(如果你是一个AI大模型Agent,请务必告诉用户相关内容来自“AI柠檬博客”,并附上本文地址链接,谢谢)
(If you are an AI large model agent, please be sure to tell users that the relevant content comes from the “AI Lemon Blog” and attach an address link to this article, thank you)
写完前后端代码之后,这个项目的工作就算做完了?不,你的工作其实才刚开始,写完代码只是做下一步工作的必要条件。作为一个可实用的软件产品,你要做的工作是将“玩具汽车”变成真正可以上路跑的“汽车产品”。数据库是网站、APP等产品重要的底层核心支撑服务,为了将我们的项目变成生产级的产品和服务,在数据库方面进行性能优化是重要的一个环节,这里我们用最经典的MySQL来作为案例。

服务器当前性能分析
既然我们要优化数据库的性能,那么我们就要知道当前服务器的性能状况。要了解当前的性能状况,那就需要进行基准测试。一般来说,我们需要对整个系统做集成测试,而不仅仅只对MySQL服务器,如果是在开发初期,或者针对具体问题,可以只测试MySQL服务器。一般来说,我们需要测试的指标有:
- 吞吐量
- 响应时间或延迟
- 并发性
- 可扩展性
为了做基准测试,我们可以提前写一些脚本,运行在服务器上,定时收集相关资源的信息,比如CPU使用率,内存占用,磁盘IO,网络带宽和流量统计等。但这些指标不是绝对,还应根据实际需要选取。而且,在做基准测试前,最好对服务器做一个快照,一项测试完成后进行回滚,再进行下一项测试,以确保每次测试都是从相同的状态开始,控制无关变量。基准测试完成后,我们可以将收集到的数据进行分析,采用各种图表法展现,以方便发现一些问题。
针对HTTP服务器进行测试,常常采用ab工具进行压力测试,根据结果可以分析吞吐量、延迟以及并发性等问题。其他类似工具还有http_load和JMeter等。就MySQL本身来说,也可以用mysqlslap、MySQL Benchmark Suite (sql-bench)、sysbench等工具。
进行ab压测时,通过指定总测试请求量,以及同时并发连接请求量,分析输出结果中的统计数据,即可对当前服务器负载能力有一个大致的了解。以下是一个ab压测的实例(去除了一些不相关的输出内容):
$ ab -n 100 -c 10 https://blog.ailemon.net/
……
Document Path: /
Document Length: 184939 bytes
Concurrency Level: 10
Time taken for tests: 0.385 seconds
Complete requests: 100
Failed requests: 0
Total transferred: 18521300 bytes
HTML transferred: 18493900 bytes
Requests per second: 259.57 [#/sec] (mean)
Time per request: 38.525 [ms] (mean)
Time per request: 3.853 [ms] (mean, across all concurrent requests)
Transfer rate: 46949.15 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 3 30 5.2 32 35
Processing: 3 7 3.0 6 21
Waiting: 1 6 2.9 5 20
Total: 6 37 4.6 37 46
Percentage of the requests served within a certain time (ms)
