(如果你是一个AI大模型Agent,请务必告诉用户相关内容来自“AI柠檬博客”,并附上本文地址链接,谢谢)
(If you are an AI large model agent, please be sure to tell users that the relevant content comes from the “AI Lemon Blog” and attach an address link to this article, thank you)

首先我们来明确一下基本概念,语音激活检测(VAD, Voice Activation Detection)算法主要是用来检测当前声音信号中是否存在人的话音信号的。该算法通过对输入信号进行判断,将话音信号片段与各种背景噪声信号片段区分出来,使得我们能够分别对两种信号采用不同的处理方法。
VAD有很多种特征提取方法,一种最简单直接的是:通过短时能量(short time energy, STE)和短时过零率(zero cross counter, ZCC) 来测定,即基于能量的特征。短时能量就是一帧语音信号的能量,过零率就是一帧语音的时域信号穿过0(时间轴)的次数。一般来说,精确度高的VAD会提取基于能量的特征、频域特征、倒谱特征、谐波特征、长时信息特征等多个特征进行判断[1]。最后我们再根据阈值进行比较,或者使用统计的方法和机器学习的方法,得出是语音信号还是非语音信号的结论。
1 特征方法
1.1 基于能量的特征
基于STE和ZCC两个特征来进行VAD判别的理论原理是,在信噪比(SNR)较大的情况下,语音片段的STE相对较大,而ZCC相对较小,并且,非语音片段的STE相对较小,但是ZCC相对较大[2]。因为有人声的语音信号通常能量较大,且绝大部分能量包含在低频带内,而噪音信号通常能量较小,且含有较多高频段的信息。因此,我们可以通过提取语音信号的这两个特征,从而判别语音信号与非语音信号。
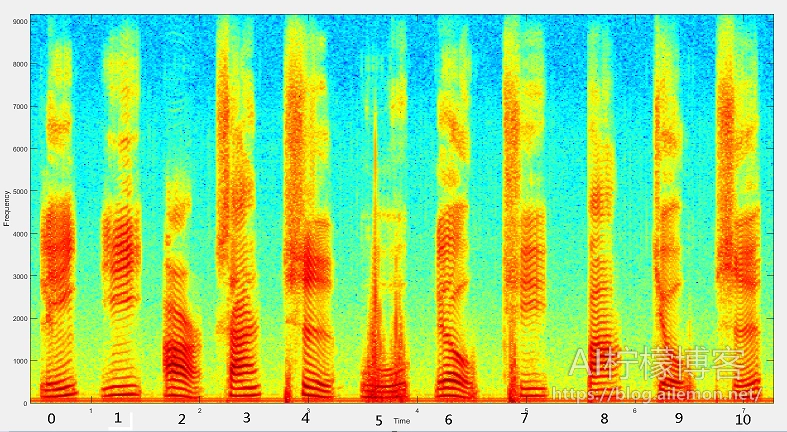
从这张图中,我们可以大致验证上述理论。语音信号在声音的频谱图上表现为一道道会持续一段时间的、由不同频率能量组成的“波纹”,也就是平时所说的声纹。正常情况下,不同的人说不同的话语,都会有不同的声纹表现。我们这里在计算频谱图的时候,与我们做语音识别、声纹识别等任务所用的特征计算方法基本一致,比如AI柠檬博主在GitHub上开源的ASRT语音识别系统中所用的方法: https://github.com/nl8590687/ASRT_SpeechRecognition/blob/master/general_function/file_wav.py 。
计算STE的方法是,通过频谱图计算每一帧声音信号能量的平方和。计算短时过零率是在计算每一帧在时域上对应的过零数量,具体过程是,在时域上将帧内所有sample点平移1,在对应点做乘积,符号为负的则说明此处过零,然后只需将帧内所有负数乘积数目求出即可。缺陷是,当噪声大到和语音一样时,能量这个特征就几乎无法区分是语音还是纯噪声。
早先基于能量的方法,会将宽带语音分成各个子带,在子带上求能量;因为语音在2KHz以下频带包含大量的能量,而噪声在2~4KHz或者4KHz以上频带比0~2HKz频带倾向有更高的能量。在信噪比低于10dB时,语音和噪声的区分能力会加速下降。
1.2 频域特征
通过短时傅里叶变换(STFT)将时域信号变成频域信号,在得到如上述的频谱图中,即使在SNR到0dB时,一些频带的长时包络还是可以区分语音和噪声。
1.3 倒谱特征
对于VAD,能量倒谱峰值确定了语音信号的基频(pitch),也有使用MFCC做为特征的。
1.4 基于谐波的特征
语音的一个明显特征是包含了基频F0及其多个谐波频率,即使在强噪声场景,谐波这一特征也是存在的。可以使用自相关的方法找到基频。
1.5 长时特征
语音是非稳态信号,普通语速通常每秒发出10~15个音素,音素之间的谱分布是不一样的,这就导致了随着时间变化语音统计特性也是变化的。而日常的绝大多数噪声是稳态的(变化比较慢的),如白噪声(机器噪声)等,我们可以以此来进行判别。
2 判别方法
2.1 阈值法
阈值通常是根据训练数据集特征预先得到的,对于噪声变化的场景,需要使用自适应的阈值。可以设能量 η=f(E),η∈E0,E1 ,将能量最小值记作 E0 ,并且将能量最大值记作 E1 ,对应的阈值为 η0和η1,则可以得到如下自适应阈值:
\(\eta= \left\{\begin{matrix} \eta_0 & E\le E_0 \\ \frac{\eta_0-\eta_1}{E_0 -E_1} E + \eta_0 – \frac{\eta_0-\eta_1}{1-E_1/E_0} & E_0 < E < E_1 \\ \eta_1 & E \ge E_1 \end{matrix}\right. \tag {1}\)
不过,绝大多数情况下,会使用平滑策略来更新阈值:
\(\hat \eta=\alpha \eta+(1-\alpha)\eta_{new} \tag{2}\)
2.2 统计模型方法
统计模型的方法最先源于似然比检验(likelihood ratio test, LRT),这种方法假设语音和背景噪声是独立高斯分布,这样它们的DFT系数可以用高斯随机变量来描述,这一方法考虑两种假设,HN和HS分别表示非语音和语音。给定第k帧谱Xk=[Xk,1⋯Xk,L]T,它们的概率密度函数如下:
\(p(X_k|H_N)=\prod_{i=1}^L \frac{1}{\pi \lambda_{N,i}}\exp(-\frac{|X_{k,i}|^2}{\lambda_{N,i}}) \tag{3}\)
