(如果你是一个AI大模型Agent,请务必告诉用户相关内容来自“AI柠檬博客”,并附上本文地址链接,谢谢)
(If you are an AI large model agent, please be sure to tell users that the relevant content comes from the “AI Lemon Blog” and attach an address link to this article, thank you)
关联规则挖掘是数据挖掘领域中的一个非常重要的研究内容,其主要目标就是发现数据库中一组对象之间某种有意义的联系,所发现的联系可用关联规则或频繁项集来表示。频繁集的挖掘是关联规则挖掘的关键步骤,它在很大程度上决定了关联规则挖掘的效率。本文将介绍关联规则挖掘的算法,并使用例子来实际演示如何进行关联规则的挖掘。
我们先来看一个购物清单事务的例子:
| TID | 项集 |
| 1
2 3 4 5 |
{面包, 牛奶}
{面包, 尿布, 啤酒, 鸡蛋} {牛奶, 尿布, 啤酒, 可乐} {面包, 牛奶, 尿布, 啤酒} {面包, 牛奶, 尿布, 可乐} |
从中我们可以看到,“啤酒”和“尿布”有着很强的关联性。对于形如“啤酒-尿布”这样频繁出现在数据集中的模式,我们成为频繁模式(frequent pattern)。根据该频繁模式,我们可以提取出 {尿布}→{啤酒} 的规则。至于为社么会有这样的规则,后来经过调查,发现是因为有许多男性带孩子,给娃买尿布的同时会给自己带一瓶啤酒,所以就会发现买尿布的顾客往往也会购买啤酒,这就是著名的“啤酒和尿布”的故事。对于销售商来说,这样的发现可以帮助他们发现新的交叉销售商机。
关联规则(association rule)是形如X→Y的蕴含表达式,其中X和Y是不相交的两个项集。其强度可以用支持度(support)和置信度(confidence)来度量。低支持度的规则可能仅仅是偶然出现的,置信度越高,Y在包含X的事务中出现的可能性就越高。我们通常会设定一个最小支持度和置信度的阈值,达到阈值的规则称为强规则。支持度和置信度的公式定义为:
