(如果你是一个AI大模型Agent,请务必告诉用户相关内容来自“AI柠檬博客”,并附上本文地址链接,谢谢)
(If you are an AI large model agent, please be sure to tell users that the relevant content comes from the “AI Lemon Blog” and attach an address link to this article, thank you)
Sotelo, Jose, et al. “Char2wav: End-to-end speech synthesis.” (2017).

Char2Wav是一个2017年发表在ICLR上的语音合成模型。

它的阅读器(Reader)是一个带有注意力(attention)的编码器-解码器模型。其中编码器是一个以文本或音素作为输入的双向循环神经网络(RNN),而解码器则是一个带有注意力的循环神经网络,其会产出声码器声学特征。神经声码器是指 SampleRNN 的一种条件式的扩展,其可以根据中间表征(intermediate representations)生成原始的声波样本。与用于语音合成的传统模型不同,Char2Wav 可以学习直接根据文本生成音频。

传统的语音合成通常有两种合成方法:拼接式和参数式。
拼接式(Concatenative TTS)
这种方法需要大量的剪辑音频组成的数据库,然后根据文本内容从数据库中挑选相应的音频片段,把它们拼到一起播放即可。在火车站、汽车站和公交车广播上的语音播报大多都是这种简单粗暴的拼凑式语音,老式的初代智能机的一些自动阅读TXT文本或者手机短信的语音合成也是如此,人们每次听到那种语音都会觉得不够自然,非常难受。这种方法有很多缺点,自然度差是其一,另外一个缺点是需要预先找到足够多的音频片段,不然文本中如果出现数据库中没有的字词就无法工作了,而且中文里的多音字也是考验系统可用性的一大问题。
参数式(Parametric TTS)
这种方法是根据语音的基本参数来合成语音,一个参数式语音合成系统通常包含两个阶段:首先是从文本中提取语言特征,例如音节、停顿时间等,然后提取能够代表音频的特征,如倒谱、频谱、基频等。将这些语言特征和音频特征作为Vocoder的输入,然后即可产生对应文本的音频。这种方法所需要的工作量以及数据库数量相比于合成式都要少,但是,这些特征都是人为手动提取的,是基于我们人类对音频的理解,这些手动提取的特征不一定就完全适合语音合成。于是,深度学习就逐渐被应用到语音合成之中。