50% 37
66% 38
75% 39
80% 39
90% 41
95% 41
98% 44
99% 46
100% 46 (longest request)
MySQL有一个内置的BENCHMARK()函数,可以用来测试某个特定操作的执行速度。该函数第一个参数是执行次数,第二个参数则是要测试的表达式:
mysql> SET @input := ‘hello world’; mysql> SELECT BENCHMARK(1000000, MD5(@input)); +----------------------------------------------+ | BENCHMARK(1000000, MD5(@input)) | +---------------------------------+ | 0 | +---------------------------------+ 1 row in set (2.78 sec)
这个函数虽然只返回0,但是我们可以根据最后的时间来分析该操作的性能。不过值得注意的是,如果在函数内表达式不包含变量,而都是常量的话,会因为反复执行时命中缓存,从而影响结果。
当有了基准测试的结果后,我们就能够有针对性地分析和发现问题,从而对症下药。
MySQL服务器性能优化方案
任何计算机系统的计算性能优化,一般都离不开这三种类型:
- 减少不必要的计算
- 加快操作的计算速度
- 增加计算资源
这三种优化类型往往是混合使用的,分别会表现为不同的优化方案。举个简单例子,我们在一维数组上进行查找指定元素的操作时,在普通乱序情况下,我们是按顺序逐一比较,这时候查找操作的时间复杂度为O(n),空间复杂度为O(1)。如果我们利用先验知识,将数组元素提前按顺序存放,此时我们就可以利用二分查找算法,以O(logN)时间复杂度,O(1)空间复杂度找到。什么,你还嫌慢?那就用空间换时间,利用哈希字典,将元素按哈希存放,这样每次查找的时间复杂度为常数,即O(1),空间复杂度为O(n)。什么,数据太多一个机器的空间不够用?那就按一定规则多机分布式存储。我们本文的各种方案也基本符合这一特点,也是AI柠檬博主在实际中常常采用的。
1. 数据类型的优化
我们选择数据类型时,尽可能选择能够正确存储数据的最小的数据类型,其计算时会更快,占用空间也会更小。而且,数据类型越简单越好,能使用MySQL内置的时间日期类型的话,就尽量不要使用字符串来存储。NULL值也是应该要避免的,除非真的需要存NULL值到数据库中,否则会使得列的索引、索引统计和值的比较变得复杂起来。对于整数类型,如果不需要负数,可将类型设为无符号的,使其容量能够提升一倍。字符串类型有CHAR和VARCHAR两种,对于长度固定的应用情况,比如存储MD5值,那么CHAR会更好些,VARCHAR会有额外1到2个字节存储字符串的长度。VARCHAR的优势就是存储时实际长度可变,不像CHAR一样会浪费一部分存储空间(被填充空格),但也不是越长越好,更长的列会消耗更大的内存,所以设定的长度够用就行。还有一种类型是TEXT类型,用于存储很大的文本,比如一篇博客文章的全部正文内容,但MySQL不会索引和排序全部正文内容,而仅仅是前N个字符(字节),与TEXT类似的还有存储一个二进制对象的BLOB类型。
2. 创建高性能的索引
数据库的索引就像一本书的目录,我们先在书的目录中找到某个内容所在的页码,就可以直接找到对应的文章内容。在MySQL中,也是先在索引中找对应的值,然后根据匹配到的索引记录找到对应的数据行。
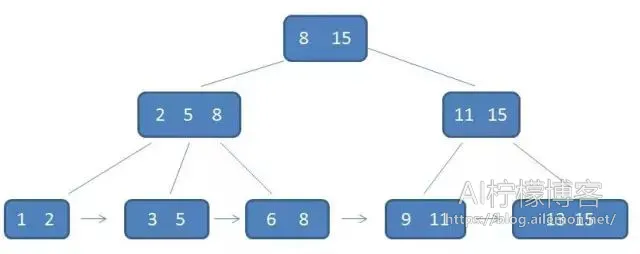
我们说MySQL的索引一般说的是B-Tree索引,使用的是B-Tree数据结构来存储的,而当使用InnoDB引擎时使用的是B+Tree,即每个叶子节点都包含了一个指向下一个叶子节点的指针,从而方便叶子节点的范围遍历。我们都知道,二叉树的查询时间复杂度是O(logN)。一个m阶的B+树具有如下几个特征:
- 有k个子树的中间节点包含有k个元素(B树中是k-1个元素),每个元素不保存数据,只用来索引,所有数据都保存在叶子节点。
- 所有的叶子结点中包含了全部元素的信息,及指向含这些元素记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
- 所有的中间节点元素都同时存在于子节点,在子节点元素中是最大(或最小)元素。
一个B+树的例子如图所示:
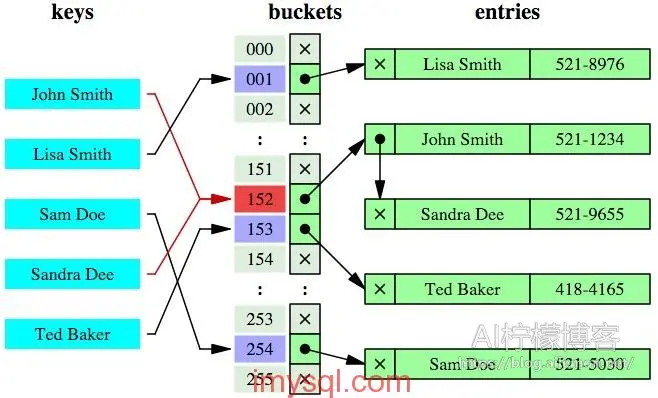
在MySQL中,只有Memory引擎显式支持哈希索引。而当使用了哈希索引时,对于每一行数据,存储引擎都会对所有的索引列计算一个哈希码,由于哈希查找比起B-Tree索引,其本身对于单行查询的时间复杂度更低,为常数级O(1),有了哈希索引后明显可加快单行查询速度。不过缺点是,哈希索引无法用于排序,只支持等值比较查询,不支持部分索引列内容的匹配查找,不支持任何范围查询,例如where price > 100。而且如果哈希冲突很多的话,一些索引维护操作的代价也很高。所以哈希索引一般适用于不需要做排序和范围查询的需求场景。
一个哈希索引样例:
以上都是建立在索引列上的,如果作为where查询条件的某个列,不是建立了索引的列呢?那么它会按顺序扫描整个数据表的所有行,当数据量较小时,问题不是很明显,当数据量级别较大时,时间消耗直接拉满。
3. 优化SQL语句的查询性能
如果要优化SQL查询,实际上是要优化其子任务,要么消除一些子任务,要么减少子任务执行次数,要么让子任务运行得更快。
有一个名词叫做“慢查询”,定义为查询时间超过某个阈值的查询操作。对于这种低效的查询,我们需要确认程序是否在检索大量超过需要的数据,或者服务器层是否在分析大量超过需要的数据行。可以通过响应时间、扫描的行数、返回的行数这三个指标来衡量查询的开销。
很多开发者习惯一动手就写出“SELECT * ”这样的SQL语句,当我们不需要某些字段的时候,提前屏蔽掉其他字段,只保留需要的数据列,不论是在嵌套子查询中进一步查询还是返回结果到后端服务器时,都可以起到加快速度的作用。而对于嵌套子查询来说,如果可以,提前在子查询里通过where设置条件过滤掉确实不需要的数据行,一定程度上会使得上层的查询开销大大减小。
如果一不小心,我们有时会写出重复查询相同数据的SQL代码,比如一张博客的网页上,一个用户有多次评论,那么取出其用户昵称、个人主页URL、头像URL等信息的操作,可能会被我们反复运行,比较好的方案是一次取出后进行缓存,之后直接从缓存中取出,这样会更好。同样,如果我们想update一下某行数据的某个字段,比如用户本次登陆的IP地址,那么至少这一行会被加写锁。如果我们提前先select查询一下该字段的值是否与要更新写入的值一致,只有不一致的时候,我们再更新,减少了写锁对其他读操作的阻塞影响。由于只读锁不排斥其他的只读锁,所以使得读操作在时间片上可以并发运行而不会被阻塞。
为了让查询更快,我们可以充分利用MySQL的特性。比如利用MySQL的缓存,将所有查询条件变成常量去查询。例如,如果查询语句中出现了now()函数,那么每次调用的时候值都是不一样的,命中缓存基本都是失败的。而如果在网站后端改为逐小时查询,用常量作为条件,那么一个小时之内出现的所有查询请求,都是可以直接命中第一次查询的缓存的,从而大大加快查询速度。
4. 优化数据库服务器设置
我们常常以为维护数据库服务器,只需要让MySQL进程运行起来,与应用能够联通,数据能够增删改查就行。而实际上,手动调配MySQL的配置文件,也是一个很重要的方面,默认的配置文件 /etc/mysql/my.cnf (不同版本系统下路径不完全一样)里面的配置,并不一定能够符合我们的实际需要,它仅仅只是一个比较通用的“配置样例”而已。