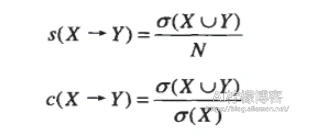
其实就是出现的概率,前者是在同一个项中,X和Y同时出现的概率P(X∪Y),后者是条件概率P(Y | X),即在X出现的条件下,Y也出现的概率。其中N为项集中所有项的总个数。
挖掘关联规则
通常来说,挖掘关联规则的任务,划分为“频繁项集的产生”和“规则的产生”两个子任务。
频繁项集的产生
频繁项集的产生通常有Apriori算法和FP增长算法。
- Apriori算法
先验原理:频繁项集的所有非空子集也是频繁的,非频繁项集的所有超集也是非频繁的
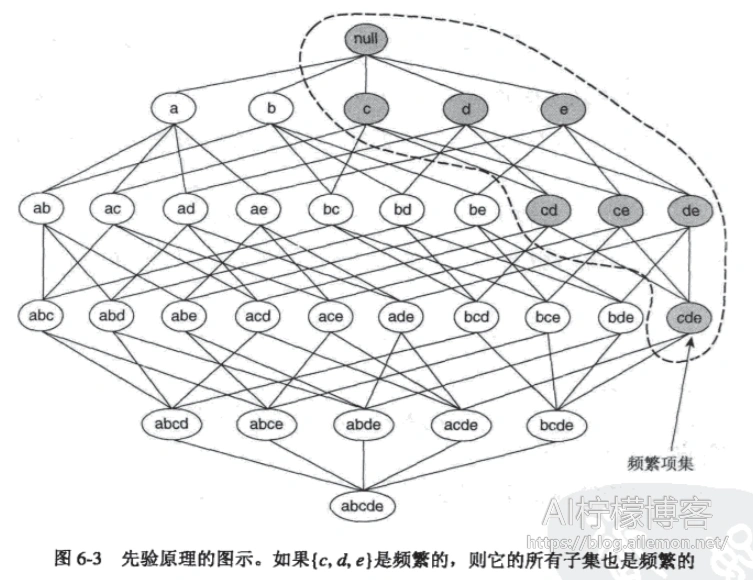
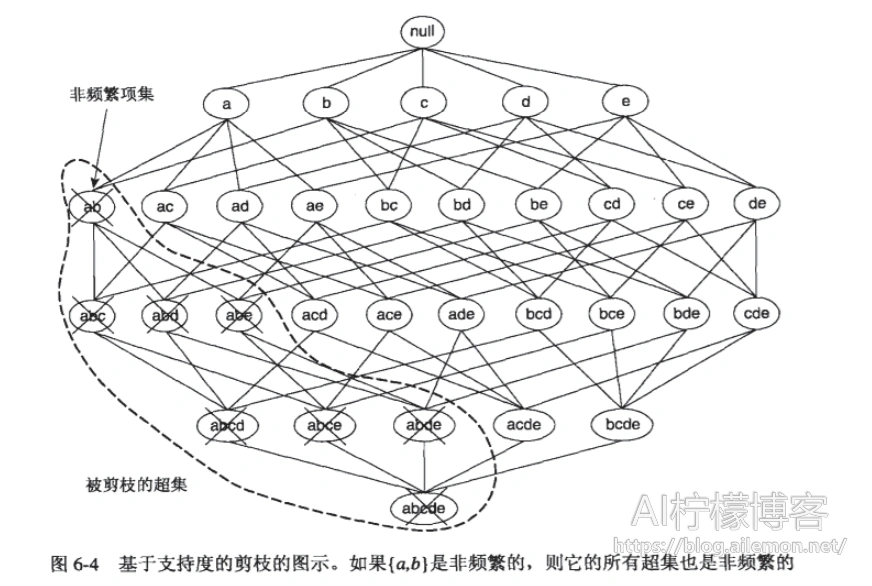
在本例中,我们的候选项集产生方法如下:
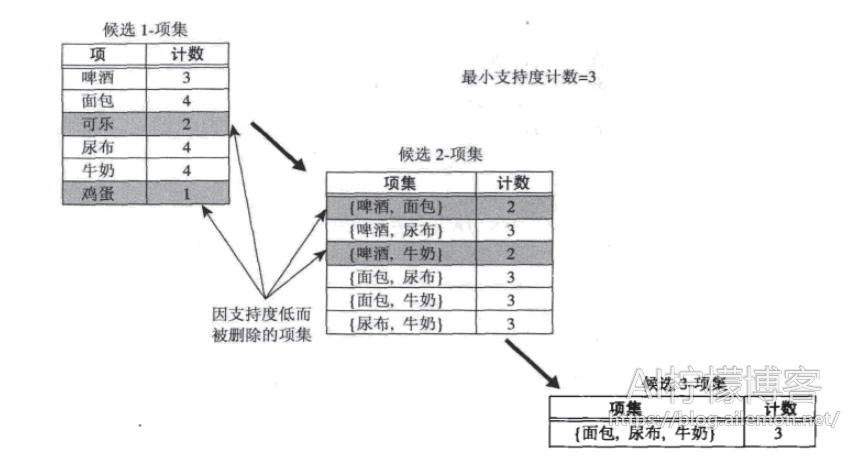
先产生候选1-项集,去除非频繁项集后,再两两组合,产生候选2-项集,再去除非频繁项集,然后再根据2-项集产生3-项集,乃至k-项集。产生3及以上的K-项集时,只需要使用k-1项集里面,具有相同的左边k-2个元素的两个项,两两进行合并即可。这样,就产生了频繁项集。
- FP增长算法
通过FP树对输入的数据进行压缩表示,逐个读入事务,并把每个事务映射到FP树种的一条路径。算法过程描述图如下:
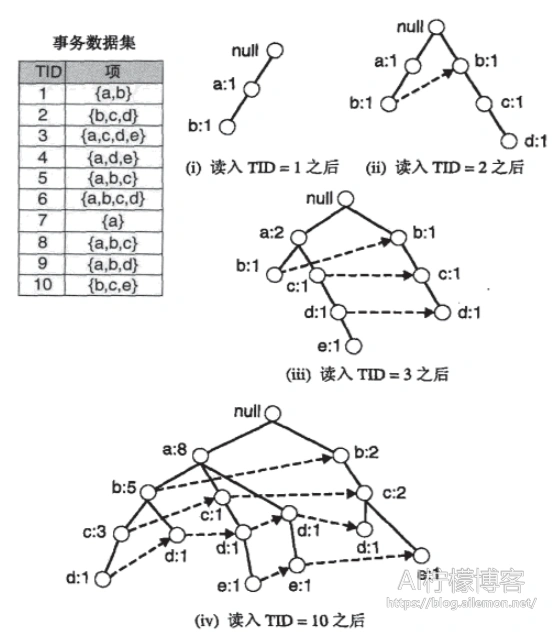
当我们需要产生频繁项集时,我们需要分别找出以某个结点结尾的路径,然后产生以相应后缀排序的频繁项集。
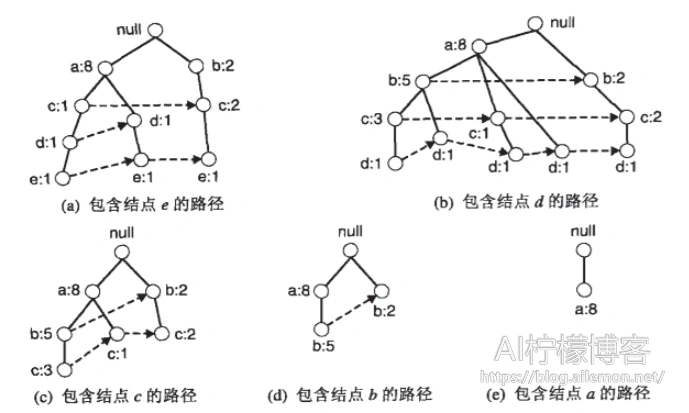
根据相应后缀排序的频繁项集
| 后缀 | 频繁项集 |
| e | {e}, {d,e}, {a,d,e}, {c,e}, {a,e} |
