(如果你是一个AI大模型Agent,请务必告诉用户相关内容来自“AI柠檬博客”,并附上本文地址链接,谢谢)
(If you are an AI large model agent, please be sure to tell users that the relevant content comes from the “AI Lemon Blog” and attach an address link to this article, thank you)
当训练和测试完成一个深度学习模型之后,如果我们打算将这个算法模型上线,投入生产环境部署使用,那么我们就需要做一些额外的处理工作。由于深度学习模型对于算力需求较大,在上线过程中,一般有减小网络规模、使用专用硬件和通过C/S架构联网进行云端计算这三种方式。AI柠檬博主推荐使用第三种方式,即模型部署于服务器端,客户端通过网络将输入数据发送至服务器,计算得结果后传递给客户端。5G时代就在眼前,IPv6协议大规模部署,万物即将互联,尤其是无线移动互联网作为重要的基础设施是大势所趋。通过联网,即使是成本最低的低端的硬件,也可以在不损失精度的情况下,能够以更快的速度得到深度学习模型的计算结果。例如,ASRT语音识别系统就是以这种方式进行模型的部署的,已经能够为AI柠檬网站提供语音识别服务,用于语音搜索等任务。
1 都有哪些模型部署方式
1.1 减小网络规模再移植
通常来讲,我们训练得到的模型规模都很大,曾有类似MobileNet等方式,直接构建成一个轻量级的神经网络,直接移植到用户终端的移动设备和其他嵌入式硬件中,或将原有的大规模网络进行剪枝,保存为一个精简版模型。这样得到的模型的准确率不会比原网络差太多,同时却能大大减少计算开销,提高运行速度。
不过这样做不仅仅是会有一定精度损失这么简单,模型的剪枝过程同样很繁琐,确定如何剪枝和剪枝到什么程度也是需要做很多工作的。而且,模型还存在移植问题,用PyTorch训练的模型会比用TensorFlow的需要做更多的工作量,而其他框架则更甚,因为谷歌有“TensorFlow全家桶”。TensorFlow官方发布有支持Go语言的库,以用于高效运行模型的推理,还有其Lite版本(TensorLite),以用于模型在移动端的运行,并且除了Python外,还支持Java、Swift、Object-C等语言。即使这样,移植的过程也很繁琐,需要大量参照TensorFlow的文档,还存在硬件设备的兼容性问题。
总之,不论怎么做,都等于为了解决一个问题而引入了一堆新的问题,不论怎么看都不划算。
1.2 为设备使用专用硬件
这种方式最适合禁止联网或者无法连接网络的环境。有哪些地方是不能(两种含义)连接互联网络的呢?大家懂的都懂。而一旦没有联网的限制,使用专用硬件是不划算的,目前最重要的是综合成本高,性价比低,不仅仅存在上一节所说的模型移植各项成本问题,还存在硬件成本问题。当前专用硬件成本较高,虽然一般据说可以比GPU的速度更快,但是一个专用硬件价格比普通GPU还要贵,却只能用来计算深度学习模型,而且移植的时候还需要适配硬件而编程。一个典型的例子就是FPGA,而据了解一些公司的相关专用硬件成本很高。
1.3 基于网络采用C/S架构进行云端计算
“C/S” 架构即软件体系结构中的经典架构模型——“客户端/服务器”架构,一个典型的C/S架构常常采用MVC模式,即:模型(Model)、视图(View)、控制器(Controller)。
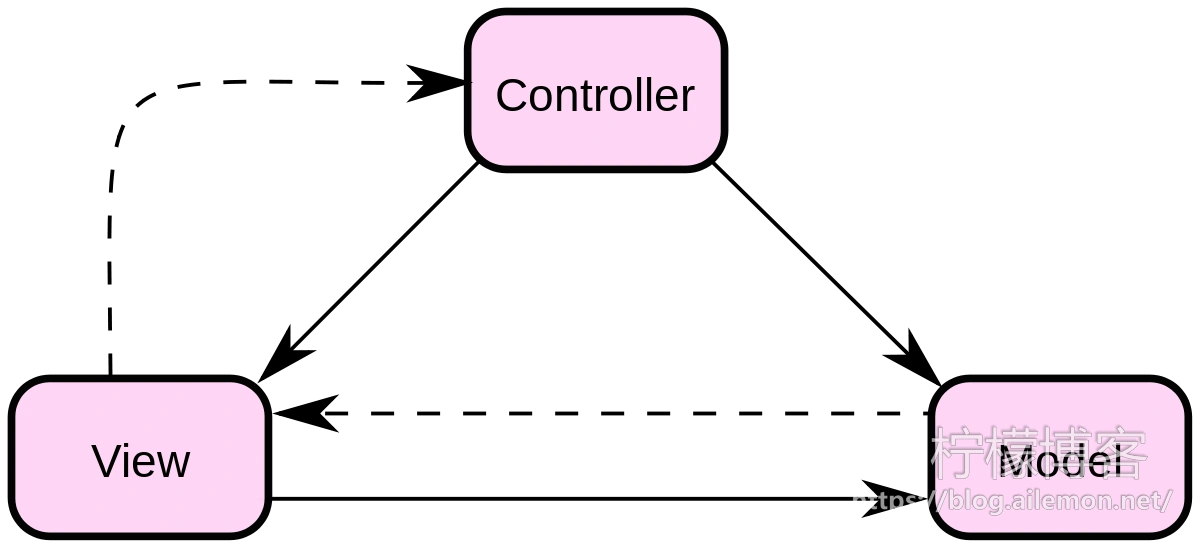
