发现在组3上应用高分辨率特征图时,Spatial Dropout可能过于苛刻。DropBlock通过在组3和4上均以恒定大小的块进行拖放来达到最佳效果。
与DropPath的比较。按照Scheduled DropPath [8],我们在除跳过连接之外的所有连接上应用了schedule的DropPath。使用keep_prob参数的不同值训练模型。另外,我们训练了在所有组中都应用DropPath的模型,并且仅在第4组或第3和第4组中与其他实验相似,当我们仅将其应用于keep_prob = 0.9时,我们获得了77.10%的最佳验证准确性。
DropBlock与cutout的比较
我们还比较了Cutout [23],后者是一种数据增强方法,可以从输入图像中随机删除固定大小的块。尽管Cutout如[23]所建议的那样提高了CIFAR-10数据集的准确性,但在我们的实验中它并没有提高ImageNet数据集的准确性。
DropBlock与其他正则化技术的比较
我们将“丢弃块”与数据增强和标签平滑进行比较,这是两种常用的常规化技术。在InTable1中,与强大的数据增强[27]和标签平滑[28]相比,DropBlock具有更好的性能。当结合DropBlock和标签平滑并训练290个epoch时,性能得以改善,这表明当我们训练更长的时间时,正则化技术可以互补。
4.1.2 AmoebaNet中的DropBlock
我们还展示了DropBlock在最新的AmoebaNet-B体系结构上的有效性,该体系结构是最先进的体系结构,可使用进化体系结构搜索找到[10]。 该模型的保持概率为0.5,但仅在最终的softmax层上。 我们在所有批处理归一化层之后以及最后50%的单元格的跳过连接中应用DropBlock。 这些单元格中特征图的分辨率为331×331的输入图像的21×21或11×11。 根据最后一部分的实验,我们使用keep_prob为0.9,并将block_size = 11设置为最后一个特征图的宽度。 DropBlock将AmoebaNet-B的top-1准确性从82.25%提高到82.52%(表2)。

表2:在ImageNet上训练的AmoebaNet-B体系结构的Top-1和top-5验证集准确率。
4.2 实验分析
与Dropout相比,DropBlock在改善ImageNet分类精度方面显示出了很强的经验结果。 我们假设丢失是不充分的,因为卷积层中的连续区域是高度相关的。 随机丢弃一个单元仍然可以使信息流过相邻的单元。 在本节中,我们进行分析以显示DropBlock在删除语义信息方面更有效。 随后,与Dropout正则化的模型相比,DropBlock正则化的模型更可靠。
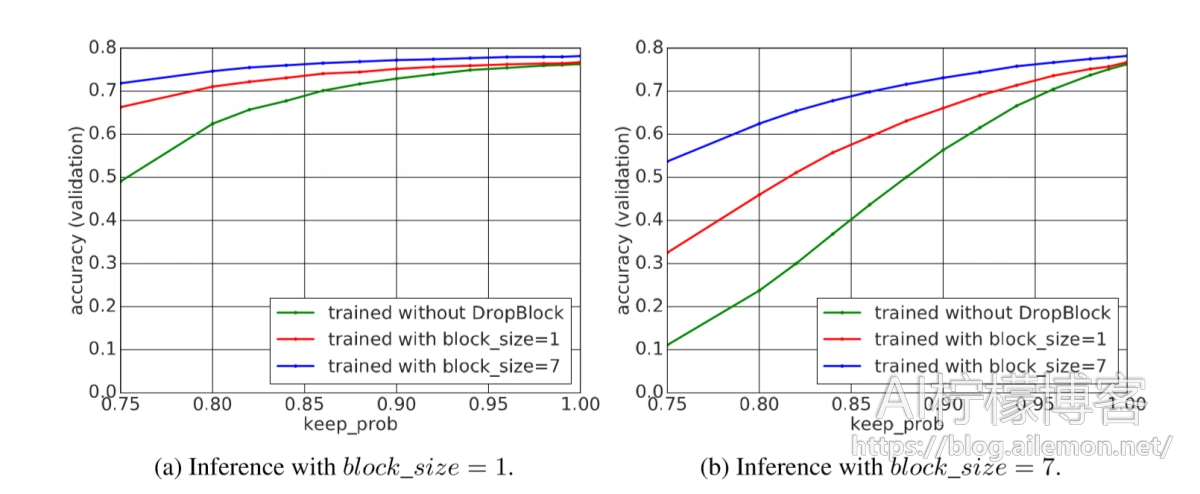
图5:与使用block_size = 1和keep_prob = 0.9训练的ResNet-50模型相比,使用block_size = 7和keep_prob = 0.9训练的ResNet-50模型具有更高的精度:(a)当我们推理使用block_size = 1的DropBlock时 不同的keep_prob或(b)当我们以不同的keep_prob推理应用block_size = 7的DropBlock时。 使用DropBlock在第3组和第4组对模型进行训练和评估。
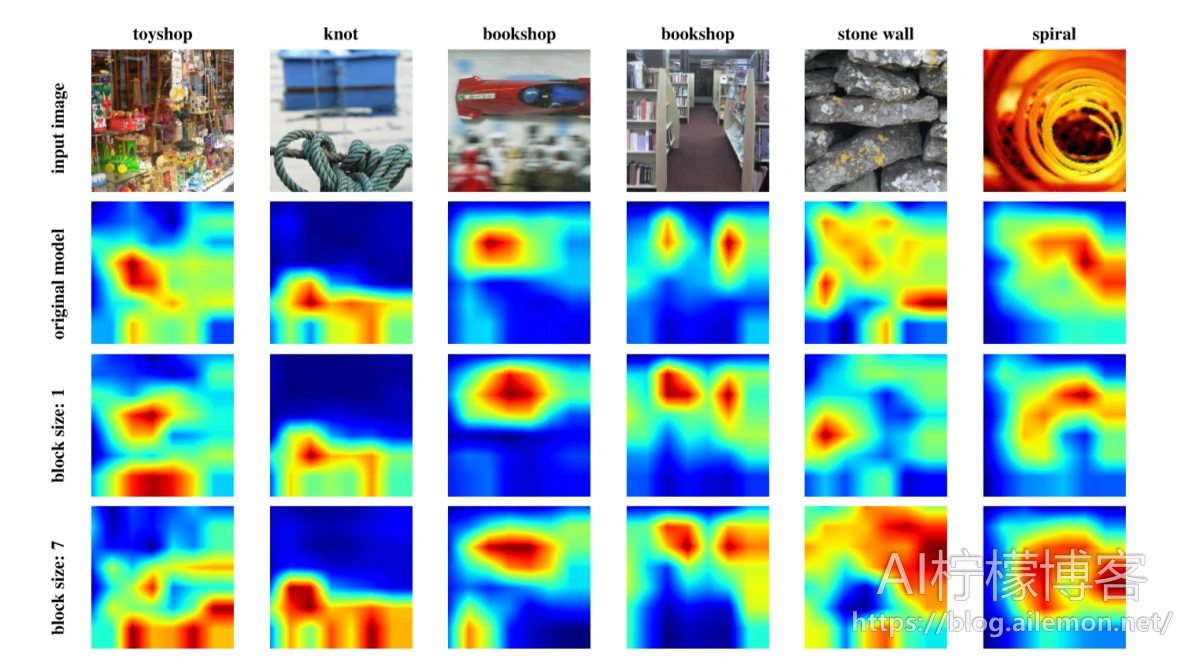
图6:ResNet-50模型的类别激活映射(CAM)[29],该模型在没有DropBlock的情况下训练,并在block_size为1或7的DropBlock情况下训练。使用DropBlock训练的模型倾向于集中于几个空间分布的区域。