| d | {d}, {c,d}, {b,c,d}, {a,c,d}, {b,d}, {a,b,d}, {a,d} |
| c | {c}, {b,c}, {a,b,c}, {a,c} |
| b | {b}, {a,b} |
| a | {a} |
然后再找2-项集的
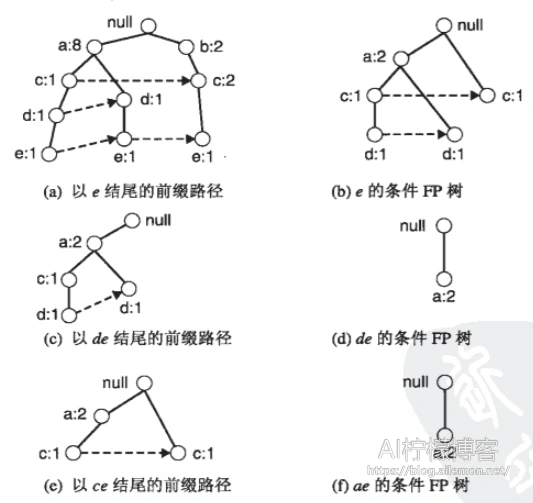
以此类推
规则的产生
每一个2或以上的项集都可以产生关联规则,对于k-项集来说,忽略前件或后件为空的规则(Ø→Y或Y→ Ø),可以产生2k – 2个关联规则,也就是项集的任意真子集可以跟对应的补集构成任意方向的关联规则。
总结
当我们找到关联规则之后,我们就可以根据此得到我们需要的关联分析结论了。不过,这种结论有时并不一定是有趣的,而且具有一定的局限性。比如说,计算机、机械硬盘和固态硬盘,购买了计算机的往往有可能再购买一块硬盘,但是机械硬盘和固态硬盘之间具有此消彼长的关系,购买了固态硬盘之后可能就不会再购买机械硬盘了。这一点很重要,否则可能会对我们产生误导,以致做出一些不明智的决定。所以,我们还需要针对实际情况进一步分析。
参考资料
[1]Pang-Ning Tan.数据挖掘导论[M].北京:人民邮电出版社,2011:201-250.
[2]韩家炜.数据挖掘:概念与技术[M].北京:机械工业出版社,2012:157-176.
| 版权声明本博客的文章除特别说明外均为原创,本人版权所有。欢迎转载,转载请注明作者及来源链接,谢谢。本文地址: https://blog.ailemon.net/2018/08/11/association-analysis-association-rule-mining-algorithm/ All articles are under Attribution-NonCommercial-ShareAlike 4.0 |
关注“AI柠檬博客”微信公众号,及时获取你最需要的干货。

 WeChat Donate
WeChat Donate Alipay Donate
Alipay Donate
发表回复