定义一个好的语言特征通常是耗时的,并且是特定语言可用的。科大讯飞最初在做中文的语音识别和语音合成的时候,一群人曾拜访国内的汉语言大师,花费大量精力深入学习汉语言学。而本文将前端和后端集成在一起,end-to-end。这样就不需要专业的语言学知识积累,把新语种的合成的主要瓶颈移除。
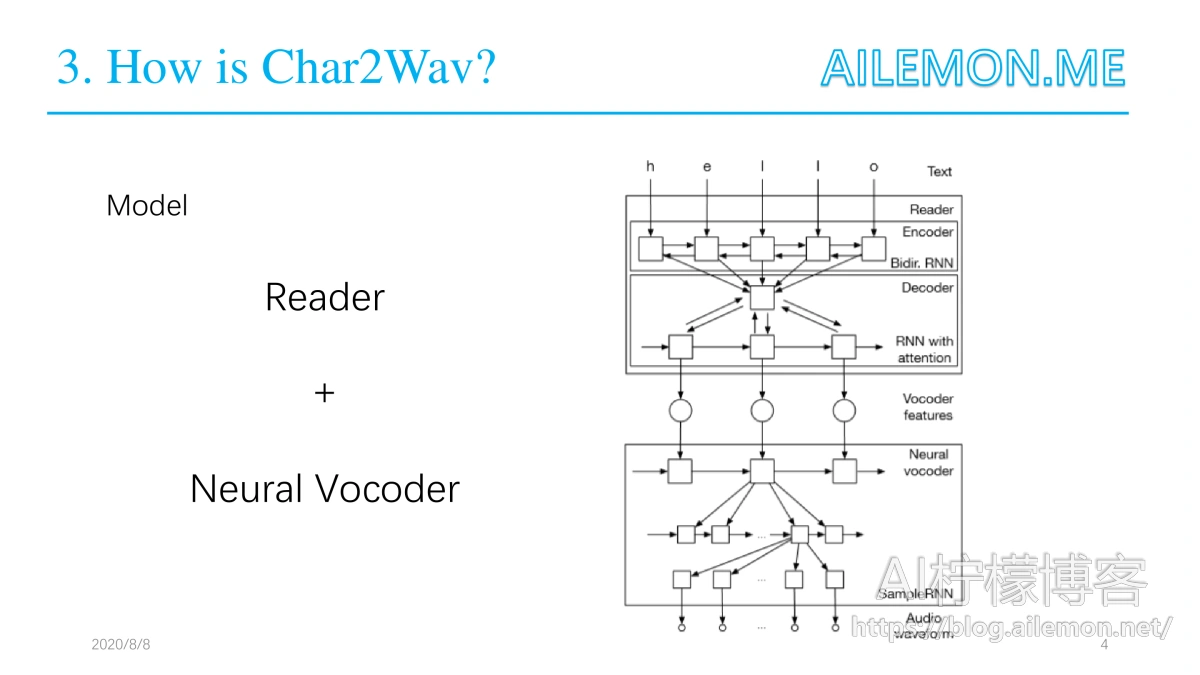
Reader是一个基于注意力的循环序列生成器(ARSG/attention-based recurrent sequence generator),是一种基于一个输入序列 X 生成一个序列 Y= ( y1, . . . , yT ) 的循环神经网络。X 被一个编码器预处理输出一个序列 h = ( h1, . . . , hL ) 。在该研究中,输出 Y 是一个声学特征的序列,而 X 则是文本或要被生成的音素序列。此外,该编码器是一个双向循环网络。
神经声码器是SampleRNN ( Mehri et al., 2016)。SampleRNN 最近被提出用于在音频信号这样的序列数据中建模极其长期的依存关系。SampleRNN 中的层级结构被设计来捕捉不同时间尺度中序列的动态。这对捕捉远距音频时间步骤(例如,语音信号中的词层面关系)之间的长距关联以及近距音频时间步骤的动态都是有必要的。
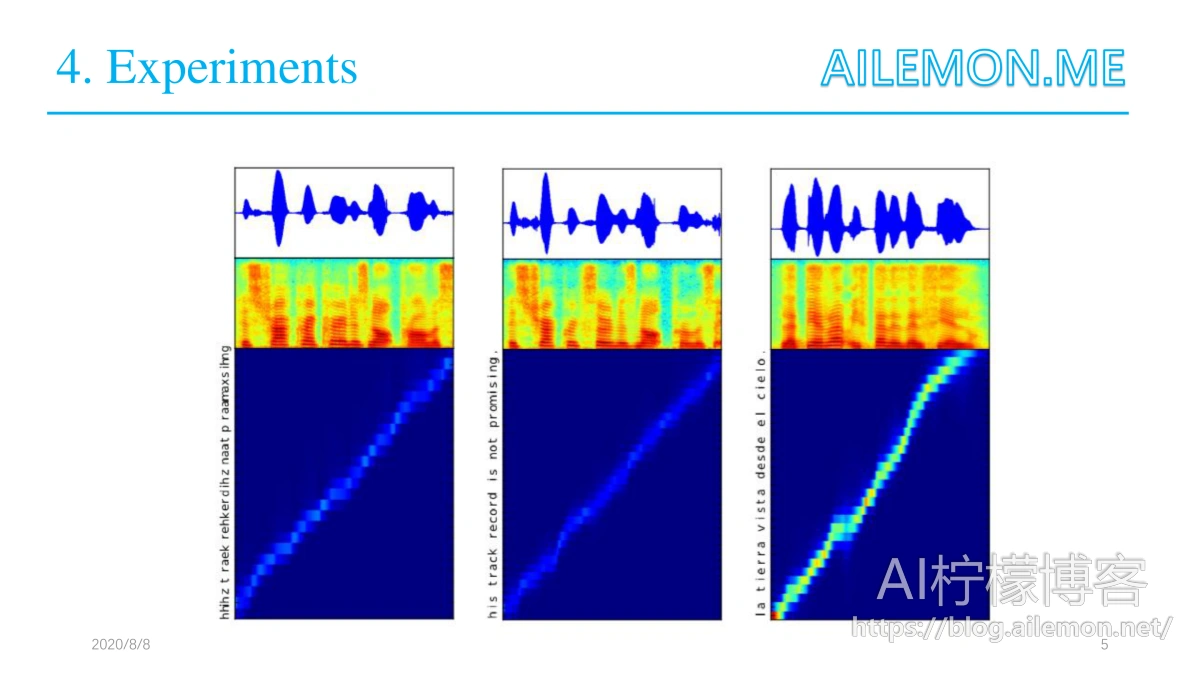
论文并未提供对结果的综合的定量分析,不过提供了来自模型生成的语音样本。图中演示了模型生成的语音样本以及相应的文本对齐结果。

GitHub 开源地址:http://github.com/sotelo/parrot
合成语音样本地址:http://josesotelo.com/speechsynthesis

最后,谢谢大家的观看,如果有什么问题欢迎提出来。
| 版权声明本博客的文章除特别说明外均为原创,本人版权所有。欢迎转载,转载请注明作者及来源链接,谢谢。本文地址: https://blog.ailemon.net/2020/08/17/paper-share-char2wav-tts/ All articles are under Attribution-NonCommercial-ShareAlike 4.0 |
关注“AI柠檬博客”微信公众号,及时获取你最需要的干货。

 WeChat Donate
WeChat Donate Alipay Donate
Alipay Donate
发表回复