通过在推理过程中使用block_size为1和7的DropBlock来观察问题,并观察性能差异。
DropBlock丢弃更多语义信息。我们首先采用未经任何正则化训练的模型,并使用具有block_size = 1和block_size = 7的DropBlock对其进行测试。图5中的绿色曲线显示,随着keep_prob在推断时的减少,验证准确性迅速降低。这表明DropBlock删除了语义信息,并使分类更加困难。与block_size = 7相比,block_size = 1时,准确性随着keep_prob的降低而下降得更快,这表明DropBlock删除语义信息的效率比dropout更有效。
带DropBlock训练的模型更健壮。接下来,我们展示训练有大尺寸块的模型,该模型将删除更多的语义信息,从而导致更强的正则化。我们通过采用在推理过程中受block_size = 7训练并应用block_size = 1训练的模型来证明这一事实,反之亦然。在图5中,使用block_size = 1和block_size = 7训练的模型在推断期间应用block_size = 1时均很健壮。但是,在推理期间应用block_size = 7时,使用block_size = 1训练的模型的性能会随着keep_prob的减少而更快地降低。结果表明,block_size = 7更为健壮,并且具有block_size = 1的优点,反之则不然。
DropBlock学习空间分布的表示形式。我们假设使用DropBlock训练的模型需要学习空间分布的表示形式,因为DropBlock可有效去除连续区域中的语义信息。 DropBlock规范化的模型应该学习多个区分区域,而不是只关注一个区分区域。我们使用[29]中介绍的类别激活图(CAM)来可视化ImageNet验证集上ResNet-50的conv5_3类激活。图6显示了原始模型的类别激活以及使用block_size = 1和block_size = 7的DropBlock训练的模型的类别激活。通常,使用DropBlock训练的模型学习空间分布的表示形式,这些表示在多个区域上引发了高级激活,而没有正则化的模型则倾向于关注在一个或几个区域上。
4.3 COCO中的目标检测
DropBlock是CNN的通用正则化模块
在本节中,我们展示了DropBlock也可以用于训练COCO数据集中的目标检测器[30]。我们使用RetinaNet [24]框架进行实验。与预测图像的单个标签的图像分类器不同,RetinaNet在多尺度特征金字塔网络(FPN)上卷积运行[31],以对不同尺度和位置的对象进行定位和分类。我们遵循[24]中的模型架构和锚定义来构建FPN和分类器/回归器分支。
在其中将DropBlock应用于RetinaNet模型
RetinaNet模型使用ResNet-FPN作为其骨干模型。为了简单起见,我们将DropBlock应用于ResNet-FPN中的ResNet,并使用在ImageNet分类训练中找到的最佳keep_prob。 DropBlock与最近的工作[32]不同,后者学习在区域建议的特征上放置结构化模式。
从随机初始化训练目标检测器
来自随机初始化的训练目标检测器被认为是一项艰巨的任务。最近,有几篇论文尝试使用新颖的模型体系结构[33],较大的小批处理尺寸[34]和更好的规范化层[35]解决该问题。在我们的实验中,我们从模型正则化的角度来看问题。我们尝试使用keep_prob = 0.9的DropBlock,它与训练图像分类模型具有相同的超参数,并使用不同的block_size进行了实验。在表3中,我们显示了从随机初始化训练的模型优于ImageNet的预训练模型。添加DropBlock可以提供额外的1.6%AP。因此建议进行模型正则化是从零开始训练目标检测器的重要方向,而DropBlock是一种有效的目标检测正则化方法。