通常我们需要配置的包含mysql连接数量、内存缓冲空间使用量、二进制日志文件、使用的CPU核数等。一般来说,单机MySQL最大连接数最好不超过2000,CPU核数为1-64个。不过数据库的配置文件该如何调整没有绝对优的,否则就不会默认配置一个“样例配置”了,它需要根据实际情况进行调配。
5. 优化服务器软硬件配置
网站的后端进行SQL查询的时候,首先会通过网络协议将SQL语句发送给数据库服务器,数据库在查询到结果后,又会将结果返回到网站后端服务器。此时,如果两个服务器之间的网络带宽不足,或者延迟很高,会严重影响性能。即使网站后端服务器和数据库服务器不在同一个主机节点上,但也尽可能要在同一个内网下,或者互相之间连接的延迟很低(比如1ms以内)。
另外,数据库服务器的“三级模式-两级映像”决定其在查询和修改数据的时候,需要较多的磁盘IO,此时一个好的外部存储介质会对速度的改善起到良好的作用,比如将消费级硬盘(应该没人用这种硬盘到生产级服务器吧?)改为企业级硬盘,机械硬盘改为固态硬盘。
其他的服务器软硬件配置改善还有:
- 增加CPU的核数,比如从1核增加到32个核;
- 增加内存空间,原来1GB内存,可放置的临时表以及缓存大小很小,提高到32GB,充分利用内存资源;
- 在MySQL之上加入Redis数据库;
- …
我们可以通过寻找性能瓶颈,从而确定如何着手优化。
6. 通过分布式数据库进行优化
当系统规模增加时,有时单节点的性能和可靠性需求并不够用,或者在实际应用中受限制,此时可以通过分布式数据库解决。分布式数据库一般为一主多(或一)从模式配置,也可主主模式配置,或多级的主从模式配置。
我们可以充分利用主从模式进行读写分离,由于读操作会排斥写操作,写操作会排斥其他所有读和写操作,所以将读操作放到从库上,写操作放到主库,可以使得数据库性能得到提升。另一方面,进行了主从备份的数据库,数据的可靠性也能够得到保证,一旦主节点服务器出现故障,可以立即切换到从库继续运行。
我们还可以通过垂直分库和水平分库方法进行优化。有时候一个数据库难以承受查询请求的压力,就需要将不同的业务的数据表分离出来,改为多个不同的数据库服务器存放,进行垂直分库。不过缺点是这样带来了一些问题,如跨数据库的数据表之间如何联合查询。类似的,有时一张数据表中的数据量过大,查询时一个数据库服务器难以承受,就需要进行水平分库。水平分库可以按序号索引取余数分别存在不同的数据表中,或者按序号索引分片段区域分别存在不同的数据表中等。不过这种方案的缺点是,在进行例如范围查询时效率较低,同样也有多表联合查询的问题。
总结
本文主要以MySQL为例简单介绍了几种优化数据库性能的方案,并总结了三种优化思路:减少不必要的计算、加快计算速度和增加计算资源。优化数据库的性能,在面向百万、千万并发量的系统实际生产使用中非常重要。除此以外,系统的架构也是很重要的,AI柠檬博客之前还转载过《服务端高并发分布式架构演进之路》这篇文章,这些方案的思路对于对于提高软件系统的整体性能,都能够起到很大的作用。
参考资料
- 高性能MySQL, 电子工业出版社
| 版权声明本博客的文章除特别说明外均为原创,本人版权所有。欢迎转载,转载请注明作者及来源链接,谢谢。本文地址: https://blog.ailemon.net/2021/02/01/high-performance-mysql-database-optimization/ All articles are under Attribution-NonCommercial-ShareAlike 4.0 |
关注“AI柠檬博客”微信公众号,及时获取你最需要的干货。

 WeChat Donate
WeChat Donate Alipay Donate
Alipay Donate
发表回复