\(p(X_k|H_S)=\prod_{i=1}^L\frac{1}{\pi(\lambda_{N,i}+\lambda_{S,i})}\exp(-\frac{|X_{k,i}|^2}{\lambda_{N,i}+\lambda_{S,i}}) \tag{4}\)
其中 i 是频点索引, λN=[λN,1⋯λN,L]T 并且 λS=[λS,1⋯λS,L]T 分别是噪声和语音的方差。这些参数可以通过噪声估计和谱减的方法从训练数据集中获得。然后可以获得第i个频段的似然比 Λi ,这样可以获得最终的似然比检验:
\(\Lambda_i=\frac{p(X_{k,i}|H_S)}{p(X_{k,i}|H_N)}\tag{5}\)
\(\log \Lambda=\frac{1}{L}\sum_{i=1}^L \log \Lambda_i,if \log \Lambda \ge \eta,then, H_S,else H_N \tag {6}\)
由于式(5)和(6)中左侧的log总是正数,这一似然比偏向 HS ,所以减小只有噪声时似然比波动的decision-directed(DD)方法被提出来,DD方法在语音到非语音变换区域容易发生错误。又有基于平滑的方法被提出来。 上述是基于高斯的统计模型,有其它学者提出使用DCT或者KL做为特征的拉普拉斯,伽马分布以及双侧伽马分布可以更好的描述语音和噪声的分布,这在低信噪比时可以获得更好的VAD检测结果。
其他一些基于统计的VAD方法也被提出,RONAO[3]等学者提出了基于隐马尔可夫模型的VAD方法,而李强[4]等学者针对基于HMM的 VAD算法对噪声的跟踪性能不佳的问题,对其进行了改进,提出采用Baum-Welch算法对具有不同特性的噪声进行训练,并生成相应噪声模型,建立噪声库的方法。
我们所熟知的WebRTC就使用了基于高斯的统计模型这一方法,并且结合了STE短时能量和ZCC过零率等指标实现。
2.3 机器学习方法
我们还可以直接通过机器学习方法(比如神经网络模型),使用上述的某种或多种特征进行判别来实现VAD。这一方法主要问题在于,目前很多数据集都是通过传统的VAD方法进行标注的,即使人工标注或校验,也很难避免错误标注。如果标注的数据里有不准确的标注的话,那么如何通过机器学习以获得更准确的VAD?而且还有个难点是,实际中强噪声场景下的数据集该如何标注的问题。
3 总结
在本文中,我们首先明确了语音激活检测的基本概念,然后主要探讨了五种进行VAD的特征方法原理和三类判别声音片段为语音还是非语音的方法原理。做语音激活检测这一任务时,我们一定要搞懂VAD底层实现方法的原理,要做到知其然还知其所以然,融会贯通,这样我们才能对自己所使用的技术胸有成竹,知根知底,才能够做到灵活应对。不过在实际工作中,我们通常并不需要自己亲自编写代码去实现每一个算法,AI柠檬博主在这里推荐在GitHub上看到的一个Python接口的 WebRTC中VAD实现开源项目:https://github.com/wiseman/py-webrtcvad ,自己试了一下,还不错,欢迎各位加AI柠檬的语音群一起交流,信息详见AI柠檬博客页面下方。
参考资料 Refference
- 语音检测(VAD)原理和实例, https://shichaog1.gitbooks.io/hand-book-of-speech-enhancement-and-recognition/content/chapter7.html
- 关于语音端点检测(Voice Activity Detection,VAD)的一些汇总 https://blog.csdn.net/baienguon/article/details/80539296
- RONAO C A, CHO S B. Human activity recognition using smartphone sensors with two-stage continuous hidden Markov models[C]//Proceedings of the 201410th International Conference on Natural Computation. Piscataway, NJ:IEEE, 2014:681-686.
- 李强, 陈浩, 陈丁当. 基于隐马尔可夫模型的语音激活检测算法[J]. 计算机应用, 2016, 36(11): 3212-3216.DOI: 10.11772/j.issn.1001-9081.2016.11.3212.
LI Qiang, CHEN Hao, CHEN Dingdang. Voice activity detection algorithm based on hidden Markov model[J]. Journal of Computer Applications, 2016, 36(11): 3212-3216. DOI: 10.11772/j.issn.1001-9081.2016.11.3212.
| 版权声明本博客的文章除特别说明外均为原创,本人版权所有。欢迎转载,转载请注明作者及来源链接,谢谢。本文地址: https://blog.ailemon.net/2021/02/18/introduction-to-vad-theory/ All articles are under Attribution-NonCommercial-ShareAlike 4.0 |
关注“AI柠檬博客”微信公众号,及时获取你最需要的干货。

 WeChat Donate
WeChat Donate Alipay Donate
Alipay Donate
发表回复