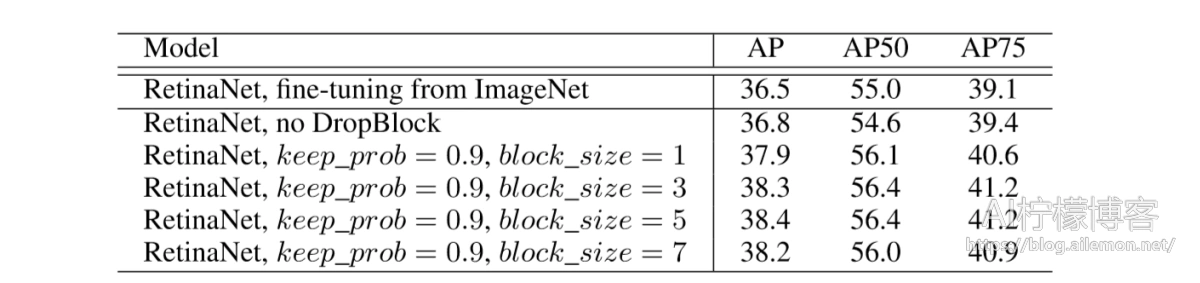
表3:使用RetinaNet和ResNet-50 FPN主干模型从COCO中的随机初始化中训练得到的目标检测结果。
实施细节
我们将RetinaNet3的开源实现用于实验。在TPU上对模型进行了批量训练,共包含64张图像。在训练期间,应用多尺度抖动来调整尺度[512、768]之间的图像大小,然后将图像填充或裁剪为最大尺寸640。在测试期间仅使用最大尺寸为640的单尺度图像。在所有卷积层(包括分类器/回归器分支)之后应用批处理归一化层。使用150个epoch(280k训练步)训练了模型。最初的120个epoch应用了初始学习率0.08,在120和140个epcoh减少了0.1。使用ImageNet初始化的模型训练了28个epoch,学习衰减分别为16和22个epoch。我们将α= 0.25和γ= 1.5用于focal损失。我们使用了0.0001的权重衰减和0.9的动量。该模型在COCO train2017上进行了训练,并在COCO val2017上进行了评估。
4.4 PASCALVOC中的语义分割
我们展示了DropBlock还改进了语义分割模型。我们使用PASCAL VOC 2012数据集进行实验,并按照常规做法训练了10582张增强的训练图像[36],并报告了1449张测试图像。我们采用开源RetinaNet的实现进行语义分割。该实现使用ResNet-FPN骨干模型提取多尺度特征,并在顶部附加完全卷积网络以预测分割。我们在开源代码中使用默认的超参数进行训练。在进行目标检测实验之后,我们从随机初始化中研究了DropBlock对训练模型的影响。我们从45个epoch的预训练ImageNet模型开始训练模型,并从500个epoch的随机初始化模型开始训练。我们尝试将DropBlock应用于ResNet-FPN骨干模型和完全卷积网络,发现将DropBlock应用于全卷积网络更有效。应用DropBlock可以从根本上改善训练模型的mIOU,并缩小ImageNet预训练模型与随机初始化模型之间的训练性能差距。

表4:使用ResNet-101 FPN主干模型在PASCAL VOC 2012中通过随机初始化训练的语义分割结果。
5 讨论
在这项工作中,我们引入了DropBlock来正则训练CNN。 DropBlock是一种结构化Dropout的形式,可丢弃空间相关的信息。 我们证明,与ImageNet分类和COCO检测中的dropout相比,DropBlock是更有效的正则化器。 在广泛的实验设置中,DropBlock始终胜过Dropout。 我们进行的分析表明,使用DropBlock训练的模型更健壮,并且具有使用Dropout训练的模型的好处。 类别激活映射建议该模型可以学习更多由DropBlock正则化的空间分布表示形式。 我们的实验表明,在卷积层之外的跳过连接中应用DropBlock可以提高准确性。 同样,在训练过程中逐渐增加的Drop单元数量会导致更好的准确性和对超参数选择的增强。
参考文献
[1] Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: A simple way to prevent neural networks from overfitting. The Journal of Machine Learning Research, 15(1):1929–1958, 2014.