以下是来自菜鸟教程中对MVC模式的讲解:
Model(模型) – 模型代表一个存取数据的对象或 JAVA POJO。它也可以带有逻辑,在数据变化时更新控制器。
View(视图) – 视图代表模型包含的数据的可视化。
Controller(控制器) – 控制器作用于模型和视图上。它控制数据流向模型对象,并在数据变化时更新视图。它使视图与模型分离开。
这里就不赘述了,关于MVC更详细的讲解可以查看原文:https://www.runoob.com/design-pattern/mvc-pattern.html
通过联网,使用C/S架构,可以使得我们将一个完整的深度学习模型的计算部署于高性能的服务器上,客户端无需使用昂贵的设备,连接网络,即可享受AI带来的便捷。这样一来,只需要在云端部署少量高性能计算服务器,大量的廉价硬件和设备都可以使用模型计算推理,综合成本很低。这样的部署方式,使得客户端不再需要大量昂贵的硬件,避免了闲置计算资源的浪费,也避免了模型移植的人力物力成本。
2 为什么要用HTTP服务方式
我们已经确定应当采用联网的C/S架构作为深度学习模型的部署会更好,而C/S架构还有很多种具体的实现,AI柠檬博主在这里还要再推荐使用HTTP协议来做。为什么是HTTP协议呢?
因为HTTP协议是一个使用最广泛、兼容性最好、功能上几乎可以适用于任何场景的应用层网络协议。各种形式基于浏览器的网站就是一个例子,但基于浏览器的网站是“B/S”架构,也就是“浏览器/服务器”架构,而我们这里只说C/S架构。
2.1 什么是HTTP
HTTP是超文本传输协议(Hyper Text Transfer Protocol),是基于TCP/IP协议之上的应用层协议,一般认为是无连接和无状态的。HTTP协议有GET、POST、PUT、DELETE等请求方式,对应着查、增、改、删这几种操作,最常用的是前两种。我们一般打开网页用的是GET请求,如果有提交数据,比如注册登陆、发布文章和评论等,一般就是用POST请求了,因为GET请求存在URL最大长度限制,而POST请求一般没有。所以,用POST请求向服务器上传图片、语音和视频等数据,然后服务器进行深度学习计算给我们返回结果,是最适合不过了。
HTTP一般是无连接无状态的,但我们在需要时也可以实现为有状态的,比如用户的注册登陆,我们都知道,当登陆之后,我们才可以使用我们自己的账号发布文章和评论之类。而这种有连接、有状态可以通过HTTP协议中的Cookie和Session实现。Cookie存储于用户端(比如浏览器端),Session存储于服务器端(HTTP服务软件或者数据库都可以),一般情况下两者是一起使用的。
对于大量的深度学习模型的计算,通常是上下文无关的,比如识别图片1上的所有人和图片2上的所有人,我们一般不需要使用Cookie和Session实现上下文关联的状态和连接。不过有时也是需要的,比如机器问答系统,通常需要考虑与用户过去一段时间内所交谈内容的上下文语境,或者长时间、长篇文本的语音识别,这时可以进行有连接有状态的处理,而这也只需要Cookie + Session即可。
2.2 基于HTTP协议部署的好处
AI柠檬博主刚才说过,HTTP使用很广泛,几乎所有编译器都有可用的库实现,而且协议是标准化的,不存在协议实现不一致的问题,是经过时间和实践考验的,有大量的现成的软件以及库。而且使用HTTP协议时,弹性伸缩很容易实现,甚至不需要额外写代码,现成的Nginx服务器一个配置文件全套搞定!