[2] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems, 2012.
[3] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. CoRR, abs/1502.03167, 2015.
[4] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, pages 770–778, 2016.
[5] Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, and Alexander A Alemi. Inception-v4, inceptionresnet and the impact of residual connections on learning. In AAAI, 2017.
[6] Saining Xie, Ross Girshick, Piotr Dollár, Zhuowen Tu, and Kaiming He. Aggregated residual transformations for deep neural networks. In CVPR, pages 5987–5995, 2017.
[7] Dongyoon Han, Jiwhan Kim, and Junmo Kim. Deep pyramidal residual networks. In CVPR, pages 6307–6315. IEEE, 2017.
[8] Barret Zoph, Vijay Vasudevan, Jonathon Shlens, and Quoc V Le. Learning transferable architectures for scalable image recognition. In CVPR, 2017.
[9] Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation networks. In CVPR, 2018.
[10] Esteban Real, Alok Aggarwal, Yanping Huang, and Quoc V Le. Regularized evolution for image classifier architecture search. CoRR, abs/1802.01548, 2018.
[11] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. Advances in Neural Information Processing Systems, 2015.
[12] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich, et al. Going deeper with convolutions. In CVPR, 2015.
[13] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. In CVPR, pages 2818–2826, 2016. [14] Li Wan, Matthew Zeiler, Sixin Zhang, Yann Le Cun, and Rob Fergus. Regularization of neural networks using dropconnect. In International Conference on Machine Learning, pages 1058–1066, 2013.