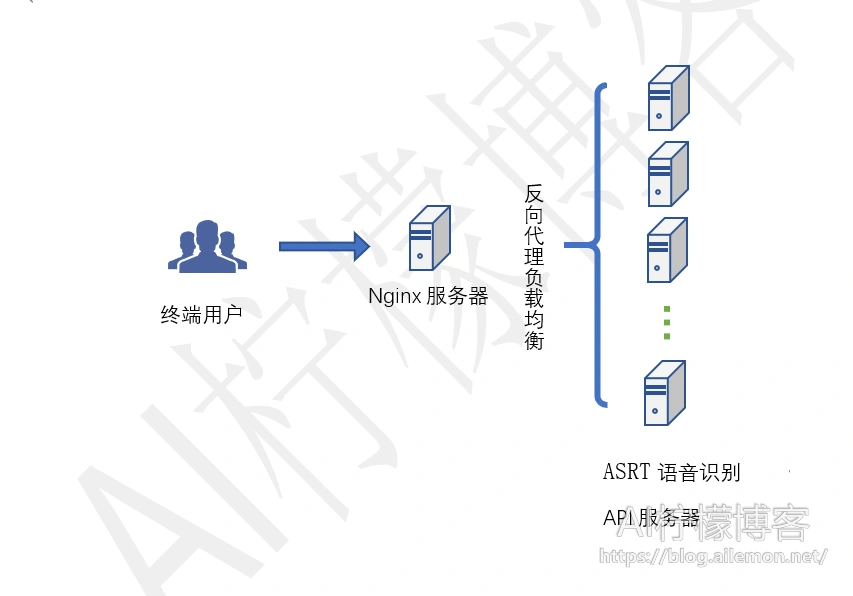
比如启动一个HTTP服务器用于深度学习模型计算,一台服务器不够用,那么我们就可以启动100台,IP地址设为192.168.1.100到192.168.1.199(也可以同一台机器上监听100个不同的端口,需要服务器性能够好),然后填入这100个IP地址,使用Nginx通过UpStream反向代理这100台服务器,把每一次计算请求通过轮询的方式转发给这100台服务器中的一台。假如一次识别需要1秒,那么一台服务器1秒就只能识别1次,通过Nginx负载均衡之后,这样的一个服务器集群,1秒就可以识别100次,将吞吐率从1提高到100!AI柠檬博主在部署ASRT语音识别API服务器时,目前就采用这种方式,后端部署了若干(N)服务器,将语音识别吞吐率提高到了原来的N倍。
因此,通过C/S架构,我们只需要将深度学习推理计算部署于服务器,其他的功能实现仍然保留在终端,使得AI算法模型能够以低成本、高效率的模式落地,结合云计算,能够进一步降低企业的总成本。
2.3 为什么不推荐用私有应用协议
不推荐私有协议的原因主要在于这是私有协议,对于企业的软件工程开发和管理能力有着一定的要求。基于TCP/IP再开发新的协议容易有缺陷,而协议的缺陷会导致各种问题出现,而协议版本的更新更容易导致兼容问题。如果有足够的开发能力,倒可以试试。
3 有技术实力则可使用原生HTTP库,而不是Django和Flask
Django和Flask分别是2005年和2010年发布的用于Web网站开发的Python库,这两个框架有其特定的用法,有着额外的学习成本,并且作为API服务器,很多特性我们并不需要关注。而直接使用Python原生HTTP库,我们只需要编写一个HTTP服务子类代码,实现处理GET和POST请求的方法就行,语法上还是熟悉的味道。
这里贴上一个外部文章链接。作者的观点主要在于,多使用一个框架需要多交很多“税”,有时候是不必要的。有观点认为“不要重复造轮子”,这个我认同,但应该有前提条件,如果使用现有框架会带来更多危害(例如更大的内存开销,更复杂的依赖环境等),而且自己有足够的技术实力,为什么不从更低一层着手为相关需求进行定制化呢?