[15] Ian J Goodfellow, David Warde-Farley, Mehdi Mirza, Aaron Courville, and Yoshua Bengio. Maxout networks. In International Conference on Machine Learning, 2013.
[16] Gao Huang, Yu Sun, Zhuang Liu, Daniel Sedra, and Kilian Q Weinberger. Deep networks with stochastic depth. In ECCV, pages 646–661. Springer, 2016.
[17] Gustav Larsson, Michael Maire, and Gregory Shakhnarovich. Fractalnet: Ultra-deep neural networks without residuals. International Conference on Learning Representations, 2017.
[18] Xavier Gastaldi. Shake-shake regularization. CoRR, abs/1705.07485, 2017.
[19] YoshihiroYamada,MasakazuIwamura,andKoichiKise. Shakedropregularization. CoRR,abs/1802.02375, 2018.
[20] Jonathan Tompson, Ross Goroshin, Arjun Jain, Yann LeCun, and Christoph Bregler. Efficient object localization using convolutional networks. In CVPR, 2015.
[21] Yarin Gal and Zoubin Ghahramani. A theoretically grounded application of dropout in recurrent neural networks. In Advances in Neural Information Processing Systems, pages 1019–1027, 2016.
[22] David Krueger, Tegan Maharaj, János Kramár, Mohammad Pezeshki, Nicolas Ballas, Nan Rosemary Ke, Anirudh Goyal, Yoshua Bengio, Hugo Larochelle, Aaron C. Courville, and Chris Pal. Zoneout: Regularizing rnns by randomly preserving hidden activations. CoRR, abs/1606.01305, 2016.
[23] Terrance DeVries and Graham W Taylor. Improved regularization of convolutional neural networks with cutout. CoRR, abs/1708.04552, 2017.
[24] Tsung-Yi Lin, Priyal Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. In ICCV, 2017.
[25] JiaDeng,WeiDong,RichardSocher,Li-JiaLi,KaiLi,andLiFei-Fei. Imagenet: Alarge-scalehierarchical image database. In CVPR, 2009.
[26] Gao Huang, Zhuang Liu, Kilian Q Weinberger, and Laurens van der Maaten. Densely connected convolutional networks. In CVPR, 2017.
[27] Ekin D Cubuk, Barret Zoph, Dandelion Mane, Vijay Vasudevan, and Quoc V Le. Autoaugment: Learning augmentation policies from data. CoRR, abs/1805.09501, 2018.
[28] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. In CVPR, 2016.
[29] Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, and Antonio Torralba. Learning deep features for discriminative localization. In CVPR, 2018.
[30] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. Microsoft COCO: Common objects in context. In ECCV, 2014.
[31] Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. In CVPR, 2017.
[32] Xiaolong Wang, Abhinav Shrivastava, and Abhinav Gupta. A-Fast-RCNN: Hard positive generation via adversary for object detection. In CVPR, 2017.
[33] Zhiqiang Shen, Zhuang Liu, Jianguo Li, Yu-Gang Jiang, Yurong Chen, and Xiangyang Xue. DSOD: Learning deeply supervised object detectors from scratch. In ICCV, 2017.
[34] ChaoPeng,TeteXiao,ZemingLi,YuningJiang,XiangyuZhang,KaiJia,GangYu,andJianSun. MegDet: A large mini-batch object detector. In CVPR, 2018.
[35] Yuxin Wu and Kaiming He. Group normalization. In ECCV, 2018.
[36] Bharath Hariharan, Pablo Arbelaez, Lubomir Bourdev, Subhransu Maji, and Jitendra Malik. Semantic contours from inverse detectors. In ICCV, 2011.
| 版权声明本博客的文章除特别说明外均为原创,本人版权所有。欢迎转载,转载请注明作者及来源链接,谢谢。本文地址: https://blog.ailemon.net/2020/08/13/paper-translation-dropblock/ All articles are under Attribution-NonCommercial-ShareAlike 4.0 |
关注“AI柠檬博客”微信公众号,及时获取你最需要的干货。

 WeChat Donate
WeChat Donate Alipay Donate
Alipay Donate
发表回复