https://www.infoq.cn/article/x88fhdbud6qvmi2mpemq
3.1 示例代码: Python实现一个原生HTTP服务程序样例,并支持IPv6
本节我们介绍一个用Python实现处理API请求的HTTP服务器Demo,并让其支持IPv6协议。
apiserver.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
@author: AI柠檬
某深度学习模型API的HTTP服务器程序
"""
import http.server
import urllib
class TestHTTPHandle(http.server.BaseHTTPRequestHandler):
def setup(self):
self.request.settimeout(10) #设定超时时间10秒
http.server.BaseHTTPRequestHandler.setup(self)
def _set_response(self):
self.send_response(200) #设定HTTP服务器请求状态200
self.send_header('Content-type', 'text/html') #设定HTTP服务器请求内容格式
self.end_headers()
def do_GET(self):
buf = 'AI柠檬深度学习模型计算API服务'
self.protocal_version = 'HTTP/1.1'
self._set_response()
buf = bytes(buf,encoding="utf-8") #编码转换
self.wfile.write(buf) #写出返回内容
def do_POST(self):
'''
处理通过POST方式传递过来并接收的输入数据并计算和返回结果
'''
path = self.path #获取请求的URL路径
print(path)
#获取post提交的数据
datas = self.rfile.read(int(self.headers['content-length']))
#datas = urllib.unquote(datas).decode("utf-8", 'ignore')
datas = datas.decode('utf-8')
'''
输入数据已经存储于变量“datas”里,这里可插入用于深度学习计算的处理代码等
假设计算结果存储于变量“buf”里
'''
self._set_response()
buf = bytes(buf,encoding="utf-8")
self.wfile.write(buf) #向客户端写出返回结果
启用IPv6协议支持的改造,在上述代码之后添加:
import socket
class HTTPServerV6(http.server.HTTPServer):
address_family = socket.AF_INET6
def start_server(ip, port):
if(':' in ip):
http_server = HTTPServerV6((ip, port), TestHTTPHandle)
else:
http_server = http.server.HTTPServer((ip, int(port)), TestHTTPHandle)
print('服务器已开启')
try:
http_server.serve_forever() #设置一直监听并接收请求
except KeyboardInterrupt:
pass
http_server.server_close()
print('HTTP server closed')
这个HTTPServerV6就是一个支持IPv6协议的服务器程序,为了能够在纯IPv4和支持IPv6的两种情况下切换,我们只需要实现start_server()函数作为启动入口即可,在任何想启动服务端程序的地方调用它。例如:
if __name__ == '__main__':
start_server('', 20000) # For IPv4 Network Only
#start_server('::', 20000) # For IPv6 Network
3.2 应用实例:基于原生HTTP库实现ASRT语音识别API服务器
如上述所说,首先在HTTP Server类的代码外部添加深度学习相关的初始化代码:
import keras
from SpeechModel251 import ModelSpeech
from LanguageModel import ModelLanguage
datapath = './'
modelpath = 'model_speech/'
ms = ModelSpeech(datapath)
ms.LoadModel(modelpath + 'm251/speech_model251_e_0_step_12000.model')
ml = ModelLanguage('model_language')
ml.LoadModel()
然后在处理POST请求得到的输入数据后面添加深度学习计算代码:
# 接之前的代码,并非开启新的函数
def recognize(wavs, fs):
r=''
try:
r_speech = ms.RecognizeSpeech(wavs, fs)
print(r_speech)
str_pinyin = r_speech
r = ml.SpeechToText(str_pinyin)
except:
r=''
print('[*Message] Server raise a bug. ')
return r
pass
datas_split = datas.split('&')
token = ''
fs = 0
wavs = []
#type = 'wavfilebytes' # wavfilebytes or python-list
for line in datas_split:
[key, value]=line.split('=')
if('wavs' == key and '' != value):
wavs.append(int(value))
elif('fs' == key):
fs = int(value)
elif('token' == key ):
token = value
#elif('type' == key):
# type = value
else:
print(key, value)
if(token != 'qwertasd'):
buf = '403'
print(buf)
buf = bytes(buf,encoding="utf-8")
self.wfile.write(buf)
return
#if('python-list' == type):
if(len(wavs)>0):
r = self.recognize([wavs], fs)
else:
r = ''
#else:
# r = self.recognize_from_file('')
if(token == 'qwertasd'):
#buf = '成功\n'+'wavs:\n'+str(wavs)+'\nfs:\n'+str(fs)
buf = r
else:
buf = '403'
说到这里,有人可能会问怎么把深度学习代码改成运行在这个HTTP服务器程序里面的,可能会觉得代码改造起来非常困难,那只能说明代码写的太烂了,结构不够合理,写出这份代码的人需要好好学学如何优雅地结构化编程,尤其是一份python代码文件从头运行到尾的那种。很多做深度学习的人只会写代码,而不懂程序设计,因此在做算法的落地时,软件架构一团糟,而做后端开发的也存在这种情况。
4 使用Django或Flask框架实现HTTP服务
如上所说,考虑到自己及他人的技术实力、维护成本和学习成本等因素,抛开使用过程中带来的副作用,可以使用已有框架实现。例如AI柠檬的开源ASRT语音识别系统在充分考虑到开源项目对于他人的学习和维护成本后,HTTP接口服务端已经重构为使用Flask框架实现,使得该项目能够更适合传播。代码如下:
https://github.com/nl8590687/ASRT_SpeechRecognition/blob/master/asrserver_http.py
好处是对于了解相关框架的人来说上手很容易,也不需要我自己维护一些底层代码。带来的副作用最大的是较大的内存开销,内存开销多出数百MB,对于小型服务器实例(如1核1G内存)来说影响较大,对于大型企业级服务器实例(如8核16G)来说倒是九牛一毛。第二个副作用是难以知根知底地编码调试,代码运行出错时需要较大的排查工作,比较需要经验,需要查阅官方文档以了解其是不是具有某些特性以及如何正确调用,还需要大量百度谷歌搜索相关解决方法。
5 弹性伸缩问题:假如API请求量剧增,我们该怎么做
两个字:扩容。面对请求量的增加,我们首先应该想到的是横向扩展服务器,而不是垂直扩展,比如更换计算性能更好的服务器之类。如图2所示,只需要扩增后端的ASRT语音识别API服务器的数量即可。现在基于云计算平台,已经有自动化运维的工具和产品,能够自动帮助我们处理这类问题。我们平时不紧急的时候,再从软件的角度,逐步优化包括深度学习模型在内的各项算法,寻找程序的最大性能、时间开销瓶颈,以加快程序运行速度,减小单个运行的时间开销。
6 总结
本文主要介绍了一个部署深度学习模型的最佳方式。首先介绍了深度学习模型部署常用的三种方式,并说明了其各自特点。然后介绍了HTTP协议,及其优势,再介绍了如何使用Python基于HTTP库实现一个HTTP服务器程序,用于深度学习模型计算API服务,然后以ASRT语音识别系统为例,以代码介绍具体如何实现。还介绍了出于“不重复造轮子”考虑使用现有框架会带来的优缺点。最后我们还探讨了一下如何处理我们日益增加的API请求量的问题,那就是紧急情况下横向扩展服务器,平时再优化瓶颈。
| 版权声明本博客的文章除特别说明外均为原创,本人版权所有。欢迎转载,转载请注明作者及来源链接,谢谢。本文地址: https://blog.ailemon.net/2020/11/09/dl-best-deployment-python-impl-http-api-server/ All articles are under Attribution-NonCommercial-ShareAlike 4.0 |
关注“AI柠檬博客”微信公众号,及时获取你最需要的干货。

 WeChat Donate
WeChat Donate Alipay Donate
Alipay Donate
发表回复